vmalloc 主要用于给内核从高端内存中以页为单位分配大块内存,对应关系如下所示,主要分配 896M~1G 的物理地址空间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BYa4wp1X-1653630238073)(linux内存管理源码深入探究.assets/v2-903ce9a2c1d5203183f78ad56a41eb66_720w.jpg)]](https://img-blog.csdnimg.cn/204a7d3ed74942c8aa57cf88b3d32a1c.jpeg)
vmalloc 的执行流程简述为:
-
分配小块内存。实例化vmalloc内存分配器的核心数据描述符 vmap_area|vm_struct|pages,为 vmalloc 的工作提供内存基础。分配合适的虚拟内存区间 hole 从空闲红黑树找到合适大小的hole,隔离分配给 vmalloc
-
分配物理内存。调用alloc_page系列函数,从 pcp 或者 buddy 0 阶每次分配1页物理内存,直到分配满足需求为止。
-
更新页表映射。将物理内存与虚拟内存一一建立映射,然后返回虚拟起始地址给用户,完成分配动作
vmalloc
vmalloc 调用链如下
vmalloc
--- __vmalloc
--- __vmalloc_node
--- get_vm_area_node : 获取一个 vm_struct
--- __get_vm_area_node
--- __vmalloc_area_node : 为 vm_struct 映射 pages
__get_vm_area_node 用于申请 vm_struct ,vm_struct 用于管理如下图所示的 vmalloc 区对应的虚拟地址,属于高端内存的非连续映射区域。所有的 vmalloc 区由 vmlist 串联起来,因此,想要根据某个地址区间使用 vmalloc 区,只需要遍历 vmlist 即可
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wvd3Kd1M-1653630238076)(linux内存管理源码深入探究.assets/v2-ed8a67338be62f15e02df9dddde4d7af_720w.jpg)]](https://img-blog.csdnimg.cn/9841fc7f1591435099cb70fb7123a667.jpeg)
具体地,__get_vm_area_node 实现如下
- 首先,调用 kmalloc_node 为 vm_struct 结构申请内存(这部分内存为低端内存)
- 根据 size+addr < tmp->addr 遍历 vmlist 找出待申请地址对应的下一个 vm_struct
- 初始化申请好的 vm_struct ,其表示的便是申请的地址段对应的虚拟地址
struct vm_struct *__get_vm_area_node(unsigned long size, unsigned long flags,
unsigned long start, unsigned long end, int node)
{
struct vm_struct **p, *tmp, *area;
unsigned long align = 1;
unsigned long addr;
// ...
addr = ALIGN(start, align);
size = PAGE_ALIGN(size);
area = kmalloc_node(sizeof(*area), GFP_KERNEL, node);
size += PAGE_SIZE;
write_lock(&vmlist_lock);
for (p = &vmlist; (tmp = *p) != NULL ;p = &tmp->next) {
if ((unsigned long)tmp->addr < addr) {
if((unsigned long)tmp->addr + tmp->size >= addr)
addr = ALIGN(tmp->size +
(unsigned long)tmp->addr, align);
continue;
}
if ((size + addr) < addr)
goto out;
if (size + addr <= (unsigned long)tmp->addr)
goto found;
addr = ALIGN(tmp->size + (unsigned long)tmp->addr, align);
if (addr > end - size)
goto out;
}
found:
area->next = *p;
*p = area;
area->flags = flags;
area->addr = (void *)addr;
area->size = size;
area->pages = NULL;
area->nr_pages = 0;
area->phys_addr = 0;
write_unlock(&vmlist_lock);
return area;
out:
write_unlock(&vmlist_lock);
kfree(area);
if (printk_ratelimit())
printk(KERN_WARNING "allocation failed: out of vmalloc space - use vmalloc=<size> to increase size.\n");
return NULL;
}
接着通过 __vmalloc_area_node 完成 page 申请,及 page 与 vm_struct 的映射。
- 通过 alloc_page 挨个申请 page ,并存入 pages 数组中
- map_vm_area 将 vm_struct 与 pages 进行映射
void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
struct page **pages;
unsigned int nr_pages, array_size, i;
nr_pages = (area->size - PAGE_SIZE) >> PAGE_SHIFT;
array_size = (nr_pages * sizeof(struct page *));
area->nr_pages = nr_pages;
//...
