目录
6.3.4 多级队列调度(Multilevel Queue Scheduling)
6.3.5 多级反馈队列调度(Multilevel Feedback Queue Scheduling)
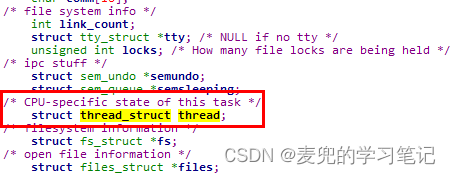
8.4.4 在task_struct结构体中新增kernelstack字段
8.4.7 实现first_return_from_kernel函数
1 本章组织逻辑
1. 为了提高CPU利用率,在上一章Linux 0.11内核分析04:多进程视图 笔记中,引入了多进程概念。多个进程同时在内存中启动运行,然后在这些进程之间来回切换交替执行,可以让CPU的工作效率大幅提升
2. 本章引入线程的概念,并以线程为单位说明CPU切换是为了简化讨论。进程切换由如下2部分构成,
① 指令流切换,是CPU切换,也就是线程切换,是进程切换的核心内容
② 资源切换,是将分配给进程的除CPU以外的资源进行切换,例如进程虚拟地址空间的切换
本章先说明指令流切换,资源切换在后续的内存管理和文件系统等章节说明
3. 在结构安排上,本章将分别讨论用户级线程与内核级线程,并且先分析线程切换,后分析线程创建。这是因为一旦理解了线程切换的具体实现,线程创建就很容易理解了,线程创建就是将线程初始化为第一次切换的场景
4. 在理解了线程的切换与创建之后,将说明CPU调度,从而形成进程创建(fork)、调度(schedule)、切换(switch_to)的完整图景
2 进程与线程
2.1 线程概念的引入
1. 如Linux 0.11内核分析04:多进程视图 chapter 4.2所述,多进程之间需要解决地址空间隔离问题。而解决的方法就是每个进程有自己的映射表,实现进程的虚拟地址空间到物理内存的映射
这也就自然导致了在进程切换时,映射表也需要切换

2. 线程概念的引入源于这样的想法:能否只切换指令流(即切换PC寄存器),而不切换映射表。出现这样的想法有如下2个原因,
① 只切换指令流,切换的速度更快,代价更小
② 有些资源需要在多个指令流之间共享,比如多个指令流操作同一段内存。如果使用进程实现,还需要额外的进程间通信手段来共享这段内存
3. 因此我们将进程中的资源和指令执行分开,即进程 = 一个资源 + 多个指令执行流,其中的指令执行流就是一个线程
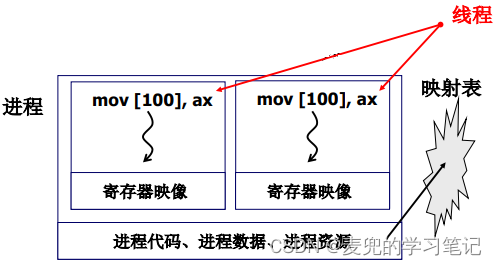
4. 线程保留了并发的优点,但是避免了进程切换的代价
2.2 多线程实例
对于采用线程实现的浏览器,在打开一个网卡时,可以启动4个线程,
1. 获取数据的线程(GetData)
2. 显示文本的线程(ShowText)
3. 解压图片的线程(ProcessImage)
