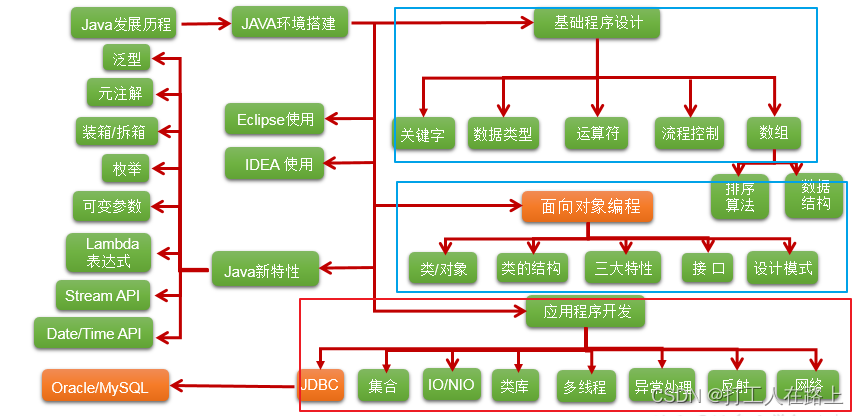
1概述
面向对象性:
两个要素:类、对象
三个特征:封装、继承、多态
健壮性:① 去除了C语言中的指针 ②自动的垃圾回收机制 –>仍然会出现内存溢出、内存泄漏
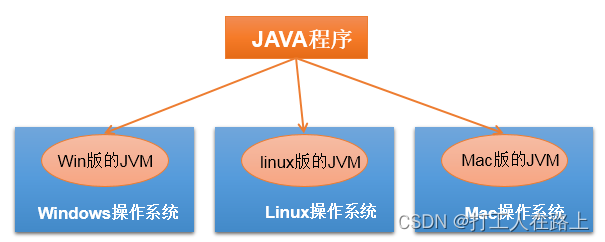
跨平台型:write once,run anywhere:一次编译,到处运行
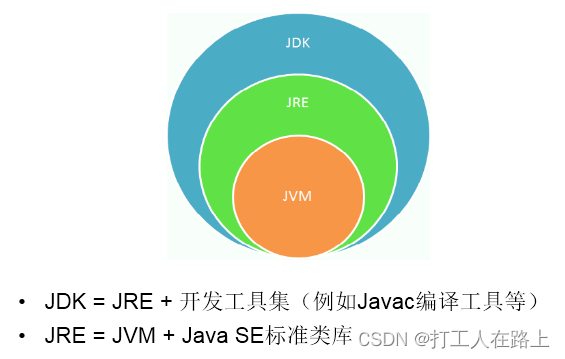
功劳归功于:JVM
编译语句: javac xxx
运行 java xxx
2.变量的分类
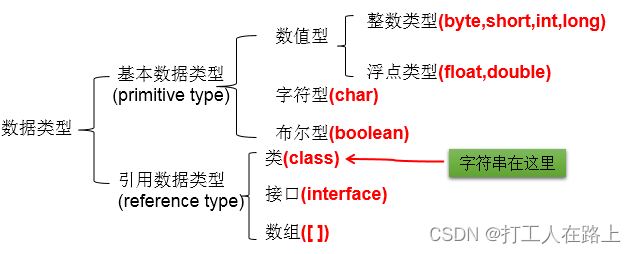
byte(1字节=8bit) \ short(2字节) \ int(4字节) \ long(8字节)
声明long型变量,必须以”l”或”L”结尾
浮点型:float(4字节) \ double(8字节) 定义float类型变量时,变量要以”f”或”F”结尾
自动类型转换 :当容量小的数据类型的变量与容量大的数据类型的变量做运算时,结果自动提升为容量大的数据类型
byte 、char 、short –> int –> long –> float –> double
特别的:当byte、char、short三种类型的变量做运算时,结果为int型
instanceof 判断 a 是后是b类型 用于多态的强制类型转换
3.逻辑运算符
区分& 与 &&:当符号左边是false时,&继续执行符号右边的运算。&&不再执行符号右边的运算。
区分:| 与 || :当符号左边是true时,|继续执行符号右边的运算,而||不再执行符号右边的运算
4.流程控制语句

switch(表达式){
case 整型数值1: 语句 1;
case 整型数值2: 语句 2;
......
case 整型数值n: 语句 n;
default: 语句 n+1;
}

6.数组
数组(Array),是多个相同类型数据一定顺序排列的集合,并使用一个名字命名
数组属于引用数据类型的变量。
创建数组对象会在内存中开辟一整块连续的空间
数组的长度一旦确定,就不能修改。
一维数组元素的默认初始化值
> 数组元素是整型:0
* > 数组元素是浮点型:0.0
* > 数组元素是char型:0或'\u0000',而非'0'
* > 数组元素是boolean型:false
*
* > 数组元素是引用数据类型:null
int ids = new int[]{1001,1002,1003,1004};
int[] arr4 = {1,2,3,4,5};//类型推断
7.面向对象
- 1.Java类及类的成员:属性、方法、构造器;代码块、内部类
- 2.面向对象的大特征:封装性、继承性、多态性、(抽象性
1.面向过程:强调的是功能行为,以函数为最小单位,考虑怎么做。
2.面向对象:强调具备了功能的对象,以类/对象为最小单位,考虑谁来做。
类:对一类事物的描述,是抽象的、概念上的定义
对象:是实际存在的该类事物的每个个体,因而也称为实例(instance)
面向对象程序设计的重点是类的设计
设计类,就是设计类的成员。
7.1 属性:
- 属性 = 成员变量 = field = 域、字段
- 方法 = 成员方法 = 函数 = method
- 创建类的对象 = 类的实例化 = 实例化类
属性: 常用的权限修饰符:private、public、缺省、protected —>封装性
属性:加载到堆空间中 (非static)
局部变量:加载到栈空间
return关键字:
1.使用范围:使用在方法体中
2.作用:① 结束方法
-
② 针对于返回值类型的方法,使用"return 数据"方法返回所要的数据。
3.注意点:return关键字后面不可以声明执行语句。
7.2 方法:
方法的重载: 在同一个类中,允许存在一个以上的同名方法,只要它们的参数个数或者参数类型不同即可。
可变形参: jdk 5.0新增的内容
- 2.具体使用:
- 2.1 可变个数形参的格式:数据类型 … 变量名
- 2.2 当调用可变个数形参的方法时,传入的参数个数可以是:0个,1个,2个,。。。
- 2.3 可变个数形参的方法与本类中方法名相同,形参不同的方法之间构成重载
- 2.4 可变个数形参的方法与本类中方法名相同,形参类型也相同的数组之间不构成重载。换句话说,二者不能共存。
- 2.5 可变个数形参在方法的形参中,必须声明在末尾
- 2.6 可变个数形参在方法的形参中,最多只能声明一个可变形参。
1.构造器(或构造方法):Constructor
构造器的作用:
- 1.创建对象
- 2.初始化对象的信息
2.使用说明: - 1.如果没显式的定义类的构造器的话,则系统默认提供一个空参的构造器
- 2.定义构造器的格式:权限修饰符 类名(形参列表){}
- 3.一个类中定义的多个构造器,彼此构成重载
- 4.一旦我们显式的定义了类的构造器之后,系统就不再提供默认的空参构造器
- 5.一个类中,至少会有一个构造器。
this理解为:当前对象 或 当前正在创建的对象
8.封装性
1.为什么要引入封装性?
