卷积神经网络实现
这个代码的话是跟着B站博主敲得 里面也解析了代码 想深入了解的可以看看
链接地址
一. 实验目的
利用keras的深度学习框架,分类mnist手写数字识别数据集
二. 实验内容
1.获得mnist数据,并将mnist数据处理成合适的格式;
2.构建神经网络模型:
3.配置训练参数;
4.训练网络;
5.测试训练好的网络模型
三.概要设计
1.实验原理
①获得mnist数据,并将数据处理成合适的格式:
首先查看数据集是怎样的,让图片由二维铺开成一维,相当于将图片从二维矩阵(28*28)到784像素值的一个向量,同时将数据格式转换为浮点型;
②按照自己的设计搭建神经网络:
③设定合适的参数训练神经网络:
a.编译:确定优化器和损失函数;
b.训练网络:确定训练的数据、训练的轮数和每次训练的样本数等;
④在测试集上评价训练效果:
a.利用损失函数变化和训练集的准确率评估它在数据集上的表现:
损失函数逐渐下降,训练集的准确率逐渐提升;
b.用训练好的模型进行预测,并在测试集上进行评价。
2.网络作用
神经网络是机器学习诸多算法中的一种,它既可以用来做有监督的任务,如分类、视觉识别等,也可以用作无监督的任务。同时它能够处理复杂的非线性问题,它的基本结构是神经元。,如下图所示: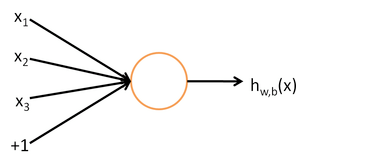
其中,x1、x2、x3代表输入,中间部分为神经元,而最后的hw,b(x)是神经元的输出。整个过程可以理解为输入——>处理——>输出。
由多个神经元组成的就是神经网络
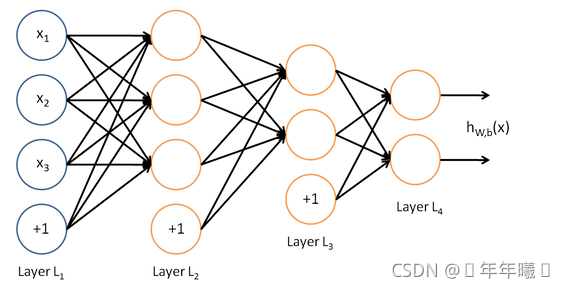
如图所示:
这是一个4层结构的神经网络,layer1为输入层,layer4为输出层,layer2,layer3为隐藏层,即神经网络的结构由输入层,隐藏层,输出层构成。其中除了输入层以外,每一层的输入都是上一层的输出。
而现在所用的卷积神经网络是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。卷积神经网络能够接受多个特征图作为输入,而不是向量。
3.各个网络层的功能描述
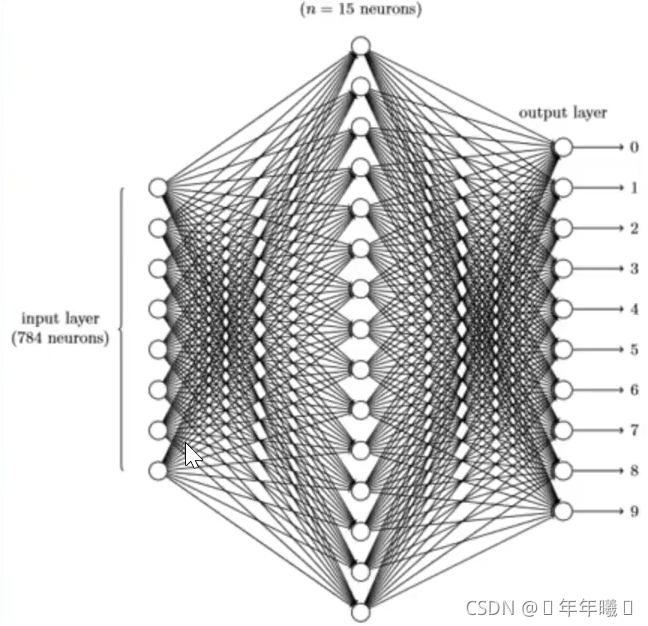
第一层——输入层:
输入层每个神经单元直接对应原始数据,然后向隐藏层提供信息,图片的每一个像素都需要输入层神经元与之对应,对原始图像数据进行预处理,而我们的每个图片大小包含784像素,输入层需要784个神经元;
第二层——隐藏层(中间层):
隐藏层每个神经单元对不同的输入层神经单元有不同的权重,从而偏向于对某种识别模式兴奋,隐藏层为15个神经元;
第三层——输出层:
多个隐藏层的神经单元兴奋后,输出层的神经单元根据不同隐藏层的兴奋加上权重后,给到不同的兴奋度,这个兴奋度就是模型最终识别的结果,它的神经元个数是确定的,一共为10类,10个神经元
四.详细设计