4. 渲染图片的线程(ShowImage)
如下2点,可以体现出线程的实际价值,
1. 4个线程交替工作,可以逐渐显示出网页的内容,用户体验较好。如果只有单线程,则需要完成所有的数据下载及文本与图片处理之后,才能一次性显示所有内容
2. 4个线程要操作的数据本身就是需要共享的,如果隔离在不同的进程中反而会降低效率
2.3 线程与进程对比

说明:上表列出了线程和进程的区别与联系,利用该表,可以决定在完成某项计算任务时是选择线程还是进程
3 用户级线程的切换与创建
3.1 用户级线程与内核级线程
1. 线程是在一个地址空间内启动并交替执行的多个执行流,交替执行的多个线程可以由用户程序自己管理,也可以由操作系统管理
2. 由用户程序自己管理的线程,称为用户级线程,他们对操作系统透明,操作系统完全不知道这些线程的存在
3. 由操作系统管理的线程,称为内核级线程
3.2 用户级线程切换
3.2.1 用户级线程切换场景
假设有如下用户级线程切换场景,
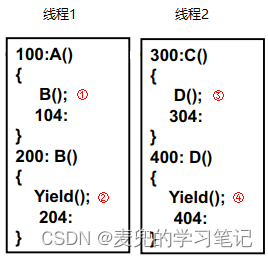
要实现的调用流程如下,
1. 线程1首先执行,并执行到A函数,在A函数中调用B函数
2. 在线程1的B函数中调用Yield函数触发线程切换,切换到线程2执行(地址300处)
3. 线程2执行到C函数,在C函数中调用D函数
4. 在线程2的D函数中调用Yield函数触发线程切换,目标是切换回线程1的Yield函数之后继续运行,即返回之前的线程切换点继续执行(地址204处)
相关函数调用关系如下,
A() --> B() --> Yield(切换到线程2) --> C() --> D() --> Yield(切换回线程1)说明:由于用户级线程对操作系不可见,所以用户级线程切换依靠在用户级线程中调用Yield函数实现。Yield函数需要选择下一个执行的用户级线程,并完成线程切换
3.2.2 只使用一个栈进行切换
为了确保在函数调用和线程切换之后执行流可以返回继续执行,需要将各级返回地址保存在栈中。如果切换中只使用一个栈,则栈的状态变迁如下,
1. A函数调用B函数之后
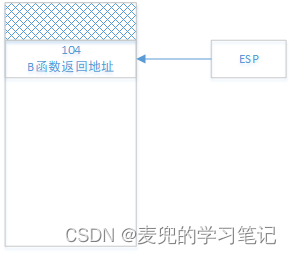
2. B函数调用Yield函数之后
与此同时,PC寄存器会切换到线程2执行,即地址为300处的函数C
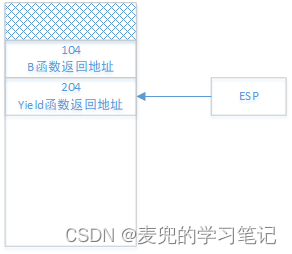
3. C函数调用D函数之后

4. D函数调用Yield函数之后
与此同时,PC寄存器会切换回之前B函数被切换走的位置继续执行线程1
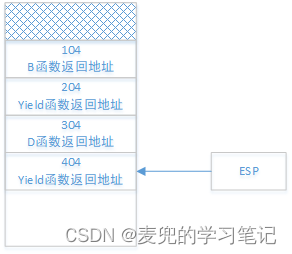