我们程序设计追求**“高内聚,低耦合”。**
高内聚 :类的内部数据操作细节自己完成,不允许外部干涉;
低耦合 :仅对外暴露少量的方法用于使用。
隐藏对象内部的复杂性,只对外公开简单的接口。便于外界调用,从而提高系统的可扩展性、可维护性。通俗的说,把该隐藏的隐藏起来,该暴露的暴露出来。这就是封装性的设计思想。
体现:
体现一:将类的属性xxx私化(private),同时,提供公共的(public)方法来获取(getXxx)和设置(setXxx)此属性的值
体现二:不对外暴露的私有的方法
体现三:单例模式(将构造器私有化)
体现四:如果不希望类在包外被调用,可以将类设置为缺省的。
private < 缺省 < protected < public
4种权限都可以用来修饰类的内部结构:属性、方法、构造器、内部类
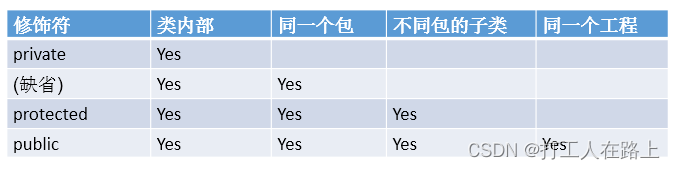
修饰类的话,只能使用:缺省、public
8.单继承性(extends)
1.为什么要有类的继承性?(继承性的好处)
- ① 减少了代码的冗余,提高了代码的复用性
- ② 便于功能的扩展
- ③ 为之后多态性的使用,提供了前提
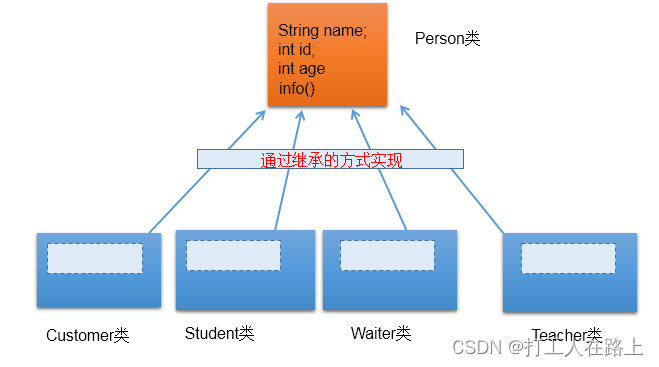
子类A中就获取了父类B中声明的所有的属性和方法 。
父类中声明为private的属性或方法,子类继承父类以后,仍然认为获取了父类中私的结构。只因为封装性的影响,使得子类不能直接调用父类的结构而已。
override:子类继承父类以后,可以对父类中同名同参数的方法,进行覆盖操作.
重写的规则:
① 子类重写的方法的方法名和形参列表与父类被重写的方法的方法名和形参列表相同
② 子类重写的方法的权限修饰符不小于父类被重写的方法的权限修饰符
区分方法的重写和重载?
重载:不表现为多态性。 早绑定
重写:表现为多态性。 运行才确定调用的那个方法
重载,是指允许存在多个同名方法,而这些方法的参数不同。编译器根据方法不同的参数表,对同名方法的名称做修饰。对于编译器而言,这些同名方法就成了不同的方法。它们的调用地址在编译期就绑定了。Java的重载是可以包括父类和子类的,即子类可以重载父类的同名不同参数的方法。
所以:对于重载而言,在方法调用之前,编译器就已经确定了所要调用的方法,这称为“早绑定”或“静态绑定”;
而对于多态,只等到方法调用的那一刻,解释运行器才会确定所要调用的具体方法,这称为**“晚绑定”或“动态绑定”**。
引用一句Bruce Eckel的话:“不要犯傻,如果它不是晚绑定,它就不是多态。”
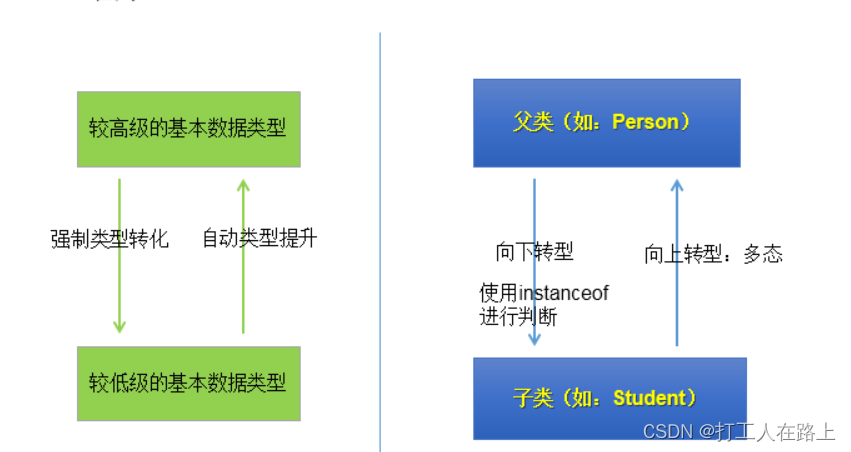
8.多态性(父在左边,子在右边)
对象的多态性:父类的引用指向子类的对象(或子类的对象赋给父类的引用)
调用的方法:编译,看左边;运行,看右边
调用的属性编译和运行,看左边
有了对象的多态性以后,我们在编译期,只能调用父类中声明的方法,但在运行期,我们实际执行的是子类重写父类的方法。
> 总结:编译,看左边;运行,看右边。
对象的多态性,只适用于方法,不适用于属性(编译和运行都看左边)
向上转型:多态
有了对象的多态性以后,内存中实际上是加载了子类特有的属性和方法的,但是由于变量声明为父类类型,导致编译时,只能调用父类中声明的属性和方法。子类特有的属性和方法不能调用。如何才能调用子类特的属性和方法?使用向下转型。instanceof
Object类中定义的equals()和==的作用是相同的:比较两个对象的地址值是否相同.即两个引用是否指向同一个对象实体
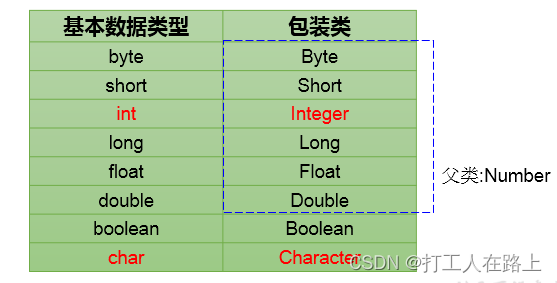
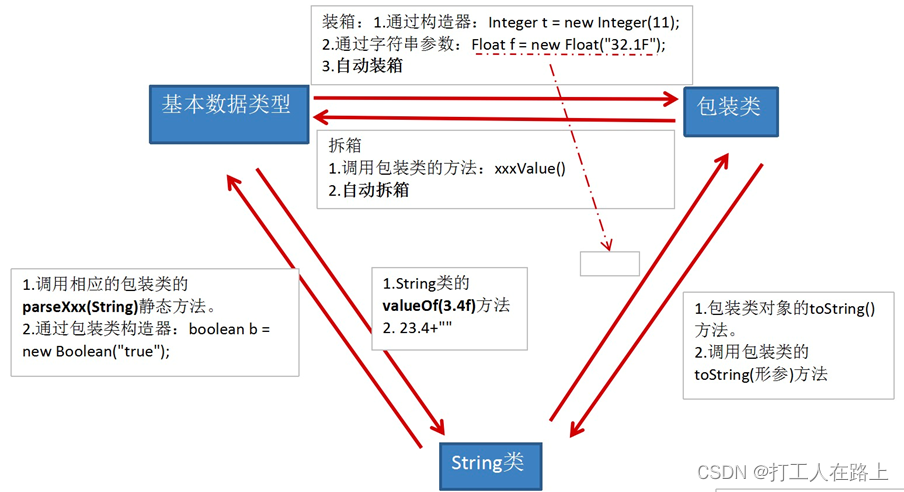
9.包装类
包装类:为了使基本数据类型的变量具有类的特征,引入包装类。
10.static finnal abstact关键字
修饰类的内部结构:属性、方法、代码块、内部类
静态属性 vs 非静态属性:
实例变量:我们创建了类的多个对象,每个对象都独立的拥一套类中的非静态属性。当修改其中一个对象中的非静态属性时,不会导致其他对象中同样的属性值的修改。
静态变量:我们创建了类的多个对象,多个对象共享同一个静态变量。当通过某一个对象修改静态变量时,会导致其他对象调用此静态变量时,是修改过了的
① 静态变量随着类的加载而加载。可以通过”类.静态变量”的方式进行调用
② 静态变量的加载要早于对象的创建。
在静态的方法内,不能使用this关键字、super关键字
栈:局部变量
堆:new出来的对象,数组
方法区域:类的加载信息,静态域,常量池
main方法的例子
1.main()方法作为程序的入口
public static void main(String[] args){//方法体}
权限修饰符:private 缺省 protected pubilc —->封装性
修饰符:static \ final \ abstract \native 可以用来修饰方法
返回值类型: 无返回值 / 有返回值 –>return
方法名:需要满足标识符命名的规则、规范;“见名知意”
形参列表:重载 vs 重写;参数的值传递机制;体现对象的多态性