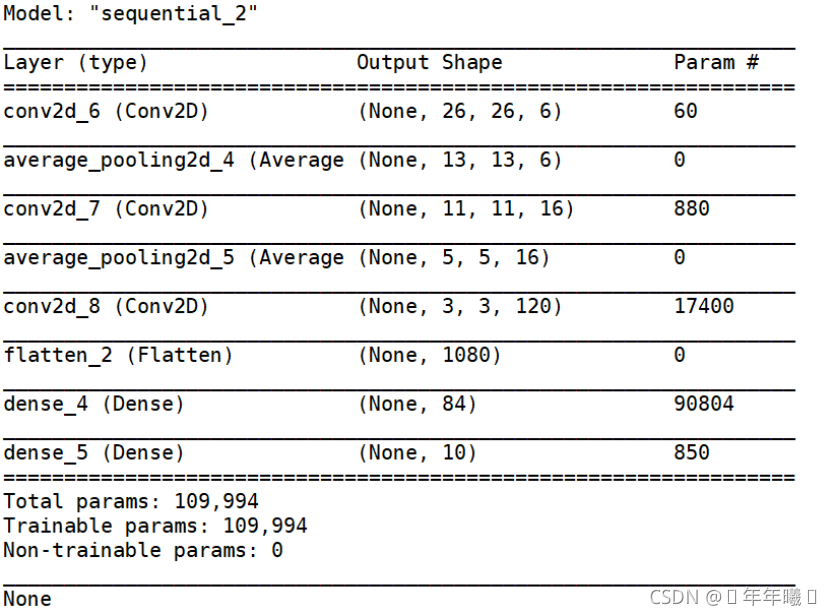
1.网络结构图
(用 print(network.summary()) 打印)
2.各个参数设计
①修改训练集及测试集的图片(28*28像素)从二维矩阵到一维向量:
train_images = train_images.reshape((60000, 28, 28, 1)).astype(‘float’) / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype(‘float’) / 255
将数据格式转换为浮点型
②训练网络参数:
network.fit(train_images, train_labels, epochs=10, batch_size=128, verbose=2)
epochs:训练多少个回合,
batch_size:每次训练给多大的数据
verbose = 2 为每个epoch输出一行记录
③变量类型及大小:
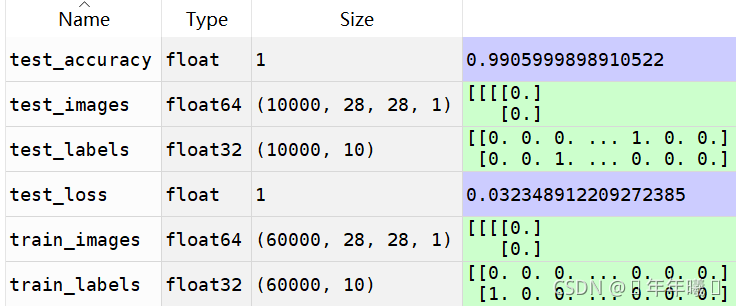
五.测试数据及运行结果
1.正常测试数据和运行结果
①取前五个图片进行预测(结果正常):
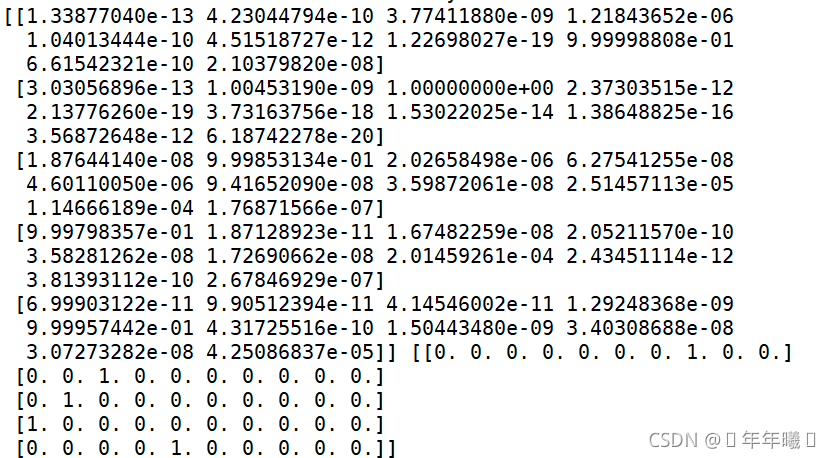
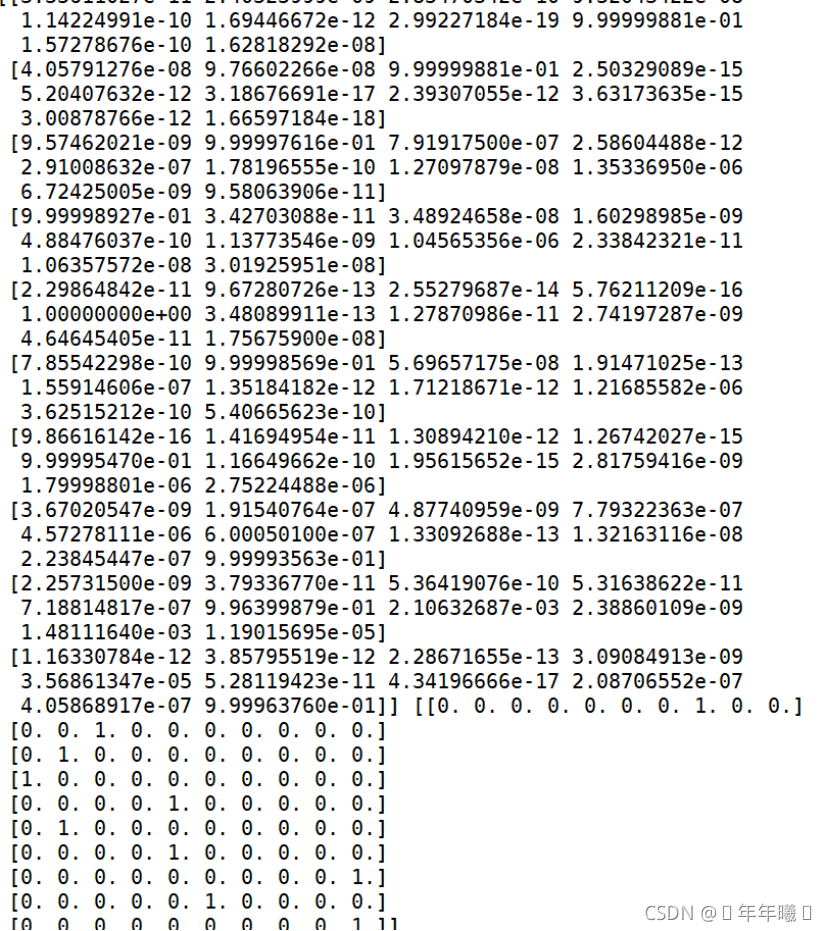
②取前10个图片进行预测(结果正常):
3.实验结果分析
通过多轮测试集的测试,发现训练效果基本符合,并且打印出训练集和测试集的准确率发现拟合基本相符,准确率如图所示:

六.调试情况,设计技巧及体会
1.改进方案
①实验一开始训练集和测试集的准确率低:原来隐藏层个数为15,现在增加到84;
②训练集比测试集拟合的更好:使用正则化 dropout解决
2.体会
一开始根据老师发的教程进行安装,发现运行起来导入库的速度较慢,于是在网上搜索发现Anaconda是一个集成库,于是便开始了安装它,过程比较艰辛,索性安装成功了,最后跑代码的结果很快。
在运行代码的过程中,发现版本更新运行后代码也发生了相应的变化,对此进行了改进。本次应用的是卷积神经网络,它常用来分析视觉图像,十分符合我们这次的实验要求。每次不同的课题,我们对网络模型的选择也是非常重要的。
这个实验我们在课上做了两三次,每次运行代码都会有新的改进收获匪浅。通过CSDN博客,我学习到了tensorflow框架的基本使用方法,通过python和tensorflow进行了神经网络的构造和实现,并通过神经网络实现了手写数字识别的功能。
通过这次实验,我觉得机器学习是个特别有意思的学科,可以进行爬虫和数据预测等,通过自己的努力看到实验的准确率稳步上升,成就感满满。在以后的学习生活中,我会以更大的兴趣投入其中,并深入学习神经网络的内容。fighting!!!
代码实现:
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import models, layers
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.datasets import mnist
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 搭建LeNet网络 神经网络的模型
def LeNet():
network = models.Sequential()
network.add(layers.Conv2D(filters=6, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
network.add(layers.AveragePooling2D((2, 2)))
network.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu'))
network.add(layers.AveragePooling2D((2, 2)))
network.add(layers.Conv2D(filters=120, kernel_size=(3, 3), activation='relu'))
network.add(layers.Flatten())
network.add(layers.Dense(84, activation='relu'))
network.add(layers.Dense(10, activation='softmax'))
return network
network = LeNet()
network.compile(optimizer=RMSprop(lr=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
#将图片由二维铺开成一维(相当于将图片从二维矩阵到一维向量)
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
print(test_labels[0])
# 训练网络,用fit函数, epochs表示训练多少个回合, batch_size表示每次训练给多大的数据
network.fit(train_images, train_labels, epochs=10, batch_size=1280, verbose=2)
#print(network.summary())
#测试集测试模型性能 取前五张图片
y_pre = network.predict(test_images[:10])
print(y_pre,test_labels[:10])
test_loss, test_accuracy = network.evaluate(test_images, test_labels)
print("test_loss:", test_loss, " test_accuracy:", test_accuracy)