这里的切换就会存在问题,如果Yield函数中直接将PC寄存器置为204继续执行,那么当B函数结束时,相应的ret指令会将当前栈顶的404出栈到PC寄存器。但此时我们期望出栈的地址是104,从而实现从B函数到A函数的调用返回
很明显可以看出,导致问题的原因就是将线程1和线程2的活动记录保存在同一个栈中,因此自然就想到要为每个线程单独分配栈空间
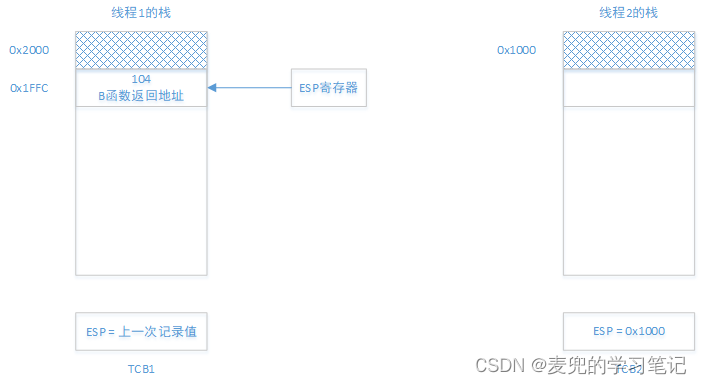
3.2.3 使用线程栈进行切换
现在我们为每个线程单独分配栈空间,同时将当前的栈顶记录在线程的TCB中,则栈的状态变迁如下,
1. A函数调用B函数之后
需要注意的是,由于ESP寄存器只有一个,所以此时指向线程1的栈;线程2的栈顶则记录在TCB2中
2. B函数调用Yield函数之后,此时,
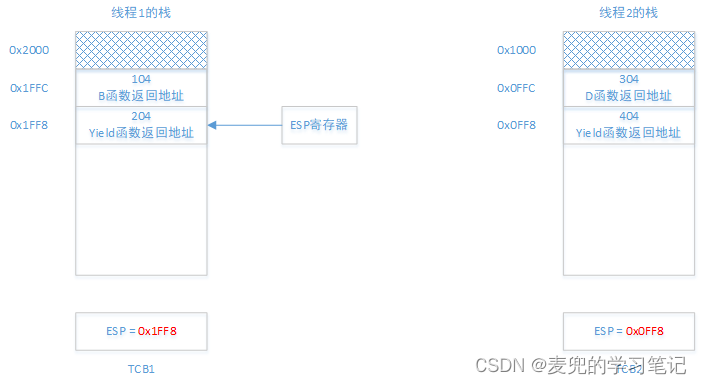
线程1的栈顶被保存在TCB1中,而ESP寄存器则指向线程2的栈

3. C函数调用D函数之后

4. D函数调用Yield函数之后,此时的目标是将执行流切换到线程1的204处继续执行,也就是回到线程2中调用Yield函数的切换点继续执行。实现该目标可以分为2个步骤,
① 首先实现栈的切换,将线程2的栈顶保存在TCB2中,然后从TCB1中取出线程1的栈顶赋值给ESP寄存器
② 此时执行流并没有切换,仍在线程2中,借助线程2中调用的Yield函数返回的ret指令,即可将执行流切换到线程1的204处
能实现该目标,这是因为ret指令执行的操作是将当前栈顶元素出栈到PC寄存器
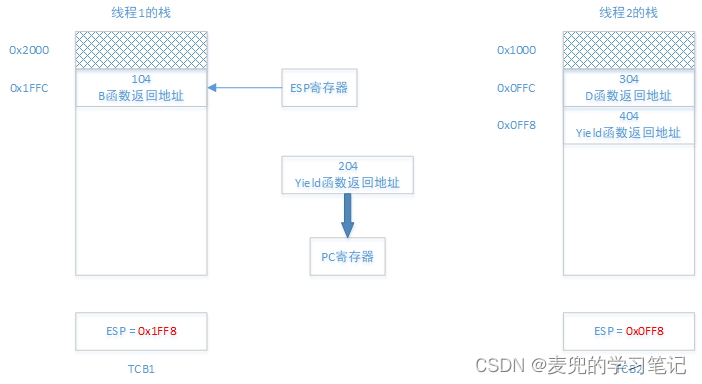
后续当B函数返回时,相应的ret指令又会将当前栈顶的地址104出栈到PC寄存器,从而可以返回到A函数中继续执行
说明:关于call & ret指令的行为,可参考庖丁解牛Linux内核分析01:操作系统工作原理基础 chapter 3.2.2
3.2.4 Yield函数伪代码
根据上文分析,Yield函数的核心在于完成如下功能,
1. 进行线程调度,其实就是选择下一个执行的线程
2. 进行栈切换,将ESP寄存器的值保存在当前线程的TCB中,然后将下一线程TCB中保存的栈顶值赋值给ESP寄存器
3. 进行执行流切换,依靠Yield函数返回的ret指令,将执行流切换到下一个线程
据此,就可以给出Yield函数的伪代码,
void Yield(void)
{
// 进行线程调度,选择下一个执行的线程
next = FindNext();
// 将当前线程的执行现场保存在当前线程的栈中
push %eax
push %ebx
...
// 进行栈切换
mov %esp, TCB[current].esp
mov TCB[next].esp, %esp
// 恢复下一线程的执行现场
...