方法体:来体现方法的功能
final关键字
可以用来修饰:类、方法、变量
- final 用来修饰一个类:此类不能被其他类所继承例如String类、System类、StringBuffer类
- final 用来修饰方法:表明此方法不可以被重写
- final 用来修饰变量:此时的**”变量”就称为是一个常量**
static final 用来修饰属性:全局常量
abstract: 抽象的 修饰:类、方法
abstract修饰类:抽象类
-
> **此类不能实例化** -
> **抽象类中一定有构造器**,便于子类实例化时调用(涉及:子类对象实例化的全过程) -
> 开发中,都会提供抽象类的子类,让**子类对象实例化**,完成相关的操作 --->抽象的使用**前提:继承性**
abstract修饰方法:抽象方法
-
> 抽象方法**只方法的声明,没方法体** -
> 包含抽象方法的类,一定是一个**抽象类**。反之,抽象类中可以没有抽象方法的。 -
> 若子类重写了父类中的所的抽象方法后,此子类方可实例化 -
>若子类没重写父类中的所的抽象方法,则此子类也是一个抽象类,需要使用abstract修
abstract不能用来修饰:属性、构造器等结构
abstract不能用来修饰私方法、静态方法、final的方法、final的类
11.单例模式
设计模式是在大量的实践中总结和理论化之后优的代码结构、编程风格、以及解决问题的思考方式。
单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例。
饿汉式1:
class Bank{
//1.私化类的构造器
private Bank(){
}
//2.内部创建类的对象
//4.要求此对象也必须声明为静态的
private static Bank instance = new Bank();
//3.提供公共的静态的方法,返回类的对象
public static Bank getInstance(){
return instance;
}
}
懒汉式:
class Order{
//1.私化类的构造器
private Order(){
}
//2.声明当前类对象,没初始化
//4.此对象也必须声明为static的
private static Order instance = null;
//3.声明public、static的返回当前类对象的方法
public static Order getInstance(){
synchronized (Bank.class) {
if(instance == null){
instance = new Bank();
}
return instance;
}
}
12.代码块
静态代码块: 随着类的加载而执行,而且只执行一次,按照声明的先后顺序执行
静态代码块内只能调用静态的属性、静态的方法,不能调用非静态的结构
非静态代码块:随着对象的创建而执行,多次执行(存在多个对象的话)
每创建一个对象,就执行一次非静态代码块
非静态代码块内可以调用静态的属性、静态的方法,或非静态的属性、非静态的方法
由父及子,静态先行。
13.接口interface
-
1.接口使用interface来定义
-
2.Java中,接口和类是并列的两个结构
-
3.如何定义接口:定义接口中的成员
-
>全局常量:**public static final(默认接口就是)**的.但是书写时,可以省略不写 -
>抽象方法:public abstract(默认就是) -
3.2 JDK8:除了定义全局常量和抽象方法之外,还可以定义静态方法、默认方法(略
接口中不能定义构造器的!意味着接口不可以实例化
- Java开发中,接口通过让类去实现(implements)的方式来使用.
- 如果实现类覆盖了接口中的所抽象方法,则此实现类就可以实例化
- 如果实现类没覆盖接口中所的抽象方法,则此实现类仍为一个抽象类
- Java类可以实现多个接口 —>弥补了Java单继承性的局限性
- 格式:class AA extends BB implements CC,DD,EE
7. 接口与接口之间可以继承,而且可以多继承
-
- 接口的具体使用**,体现多态性**
-
- 接口,实际上可以看做是一种规范
Java8中关于接口的新规范
1:接口中定义的静态方法,只能通过接口来调用。
2:通过实现类的对象,可以调用接口中的默认方法。
3:如果子类(或实现类)继承的父类和实现的接口中声明了同名同参数的默认方法,那么子类在没重写此方法的情况下,默认调用的是父类中的同名同参数的方法。–>类优先原则
4:如果实现类实现了多个接口,而这多个接口中定义了同名同参数的默认方法,那么在实现类没重写此方法的情况下,报错。–>接口冲突。这就需要我们必须在实现类中重写此方法
5:在子类(或实现类)的方法中调用父类、接口中被重写的方法 super.xxx().
抽象类和接口的异同?
相同点:不能实例化;都可以包含抽象方法的。
不同点: 1)把抽象类和接口(java7,java8,java9)的定义、内部结构解释说明
2)类:单继承性 接口:多继承 类与接口:多实现
14.内部类
Java中允许将一个类A声明在另一个类B中,则类A就是内部类,类B称为外部类.