for (i = 0; i < area->nr_pages; i++) {
if (node < 0)
area->pages[i] = alloc_page(gfp_mask);
else
area->pages[i] = alloc_pages_node(node, gfp_mask, 0);
if (unlikely(!area->pages[i])) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
}
if (map_vm_area(area, prot, &pages))
goto fail;
return area->addr;
fail:
vfree(area->addr);
return NULL;
}
map_vm_area 主要用于创建页表。这里梳理一下如何建立页表映射。linux 中默认才用四级页表,不同的体系结构根据需求来使用不同级页表。创建页表只需要逐级递归创建
五级页表一共分为如下所示,对应了接下来的创建代码
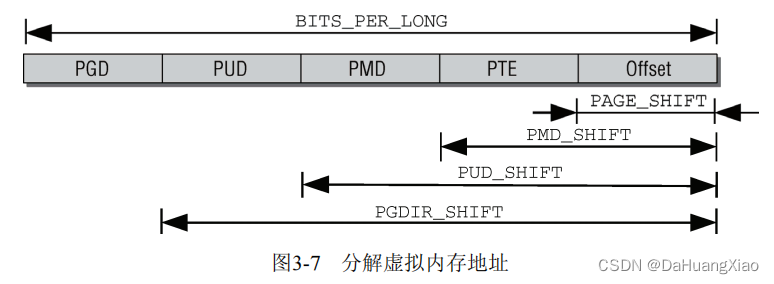
整个修改发生于内核页表上,因此 pgd 为内核页表的 pgd ,通过 pgd_offset_k 可以获得,其通过 init_mm->pgd_t 进行获取
调用 pgd_addr_end 获得其需要遍历的下一个 页表项,通过 vmap_pud_range 进行 pud 的创建。整个过程循环进行,直到所有范围内的 pgd 都创建完成。
#define pgd_offset(mm,addr) ((mm)->pgd + pgd_index(addr))
#define pgd_offset_k(address) pgd_offset(&init_mm, address)
int map_vm_area(struct vm_struct *area, pgprot_t prot, struct page ***pages)
{
pgd_t *pgd;
unsigned long next;
unsigned long addr = (unsigned long) area->addr;
unsigned long end = addr + area->size - PAGE_SIZE;
int err;
BUG_ON(addr >= end);
pgd = pgd_offset_k(addr);
do {
next = pgd_addr_end(addr, end);
err = vmap_pud_range(pgd, addr, next, prot, pages);
if (err)
break;
} while (pgd++, addr = next, addr != end);
flush_cache_vmap((unsigned long) area->addr, end);
return err;
}
vmap_pud_range 中进行 pud 的创建,由于是全新的页表,因此需要通过 pud_alloc 申请 page 进行存放,首地址为 pud 。遍历申请好的 pud 调用 vmap_pmd_range 进行 pmd 的递归创建
static inline int vmap_pud_range(pgd_t *pgd, unsigned long addr,
unsigned long end, pgprot_t prot, struct page ***pages)
{
pud_t *pud;
unsigned long next;
pud = pud_alloc(&init_mm, pgd, addr);
if (!pud)
return -ENOMEM;
do {
next = pud_addr_end(addr, end);
if (vmap_pmd_range(pud, addr, next, prot, pages))
return -ENOMEM;
} while (pud++, addr = next, addr != end);
return 0;
}
vmap_pmd_range 与 vmap_pud_range 类似,最后调用 vmap_pte_range
static inline int vmap_pmd_range(pud_t *pud, unsigned long addr,
unsigned long end, pgprot_t prot, struct page ***pages)
{
pmd_t *pmd;
unsigned long next;
pmd = pmd_alloc(&init_mm, pud, addr);
if (!pmd)
return -ENOMEM;
do {
next = pmd_addr_end(addr, end);
if (vmap_pte_range(pmd, addr, next, prot, pages))
return -ENOMEM;
} while (pmd++, addr = next, addr != end);
return 0;
}
vmap_pte_range 用于创建 pte 并设置物理地址,调用 set_pte_at 完成物理地址的赋值
static int vmap_pte_range(pmd_t *pmd, unsigned long addr,
unsigned long end, pgprot_t prot, struct page ***pages)
{
pte_t *pte;
pte = pte_alloc_kernel(pmd, addr);
if (!pte)
return -ENOMEM;
do {
struct page *page = **pages;
WARN_ON(!pte_none(*pte));
if (!page)
return -ENOMEM;
set_pte_at(&init_mm, addr, pte, mk_pte(page, prot));
(*pages)++;
} while (pte++, addr += PAGE_SIZE, addr != end);
return 0;
}
上述迭代过程,结合最开始的页表结构就很好理解了。并且需要清楚的是,因为是新的页表项,需要申请 page 进行存放
最后说一下进程内核页表的更新。从进程被创建时,除了复制一份父进程的页表还会复制一份内核页表。而内核页表必须保证每个进程使用的都是一样的,在 vmalloc 中,已经触发了内核页表的修改(所谓内核页表就是 init 进程的 mm_struct),那其他进程如何同步呢?