pop %ebx
pop %eax
// Yield函数返回的ret指令,将切换执行流
}说明:关于通过栈实现执行流的切换,可参考如下笔记
编程高手必学的内存知识02:深入理解栈 chapter 3
庖丁解牛Linux内核分析01:操作系统工作原理基础 chapter 4.4
3.3 用户级线程创建
3.3.1 概述
1. 创建线程的目的,是要让一段程序执行起来
2. 在理解了用户级线程的切换之后,就知道了切换时的场景,而创建线程就是人为构造线程第一次被切换执行时的场景
3. 仍以之前的用户级线程切换场景为例,假设在从线程1切换到线程2之前,已经按下图构造了线程2第一次被切换执行时的场景
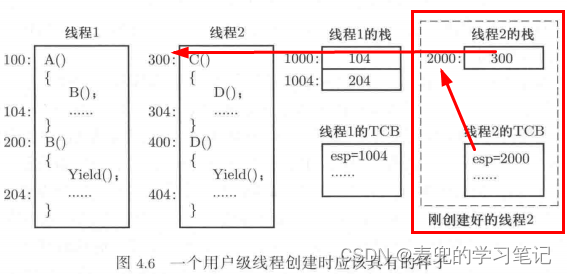
① 线程2的TCB中记录的栈顶地址为2000
② 构造的栈顶元素为C函数的起始地址300
这样,当从线程1切换到线程2时,首先会进行栈的切换,此时ESP寄存器会指向线程2的栈。随着后续的出栈操作,就可以将C函数的起始地址300弹出到PC寄存器,从而实现线程2的运行。而这里的C函数起始地址,就是线程2的入口地址
所谓线程的入口地址,就是该线程执行的第一条指令的地址
3.3.2 ThreadCreate函数伪代码
// func为新创建线程的入口地址
void ThreadCreate(void *func)
{
// 分配线程TCB内存
TCB *tcb = malloc(TCB_SIZE);
// 分配线程栈内存
// 并且将stack指针指向栈顶(满减栈)
long *stack = malloc(STACK_SIZE) + STACK_SIZE;
// 线程入口地址压栈
*(--stack) = func;
// 初始化线程执行现场,可以全为0
// 此处设置的线程首次执行现场,将由Yield函数进行恢复
*(--stack) = eax;
*(--stack) = ebx;
...
tcb->esp = stack;
}说明1:上述ThreadCreate函数伪代码构造的线程栈初始状态如下,

说明2:由ThreadCreate函数伪代码可见,用户级线程是完全在用户态内存中创建的一个指令执行序列,即用户级线程的TCB、线程栈等内容都在用户态创建,对操作系统完全不可见
3.3.3 向线程入口函数传递参数
3.3.3.1 问题引入
上述ThreadCreate函数创建新线程时有2个问题,
1. 无法传递参数
对照Linux中pthread库提供的线程创建函数,pthread_create函数除了可以传递线程的起始地址,还可以向其传递参数

2. 线程函数执行完成退出后,返回的状态未知
如上文所述,func函数是新创建线程的入口地址,在实现上本身也是一个函数。如果func函数返回,则会在执行到func函数最后的ret指令时,将当前栈顶元素弹出到PC寄存器,而该值是未知的,会导致程序跑飞
因此我们需要对ThreadCreate函数进行改进,使其能够传递参数给线程函数,同时也可以处理线程函数返回时的场景
3.3.3.2 函数使用参数分析
由于线程函数func本质上也是一个函数,因此我们先回顾一下函数是如何使用使用参数,以及如何处理函数返回的
假设有如下代码,可见对于func函数的参数和返回值,我们仿照了pthread_create函数中的线程执行函数