成员内部类(静态、非静态 ) vs 局部内部类(方法内、代码块内、构造器内)
一方面,作为外部类的成员:
-
>调用外部类的结构 -
>可以被static修饰 -
>可以被4种不同的权限修饰
另一方面,作为一个类:
-
> 类内可以**定义属性、方法、构造器等** -
> 可以被**final修饰,表示此类不能被继承**。言外之意,不使用final,就可以被继承 -
> 可以被**abstract修饰**
//创建内部类
Person p = new Person();
Person.Bird bird = p.new Bird();
14.异常
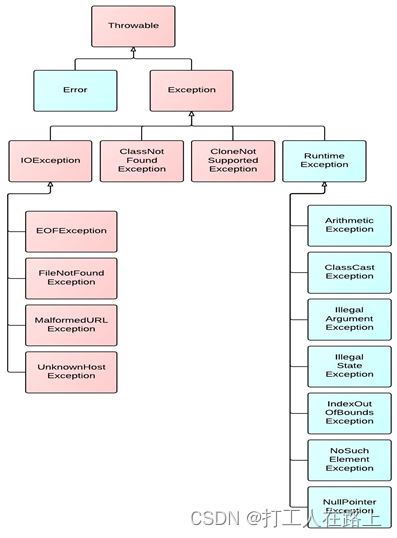
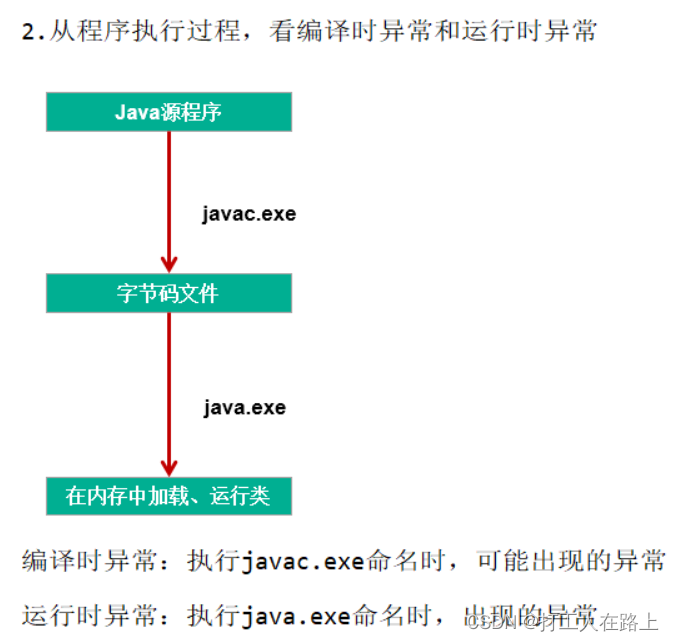
过程一:“抛”:程序在正常执行的过程中,一旦出现异常,就会在异常代码处生成一个对应异常类的对象。
-
并将此对象抛出。 -
**一旦抛出对象以后,其后的代码就不再执行。** -
关于异常对象的产生:① 系统自动生成的异常对象 ② 手动的生成一个异常对象,并抛出(throw)
过程二:“抓”:可以理解为异常的处理方式:① try-catch-finally ② throws
处理的方法 ① String getMessage() ② printStackTrace()
try-catch-finally:真正的将异常给处理掉了。
throws的方式只是将异常抛给了方法的调用者。并没真正将异常处理掉
子类重写的方法抛出的异常类型不大于父类被重写的方法抛出的异常类型 也就是父类没有抛 子类也不能抛
手动的throw一个异常类的对象。
throw “抛出”是一个异常对象 和 throws 是处理(继续抛出到调用其的方法上)一个异常对象 区别:
throw 表示抛出一个异常类的对象,生成异常对象的过程。声明在方法体内。
throws 属于异常处理的一种方式,声明在方法的声明处。
如何自定义异常类?
-
- 继承于现的异常结构:RuntimeException 、Exception
-
- 提供全局常量:serialVersionUID
-
- 提供重载的构造器
15.多线程与线程同步
程序(programm):是为完成特定任务、用某种语言编写的一组指令的集合。即指一段静态的代码。
进程(process)::程序的一次执行过程,或是正在运行的一个程序。:进程作为资源分配的单位,系统在运行时会为每个进程分配不同的内存区域
线程(thread):进程可进一步细化为线程**,是一个程序内部的一条执行路径**。线程作为调度和执行的单位,每个线程拥独立的运行栈和程序计数器(pc),线程切换的开销小
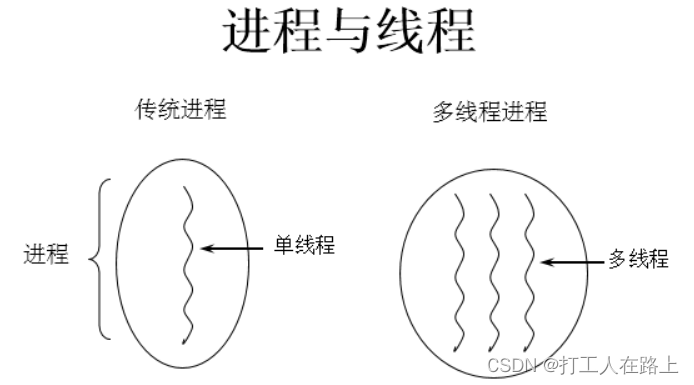
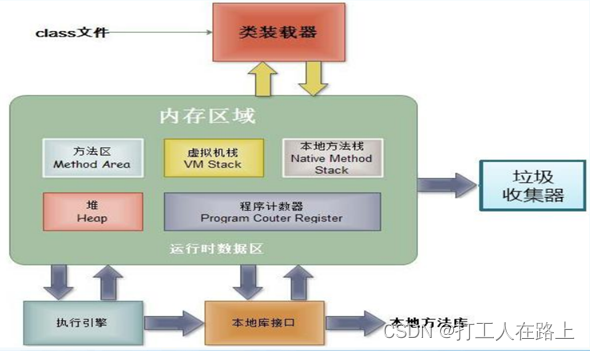
进程可以细化为多个线程。
每个线程,拥有自己独立的:栈、程序计数器
多个线程,共享同一个进程中的结构:方法区、堆。
单核CPU与多核CPU的理解
单核CPU,其实是一种假的多线程,因为在一个时间单元内,也只能执行一个线程的任务。
如果是多核的话,才能更好的发挥多线程的效率。(现在的服务器都是多核的)
一个Java应用程序java.exe,其实至少三个线程:main()主线程,gc()垃圾回收线程,异常处理线程。当然如果发生异常,会影响主线程。
并行:多个CPU 同时执 行多个任务。比如:多个人同时做不同的事。
并发:一个CPU (采用时间片) 同时执行多个任务。比如:秒杀、多个人做同一件事
多线程的方法
方式一:继承Thread类的方式:
-
- 创建一个继承于Thread类的子类
-
- 重写Thread类的run() –>将此线程执行的操作声明在run()中
-
- 创建Thread类的子类的对象
-
- 通过此对象调用start():①启动当前线程 ② 调用当前线程的run()
方式二:实现Runnable接口的方式:
-
- 创建一个实现了Runnable接口的类
-
- 实现类去实现Runnable中的抽象方法:run()
-
- 创建实现类的对象
-
- 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
-
- 通过Thread类的对象调用start()
两种方式的对比:
Runnable接口的方式
- 通过Thread类的对象调用start()
-
1. 实现的方式没类的单继承性的局限性 -
2. 实现的方式更适合来处理多个线程共享数据的情况。 - 联系:public class Thread implements Runnable
- 相同点:两种方式都需要重写run(),将线程要执行的逻辑声明在run()中。
目前两种方式,要想启动线程,都是调用的Thread类中的start()。
Thread类中的常用的方法:
- yield():释放当前cpu的执行权
- join():在线程a中调用线程b的join(),此时线程a就进入阻塞状态,直到线程b完全执行完以后,线程a才结束阻塞状态。
同步机制
方式一:同步代码块
补充:在实现Runnable接口创建多线程的方式中,我们可以考虑使用this充当同步监视器。
在继承Thread类创建多线程的方式中,慎用this充当同步监视器,考虑使用当前类充当同步监视器。
synchronized(同步监视器){
//需要被同步的代码
}
* 说明:1.操作共享数据的代码,即为需要被同步的代码。 -->不能包含代码多了,也不能包含代码少了。
* 2.共享数据:多个线程共同操作的变量。
* 3.同步监视器,俗称:锁。任何一个类的对象,都可以充当锁。
* 要求:多个线程必须要共用同一把锁。
- 关于同步方法的总结:
-
- 同步方法仍然涉及到同步监视器,只是不需要我们显式的声明。
-
- 非静态的同步方法,同步监视器是:this
-
静态的同步方法,同步监视器是:当前类本身
private ReentrantLock reentrantLock = new ReentrantLock();
1. 面试题:synchronized 与 Lock的异同?