答案是通过缺页中断来实现延时同步。因为当其他进程想要访问新映射的 vmalloc 区虚拟地址时,由于其内核页表没更新,因此会匹配不到,触发缺页中断。进而此时再将修改的内核页表同步到该进程中即可。意味着如果没有使用到这部分地址,也不会触发内核页表同步。可以说很巧妙了
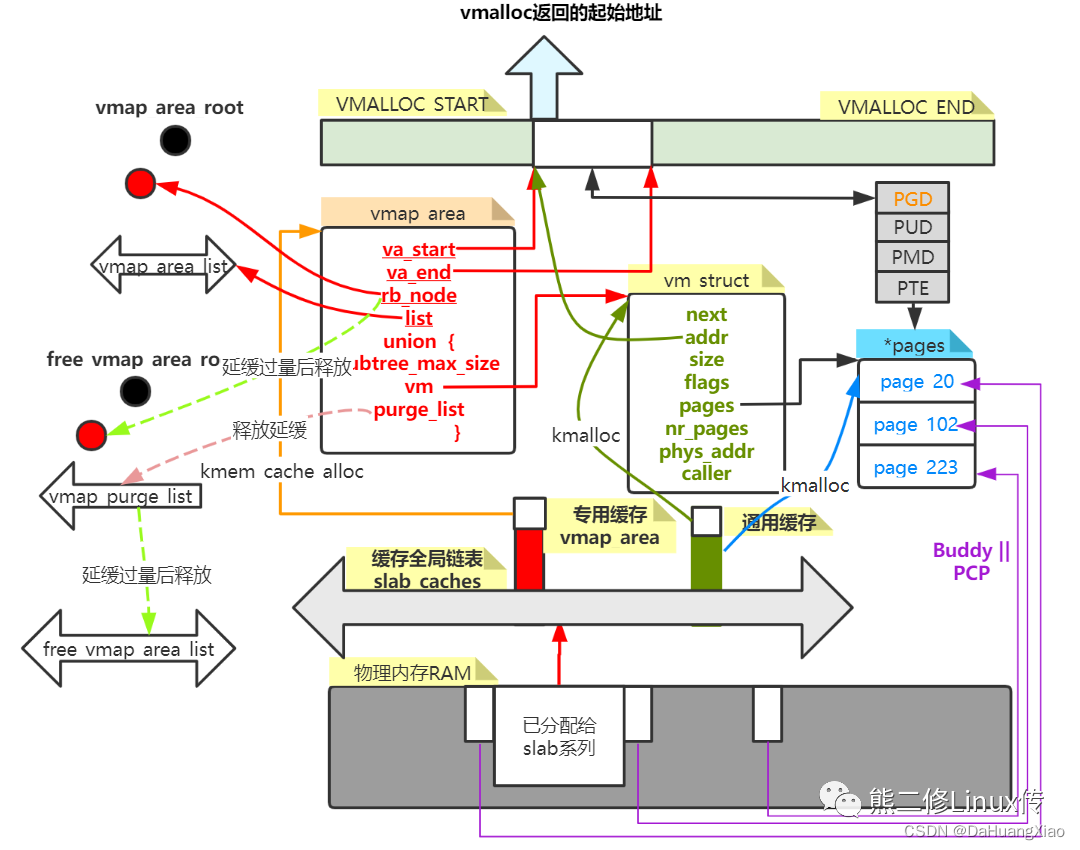
最后放一张画得很好地关系图如下,图片来自 https://mp.weixin.qq.com/s/92vE6kfAVxUayJkC_5mflQ