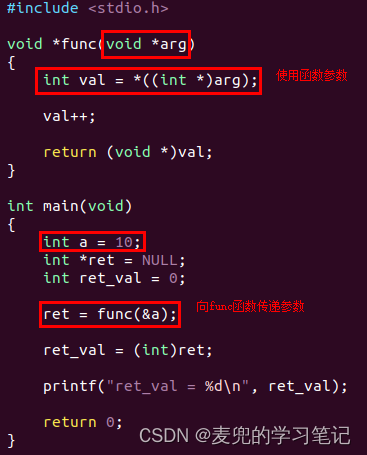
相应的反汇编如下,
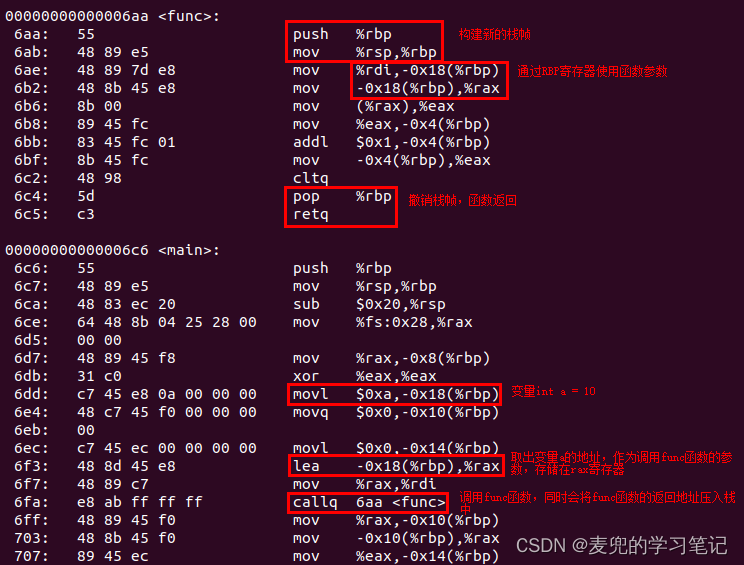
总的来说,就是在跳转到func函数时,在栈中依次压入参数、函数返回地址,此时ESP寄存器指向存放函数返回地址的那个内存单元
说明:根据X86体系结构与编译器的约定,当函数有多个参数时,参数压栈从右向左进行
3.3.3.3 ThreadCreate函数改进
根据上文分析,我们在ThreadCreate函数中增加向线程函数传参以及处理线程函数返回的压栈操作
// func为新创建线程的入口地址
void ThreadCreate(void *func, void *arg)
{
// 分配线程TCB内存
TCB *tcb = malloc(TCB_SIZE);
// 分配线程栈内存
// 并且将stack指针指向栈顶(满减栈)
long *stack = malloc(STACK_SIZE) + STACK_SIZE;
// 线程函数参数压栈
*(--stack) = arg;
// 线程函数返回地址,在thread_exit函数中应该正确处理线程的退出与释放
*(--stack) = thread_exit;
// 线程入口地址压栈
*(--stack) = func;
// 初始化线程执行现场,可以全为0
// 此处设置的线程首次执行现场,将由Yield函数进行恢复
*(--stack) = eax;
*(--stack) = ebx;
...
tcb->esp = stack;
}4 内核级线程的切换与创建
4.1 内核级线程的引入
4.1.1 用户级线程缺点

1. 在进程1中,虽然通过用户级线程启动了多个执行序列,但是他们对于操作系统而言都是不可见的,完全由用户控制其调度,这点在上文中已有说明
由于用户级线程对操作系统不可见,所以操作系统无法为其分配CPU等执行资源。此时只能以进程为单位分配CPU资源,之后进程1中的用户级线程再依据自身的调度策略分配进程1的CPU资源
2. 一个用户级线程在执行过程中可能会进入内核态(e.g. 需要通过系统调用使用操作系统内核提供的服务),进入内核态之后,该线程可能被阻塞(e.g. 等待接收网络数据)
由于操作系统无法感知用户级线程,所以只要进程中的一个用户级线程在内核中阻塞,则这个进程中的所有用户级线程将全部阻塞(因为这个进程的CPU资源已经被剥夺了)
3. 上述问题就限制了用户级线程的并发程度,从而限制了由并发性带来的计算机硬件工作效率的提升。自然地,也就引出了内核级线程的概念,也就是能让操作系统感知到的线程
4.1.2 内核级线程与用户级线程的区别
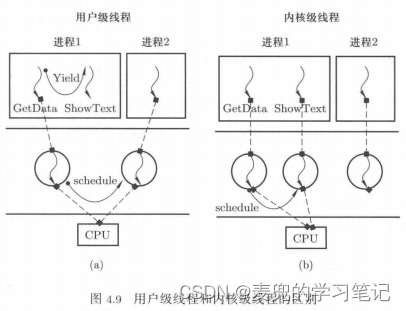
1. 内核级线程相较于用户级线程的最大区别,就是要让操作系统能感知其存在
因此内核级线程的创建函数是一个系统调用,会进入内核态,并且在内核态分配TCB和线程内核栈。操作系统通过这些数据结构就可以感知和控制内核级线程
2. 由于操作系统可以感知到内核级线程,所以可以为其分配CPU等执行资源(也就是说,内核级线程可以作为操作系统的调度实体)。因此内核级线程具有更好的并发性,硬件工作效率也更高
说明1:为什么没有用户级进程?