- 相同:二者都可以解决线程安全问题
- 不同:synchronized机制在执行完相应的同步代码以后,自动的释放同步监视器
-
Lock需要手动的启动同步(lock(),同时结束同步也需要手动的实现(unlock())
15.线程通信
1.线程通信涉及到的三个方法:
- wait():一旦执行此方法,当前线程就进入阻塞状态,并释放同步监视器。
- **notify()😗*一旦执行此方法,就会唤醒被wait的一个线程。如果有多个线程被wait,就唤醒优先级高的那个。
- **notifyAll()😗*一旦执行此方法,就会唤醒所有被wait的线程。
2.说明: - 1.wait(),notify(),notifyAll()三个方法必须使用在同步代码块或同步方法中。
- 2.wait(),notify(),notifyAll()三个方法的调用者必须是同步代码块或同步方法中的同步监视器。
- 否则,会出现IllegalMonitorStateException异常
- 3.wait(),notify(),notifyAll()三个方法是定义在java.lang.Object类中。
3.面试题:
面试题:sleep() 和 wait()的异同? - 1.相同点:一旦执行方法,都可以使得当前的线程进入阻塞状态。
- 2.不同点:1)两个方法声明的位置不同:Thread类中声明sleep() , Object类中声明wait()
-
2)调用的要求不同:sleep()可以在任何需要的场景下调用。 wait()必须使用在同步代码块或同步方法中 -
3)关于是否释放同步监视器:如果两个方法都使用在同步代码块或同步方法中,sleep()不会释放锁,wait()会释放锁。


新的多线程的方法:实现Callable接口>创建 futureTask=>放入到Thread线程当中
//1.创建一个实现Callable的实现类
class NumThread implements Callable{
//2.实现call方法,将此线程需要执行的操作声明在call()中
@Override
public Object call() throws Exception {
int sum = 0;
for (int i = 1; i <= 100; i++) {
if(i % 2 == 0){
System.out.println(i);
sum += i;
}
}
return sum;
}
}
public static void main(String[] args) {
//3.创建Callable接口实现类的对象
NumThread numThread = new NumThread();
//4.将此Callable接口实现类的对象作为传递到FutureTask构造器中,创建FutureTask的对象
FutureTask futureTask = new FutureTask(numThread);
//5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()
new Thread(futureTask).start();
try {
//6.获取Callable中call方法的返回值
//get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值。
Object sum = futureTask.get();
System.out.println("总和为:" + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
- 如何理解实现Callable接口的方式创建多线程比实现Runnable接口创建多线程方式强大?
-
- call()可以返回值的。
-
- call()可以抛出异常,被外面的操作捕获,获取异常的信息
-
- Callable是支持泛型的
线程池 Executors.newFixedThreadPool(10)====>ThreadPoolExecutor ==>execute(runnable接口或者callable接口)
public static void main(String[] args) {
//1. 提供指定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;
//2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象
service.execute(new NumberThread());//适合适用于Runnable
service.execute(new NumberThread1());//适合适用于Runnable
// service.submit(Callable callable);//适合使用于Callable
//3.关闭连接池
service.shutdown();
}
16.String StringBuffer StringBuilder
string:声明为final的,不可被继承, 实现了Serializable接口:表示字符串是支持序列化的。
实现了Comparable接口:表示String可以比较大小
通过字面量的方式(区别于new给一个字符串赋值,此时的字符串值声明在字符串常量池中)。
字符串常量池中是不会存储相同内容(使用String类的equals()比较,返回true)的字符串的
通过new + 构造器的方式 数据在堆空间中开辟空间以后对应的地址值。
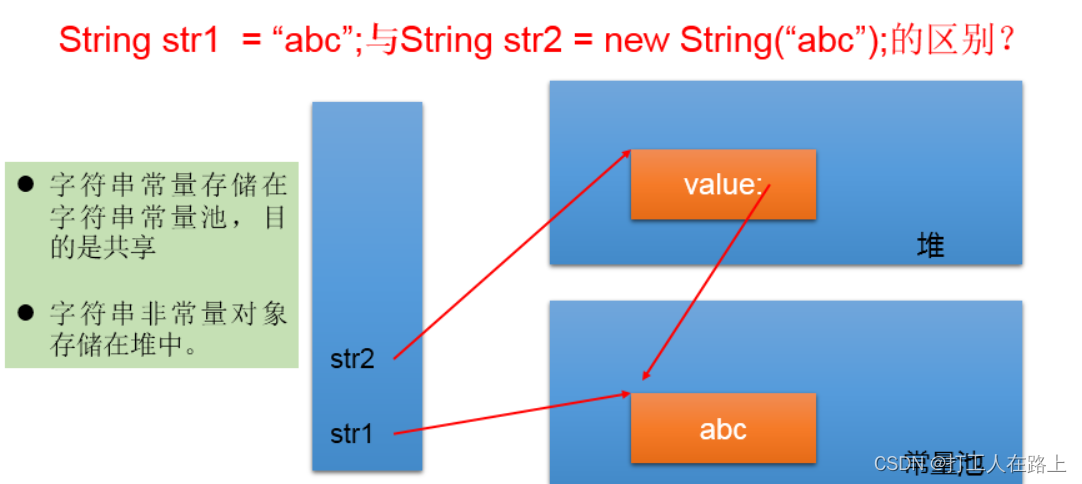
String s4 = “javaEE” + “hadoop”; 常量池
String s5 = s1 + “hadoop”; 堆
常用的方法
char charAt(int index): 返回某索引处的字符return value[index]
String trim():返回字符串的副本,忽略前导空白和尾部空白
int compareTo(String anotherString):比较两个字符串的大小
String substring(int beginIndex):返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串。
String substring(int beginIndex, int endIndex) :返回一个新字符串,它是此字符串从beginIndex开始截取到endIndex(不包含)的一个子字符串。
boolean endsWith(String suffix):测试此字符串是否以指定的后缀结束
boolean startsWith(String prefix):测试此字符串是否以指定的前缀开始
boolean startsWith(String prefix, int toffset):测试此字符串从指定索引开始的子字符串是否以指定前缀开始
String[] split(String regex):根据给定正则表达式的匹配拆分此字符串。
String[] split(String regex, int limit):根据匹配给定的正则表达式来拆分此字符串,最多不超过limit个,如果超过了,剩下的全部都放到最后一个元素中。
与字节数组之间的转换
编码:String --> byte[]:调用String的getBytes("gbk/utf-8")
解码:byte[] --> String:调用String的构造器
编码:字符串 -->字节 (看得懂 --->看不懂的二进制数据)
解码:编码的逆过程,字节 --> 字符串 (看不懂的二进制数据 ---> 看得懂
说明:解码时,要求解码使用的字符集必须与编码时使用的字符集一致,否则会出现乱码。
String –> 基本数据类型、包装类:调用包装类的静态方法:parseXxx(str)
基本数据类型、包装类 –> String:调用String重载的valueOf(xxx)
String –> char[]:调用String的toCharArray()
char[] –> String:调用String的构造器
JVM中字符串常量池存放位置说明:
jdk 1.6 (jdk 6.0 ,java 6.0):字符串常量池存储在方法区(永久区)
jdk 1.7:字符串常量池存储在堆空间
jdk 1.8:字符串常量池存储在方法区(元空间)
1.String、StringBuffer、StringBuilder三者的对比
String:不可变的字符序列;底层使用char[]存储
StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[]存储
StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
开发中建议大家使用:StringBuffer(int capacity) 或 StringBuilder(int capacity)

Data
1.获取系统当前时间:System类中的currentTimeMillis()//返回当前时间与1970年1月1日0时0分0秒之间以毫秒为单位的时间差。
2.java.util.Date类与java.sql.Date类
//构造器一:Date():创建一个对应当前时间的Date对象
Date date1 = new Date();
//构造器二:创建指定毫秒数的Date对象
Date date2 = new Date(155030620410L);
Date date6 = new Date();
java.sql.Date date7 = new java.sql.Date(date6.getTime());
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
String format1 = sdf1.format(date); //格式化
Comparable接口
方法1: 实现Comparable接口的compareTo方法,默认大到小,小到大的话加个-
方法2:定制排序:使用Comparator接口

17.枚举类
- 枚举类的说明:
- 1.枚举类的理解:类的对象只有有限个,确定的。我们称此类为枚举类
- 2.当需要定义一组常量时,强烈建议使用枚举类
- 3.如果枚举类中只一个对象,则可以作为单例模式的实现方式。
//自定义枚举类
class Season{
//1.声明Season对象的属性:private final修饰
private final String seasonName;
//2.私化类的构造器,并给对象属性赋值
private Season(String seasonName){
this.seasonName = seasonName;
}
//3.提供当前枚举类的多个对象:public static final的
public static final Season SPRING = new Season("春天","春暖花开");
public static final Season SUMMER = new Season("夏天","夏日炎炎");
public static final Season AUTUMN = new Season("秋天","秋高气爽");
public static final Season WINTER = new Season("冬天","冰天雪地");
}
- jdk 5.0 新增使用enum定义枚举类。步骤
enum Season1 {
//1.提供当前枚举类的对象,多个对象之间用","隔开,末尾对象";"结束
SPRING("春天","春暖花开"),
SUMMER("夏天","夏日炎炎"),
AUTUMN("秋天","秋高气爽"),
WINTER("冬天","冰天雪地");
//2.声明Season对象的属性:private final修饰
private final String seasonName;
//2.私化类的构造器,并给对象属性赋值
private Season1(String seasonName){
this.seasonName = seasonName;
}
}
values():返回所的枚举类对象构成的数组
5. 使用enum定义枚举类之后,如何让枚举类对象分别实现接口:
interface Info{
void show();
}
//使用enum关键字枚举类
enum Season1 implements Info{
//1.提供当前枚举类的对象,多个对象之间用","隔开,末尾对象";"结束
SPRING("春天","春暖花开"){
@Override
public void show() {
System.out.println("春天在哪里?");
}
},
SUMMER("夏天","夏日炎炎"){
@Override
public void show() {
System.out.println("宁夏");
}
},
AUTUMN("秋天","秋高气爽"){
@Override
public void show() {
System.out.println("秋天不回来");
}
},
WINTER("冬天","冰天雪地"){
@Override
public void show() {
System.out.println("大约在冬季");
}
};
}
18.注解的理解
Annotation 其实就是代码里的特殊标记, 这些标记可以在编译, 类加载, 运行时被读取, 并执行相应的处理。通过使用 Annotation,
程序员可以在不改变原逻辑的情况下, 在源文件中嵌入一些补充信息。
框架 = 注解 + 反射机制 + 设计模式
@Override: 限定重写父类方法, 该注解只能用于方法
@Deprecated: 用于表示所修饰的元素(类, 方法等)已过时。通常是因为所修饰的结构危险或存在更好的择
@SuppressWarnings: 抑制编译器警告
如何自定义注解:
- ① 注解声明为:@interface
- ② 内部定义成员,通常使用value表示
- ③ 可以指定成员的默认值,使用default定义
- ④ 如果自定义注解没成员,表明是一个标识作用。
如果注解有成员,在使用注解时,需要指明成员的值。
自定义注解通过都会指明两个元注解:Retention、Target
@Inherited
@Repeatable(MyAnnotations.class)
@Retention(RetentionPolicy.RUNTIME)
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE,TYPE_PARAMETER,TYPE_USE})
public @interface MyAnnotation {
String value() default "hello";
}
元注解 :对现有的注解进行解释说明的注解
jdk 提供的4种元注解:
Retention:指定所修饰的 Annotation 的生命周期:SOURCE\CLASS(默认行为*RUNTIM只声明为RUNTIME生命周期的注解,才能通过反射获取。*
**Target:**用于指定被修饰的 Annotation 能用于修饰哪些程序元素
Documented:表示所修饰的注解在被javadoc解析时,保留下来。
Inherited:被它修饰的 Annotation 将具继承性。
19.集合
集合、数组都是对多个数据进行存储操作的结构,简称Java容器。
数组存储的弊端:
-
> 一旦初始化以后,其**长度就不可修改**。 -
> 数组中**提供的方法非常限**,对于添加、删除、插入数据等操作,非常不便,同时效率不高。 -
> 获取数组中实际元素的个数的需求,数组**没有现成的属性或方法可用** -
> **数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。**
Collection接口 coll.toArray()转成数组
|—-Collection接口:单列集合,用来存储一个一个的对象