① 因为操作系统需要为进程分配CPU和内存等资源,因此不可能完全在用户态进行
② 在操作系统中,进程是分配资源的单位,而内核态线程是调度的单位
说明2:此处需要再辨析一个概念,就是内核级线程并不是只能在内核态运行;用户级线程也不是只能在用户态运行
区分的关键是该线程由谁管理(e.g. TCB由谁创建、由谁进行调度),由内核态管理的就是内核级线程;由应用程序自己管理的则是用户级线程
如果进程中只有一个线程,那么该线程也是内核级线程
4.1.3 用户级线程与内核级线程比较

用户级线程和内核级线程有各自的特点,在一般的操作系统中,同时有进程、用户级线程和内核级线程,这样系统才能够更加灵活
4.2 内核级线程切换
4.2.1 内核级线程切换与用户级线程切换的区别
首先来回顾一下用户级线程切换的核心三步骤,
1. 线程调度,选择下一个要执行的线程的TCB
2. 根据TCB切换用户栈
3. 通过ret指令切换执行流
在内核级线程切换时,也需要完成上述核心步骤,但是有如下区别
4.2.1.1 在内核态完成切换
1. 用户级线程切换由用户级线程主动调用Yield函数触发,并完全在用户态完成
2. 由于内核级线程的TCB由操作系统在内核态创建,并且由操作系统管理,因此内核级线程切换只能在内核态由操作系统完成
4.2.1.2 通过内核栈完成切换
1. 由于内核级线程切换在内核态完成,因此需要使用内核栈来完成切换的核心三步骤
3. 内核级线程同时具有用户栈与内核栈,一来是出于安全性的考虑,二来也是体系结构的要求。在IA-32体系结构中,在保护模式下使用的栈的特权级必须和CPL相同
在Linux + IA-32体系结构中,应用程序运行在ring 3,操作系统内核运行在ring 0。因此内核级线程在用户态运行时,需要使用特权级为3的栈;当内核级线程在内核态运行时,需要使用特权级为0的栈。相关内容可参考X86汇编语言从实模式到保护模式16:特权级和特权级保护 chapter 4
说明1:用户级线程陷入内核态时(e.g. 通过系统调用),也需要使用内核栈。此时用户级线程使用的就是他所属的进程的内核栈,或者说该进程对应的内核级线程的内核栈
此处想表明的是,用户级线程没有独立的内核栈,只有独立的用户栈
说明2:可以看出,内核级线程切换的思路和用户级线程切换是一致的,只是使用的资源不同,即需要使用内核栈完成切换
说明3:有没有只有内核栈没有用户栈的线程?
① 如上文所述,用户级线程有独立的用户栈,没有独立的内核栈;而内核级线程有独立的用户栈和内核栈
② 在Linux 0.11内核中,没有只有独立的内核栈而没有独立的用户栈的线程。但是在后续的Linux内核版本中,引入了内核线程的概念,该线程只在内核态运行,就只有内核栈而没有用户栈
③ 一定要区分这里的内核线程与本文讨论的内核级线程的区别,
- 内核线程强调的是只在内核态运行,因此没有用户态地址空间信息
- 内核级线程强调的是该线程由内核创建与管理,但是可以在用户态运行
4.2.2 用户栈与内核栈的关联
1. 如上文所述,内核级线程同时有用户栈和内核栈,并且依靠内核栈完成切换。那么很自然地,随着内核级线程和内核栈的切换,用户栈也需要随之切换,所以需要将两个栈关联起来