-
|----**List接口**:存储**有序的**、**可重复的数据**。 -->“动态”数组 -
|----ArrayList、LinkedList、Vector -
|----**Set接口**:存储**无序的、不可重复的**数据 -->高中讲的“集合” -
|----HashSet、LinkedHashSet、TreeSet 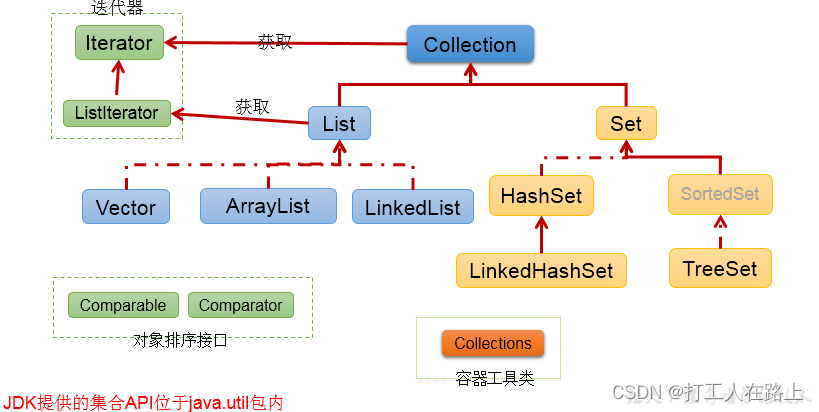
数组 —>集合:调用Arrays类的静态方法asList(T … t)
Arrays.asList(new String[]{“AA”, “BB”, “CC”});
1.遍历Collection的两种方式:
① 使用迭代器Iterator ② foreach循环(或增强for循环)
coll .iterator()返回一个迭代器实例
Iterator iterator = coll.iterator();
//hasNext():判断是否还下一个元素
while(iterator.hasNext()){
//next():①指针下移 ②将下移以后集合位置上的元素返回
System.out.println(iterator.next());
}
//for(集合元素的类型 局部变量 : 集合对象)
for(Object obj : coll){
System.out.println(obj);
}
List接口 collection的子接口
- 存储的数据特点:存储序的、可重复的数据。
增:add(Object obj)
删:remove(int index) / remove(Object obj)
改:set(int index, Object ele)
查:get(int index)
插:add(int index, Object ele)
-
|----**ArrayList**:作为List接口的主要实现类;**线程不安全的,效率高**;底层使用**长度10Object[] elementData存储** **扩容1.5倍** -
|----**LinkedList**:对于频繁的插入、删除操作,使用此类效率比ArrayList高;底层使用**双向链表存储** -
|---**-Vector**:作为List接口的古老实现类;**线程安全的,效率低**;底层使用Object[] elementData存储
Set接口 collection的子接口
存储的数据特点:无序的、不可重复的元素
- 无序性:不等于随机性。存储的数据在底层数组中并非照数组索引的顺序添加,而是根据数据的哈希值决定的。
- 不可重复性:保证添加的元素照equals()判断时,不能返回true.即:相同的元素只能添加一个。
元素添加过程
HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置,判断
数组此位置上是否已经元素:
如果此位置上没其他元素,则元素a添加成功。 —>情况1
如果此位置上其他元素b(或以链表形式存在的多个元素,则比较元素a与元素b的hash值:
如果hash值不相同,则元素a添加成功。—>情况2
如果hash值相同,进而需要调用元素a所在类的equals()方法:
equals()返回true,元素a添加失败
equals()返回false,则元素a添加成功。—>情况2
对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
jdk 7 :元素a放到数组中,指向原来的元素。
jdk 8 :原来的元素在数组中,指向元素a
总结:七上八下
HashSet底层:数组+链表的结构。(前提:jdk7)
|—-Collection接口:单列集合,用来存储一个一个的对象
-
|----**Set接口**:存储**无序的、不可重复的数据** -->高中讲的“集合” -
|----**HashSet**:作为Set接口的主要实现类;**线程不安全的;可以存储null值** -
|----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历 -
在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。对于频繁的遍历操作,LinkedHashSet效率高于HashSet. -
|----TreeSet:可以照添加对象的指定属性,进行排序。
向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
TreeSet:
1.自然排序中,比较两个对象是否相同的标准为:compareTo()返回0. 而不再是equals().
2.定制排序中,比较两个对象是否相同的标准为:compare()返回0. 而不再是equals().
Map接口
|—-Map:双列数据,存储key-value对的数据 —类似于高中的函数:y = f(x)
-
|----**HashMap**:作为Map的主要实现类;**线程不安全的**,效率高;**存储null的key和value** -
|----LinkedHashMap:保证在遍历map元素时,可以照添加的顺序实现遍历。 -
原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。 -
对于频繁的遍历操作,此类执行效率高于HashMap。 -
|----**TreeMap**:保证照添加的**key-value对进行排序**,实现**排序遍历**。此时考虑key的自然排序或定制排序 -
底层使用红黑树 -
|----**Hashtable**:作为古老的实现类;**线程安全的,效率低**;**不能存储null的key和value** -
|----Properties:常用来处理配置文件。key和value都是String类型 -
HashMap的底层:数组+链表 (jdk7及之前) -
数组+链表+红黑树 (jdk 8)
2.存储结构的理解:
Map中的key:无序的、不可重复的,使用Set存储所的key —> key所在的类要重写equals()和hashCode() (以HashMap为例)
Map中的value:无序的、可重复的,使用Collection存储所的value —>value所在的类要重写equals()
一个键值对:key-value构成了一个Entry对象。
Map中的entry:无序的、不可重复的,使用Set存储所的entry
常用方法
- 添加:put(Object key,Object value)
- 删除:remove(Object key)
- 修改:put(Object key,Object value)
- 查询:get(Object key)
- 长度:size()
- 遍历:keySet() / values() / entrySet()
HashMap在jdk8中相较于jdk7在底层实现方面的不同:
- new HashMap():底层没创建一个长度为16的数组
- jdk 8底层的数组是:Node[],而非Entry[]
- 首次调用put()方法时,底层创建长度为16的数组
- jdk7底层结构只:数组+链表。jdk8中底层结构:数组+链表+红黑树。
4.1 形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
4.2 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。
DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75
threshold:扩容的临界值,=容量*填充因子:16 * 0.75 => 12
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
Collections工具类 操作Collection和Map的工具类
reverse(List):反转 List 中元素的顺序
shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素升序排序
sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
Object min(Collection)
Object min(Collection,Comparator)
int frequency(Collection,Object):返回指定集合中指定元素的出现次数
void copy(List dest,List src):将src中的内容复制到dest中
boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所旧值
说明:ArrayList和HashMap都是线程不安全的,如果程序要求线程安全,我们可以将ArrayList、HashMap转换为线程的。
使用synchronizedList(List list) 和 synchronizedMap(Map map)
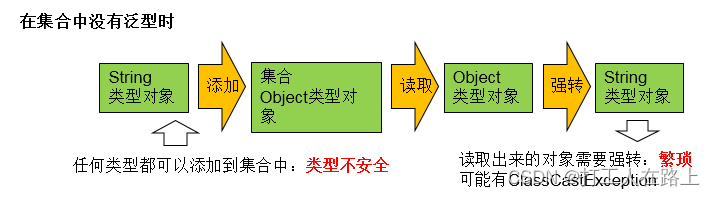
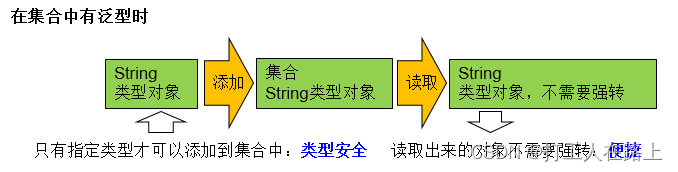
20.泛型
泛型,就是允许在定义类、接口时通过一个标识表示类中某个属性的类型或者是某个方法的返
回值及参数类型。这个类型参数将在使用时(例如,继承或实现这个接口,用这个类型声明变量、
创建对象时确定(即传入实际的类型参数,也称为类型实参)。
ArrayList<Integer> list = new ArrayList<Integer>();
Map<String,Integer> map = new HashMap<>();//jdk7新特性:类型推断
Set<Map.Entry<String,Integer>> entry = map.entrySet(); //泛型的嵌套
自定义泛型
public class Order<T> {
//如下的个方法都不是泛型方法
public T getOrderT(){
return orderT;
}
泛型方法:在方法中出现了泛型的结构,泛型参数与类的泛型参数没任何关系。
泛型方法所属的类是不是泛型类都没关系。
泛型方法,可以声明为静态的。原因:泛型参数是在调用方法时确定的。并非在实例化类时确定
public static <E> List<E> copyFromArrayToList(E[] arr){
}
}
//由于子类在继承带泛型的父类时,指明了泛型类型。则实例化子类对象时,不再需要指明泛型
public class SubOrder extends Order<Integer> {//SubOrder:不是泛型类
}
//如果定义了泛型类,实例化没指明类的泛型,则认为此泛型类型为Object类型
public class SubOrder1<T> extends Order<T> {//SubOrder1<T>:仍然是泛型类
}
集合中使用泛型总结:
- ① 集合接口或集合类在jdk5.0时都修改为带泛型的结构。
- ② 在实例化集合类时,可以指明具体的泛型类型
- ③ 指明完以后,在集合类或接口中凡是定义类或接口时,内部结构(比如:方法、构造器、属性等)使用到类的泛型的位 置,都指定为实例化的泛型类型。
- ④ 注意点:泛型的类型必须是类,不能是基本数据类型。需要用到基本数据类型的位置,拿包装类替换
- ⑤ 如果实例化时,没指明泛型的类型。默认类型为java.lang.Object类型。

虽然类A是类B的父类,但是G 和G二者不具备子父类关系,二者是并列关系。
类A是类B的父类,G和G是没关系的,二者共同的父类是:G<?>** 添加(写入):对于**List<?>就不能向其内部添加数据。
补充:类A是类B的父类,A
是 B
的父类
1.File类的理解
-
- File类的一个对象,代表一个文件或一个文件目录(俗称:文件夹)
-
- File类中涉及到关于文件或文件目录的创建、删除、重命名、修改时间、文件大小等方法,
-
- 并未涉及到写入或读取文件内容的操作。如果需要读取或写入文件内容,必须使用IO流来完成。
-
- 后续File类的对象常会作为参数传递到流的构造器中,指明读取或写入的”终点”.
IDEA中:
如果大家开发使用JUnit中的单元测试方法测试,相对路径即为当前Module下。
如果大家使用main()测试,相对路径即为当前的Project下。
- 后续File类的对象常会作为参数传递到流的构造器中,指明读取或写入的”终点”.



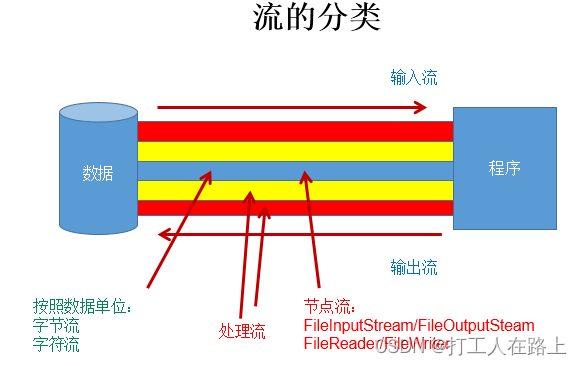
流的分类
- 1.操作数据单位:字节流、字符流
- 2.数据的流向:输入流、输出流
- 3.流的角色:节点流、处理流

字节流和文件流
xxxReader/xxxxWirter
- read()的理解:返回读入的一个字符。如果达到文件末尾,返回-1
- 异常的处理:为了保证流资源一定可以执行关闭操作。需要使用try-catch-finally处理
- 读入的文件一定要存在,否则就会报FileNotFoundException。
FileReader fr = new FileReader(new File("xxx.txt))
char[] cbuf = new char[5];
while((len = fr.read(cbuf)) != -1){
}
字节流
FileInputStream / FileOutputStream的使用:
-
- 对于文本文件(.txt,.java,.c,.cpp),使用字符流处理d
-
- 对于非文本文件(.jpg,.mp3,.mp4,.avi,.doc,.ppt,…),使用字节流处理
缓冲流(处理流 要在字节流(文件流)上包一层流) Bufferdxxxx
作用:提供流的读取、写入的速度
提高读写速度的原因:内部提供了一个缓冲区。默认情况下是8kb
关闭外层流的同时,内层流也会自动的进行关闭。关于内层流的关闭,我们可以省略.
while((data = br.readLine()) != null){
//方法一:
// bw.write(data + "\n");//data中不包含换行符
//方法二:
bw.write(data);//data中不包含换行符
bw.newLine();//提供换行的操作
}
转换流
InputStreamReader:将一个字节的输入流转换为字符的输入流
解码:字节、字节数组 —>字符数组、字符串
OutputStreamWriter:将一个字符的输出流转换为字节的输出流
编码:字符数组、字符串 —> 字节、字节数组
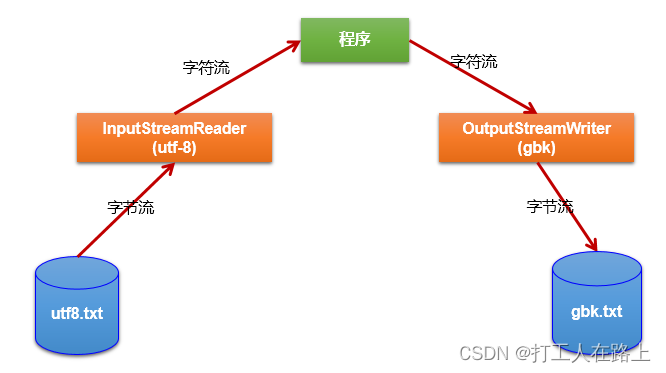
new InputStreamReader(new FileInputStream(“dbcp.txt”),“UTF-8”)
对象流
ObjectInputStream 和 ObjectOutputStream :要求实现可序列化的过程
ObjectOutputStream:内存中的对象—>存储中的文件、通过网络传输出去:序列化过程
ObjectInputStream:存储中的文件、通过网络接收过来 —>内存中的对象:反序列化过程
对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘
上,或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取了这种二进制流,就可以恢复成原来的Java对象
实现序列化的对象所属的类需要满足:
1.需要实现接口:Serializable
- 2.当前类提供一个全局常量:serialVersionUID
- 3.除了当前Person类需要实现Serializable接口之外,还必须保证其内部所属性
- 也必须是可序列化的。(默认情况下,基本数据类型可序列化)
- 补充:ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量