2. 在IA-32体系结构中,关联用户栈与内核栈的工作主要由体系结构完成。当用户级线程因中断或异常从用户态陷入内核态时,处理器会从TSS段中选择特权级3的栈段(内核栈),同时将特权级0的栈段(用户栈)信息保存在内核栈中
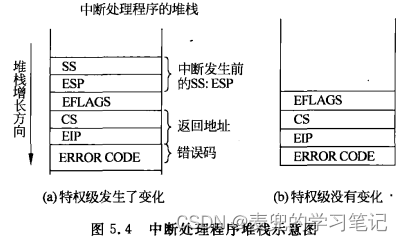
3. 这样就实现了用户栈与内核栈的关联,此时只要切换了内核栈,用户栈也就随之切换
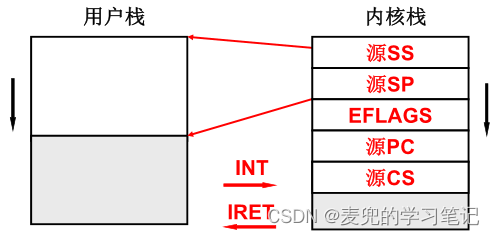
关于IA-32体系结构保护模式下栈段的使用,可参考
Linux操作系统原理与应用05:中断和异常 chapter 5
保护模式下的80386及其编程04:中断及异常 chapter 6
说明:通过系统调用陷入内核态栈状态示例
4.2.3 内核级线程切换五段论
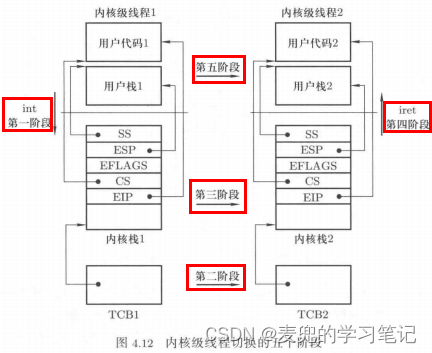
4.2.3.1 陷入内核态
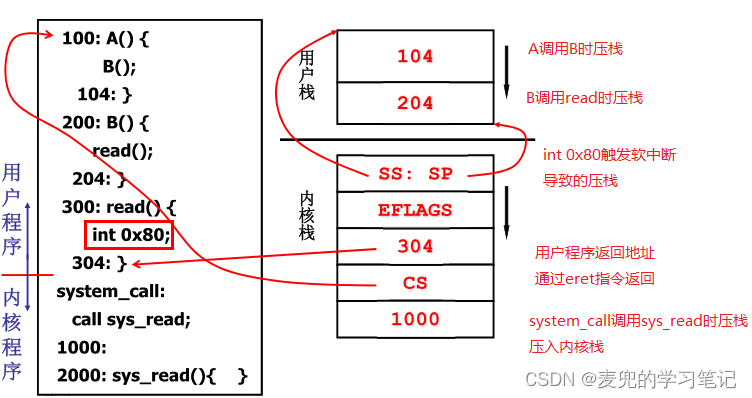
1. 由于内核级线程的切换需要在内核态进行,因此首先需要从用户态陷入内核态,在IA-32 + Linux中一般通过如下方式实现,
① 使用int 0x80触发系统调用(int 0x80本质上属于陷阱异常)
② 通过系统异常
② 通过外设硬件中断
2. 在陷入内核态的中断处理入口,核心工作是保存当前线程在用户态执行的信息。由于处理器硬件只是完成了栈的切换,并且将用户栈 / 用户程序位置 / EFLAGS寄存器的值压栈。因此需要在中断处理入口中进一步保存相关信息,以Linux 0.11内核中处理系统调用的中断处理入口为例,此处进一步保存了段寄存器和通用寄存器的值

说明:在处理系统调用的中断处理入口没有保存EAX寄存器,是因为此时通过EAX寄存器传递系统调用号,在处理过程中无需保存
3. 在进一步保存了线程在用户态执行的现场后,就可以使用寄存器来执行内核态中断处理程序。同样以Linux 0.11内核中处理系统调用的中断处理入口为例,在现场保存完成后,即可以将段寄存器指向内核段,从而调用内核态的系统调用服务例程
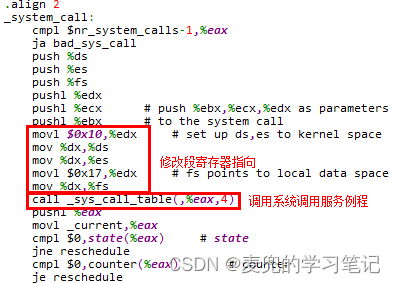
说明:如果在中断触发时,线程已经在内核态运行(e.g. 在系统调用处理过程中有中断触发),则没有从用户态陷入内核态的步骤
4.2.3.2 线程调度
1. 线程调度的目的是选择下一个要执行的线程,并获取该线程的TCB。有关线程调度的详细内容,见下文分析
2. 在Linux内核中,线程调度在schedule函数中进行
说明:在schedule函数中会调用switch_to函数,实现线程的切换
4.2.3.3 内核栈切换
内核栈切换的操作与用户栈切换类似,伪代码如下,
// current指向当前内核级线程的TCB
// next指向下一个要执行的内核级线程的TCB
// 将当前的ESP寄存器值保存在current指向的TCB中
current->esp = esp;
// 从next指向的TCB中取出esp字段赋值给ESP寄存器
esp = next->esp;4.2.3.4 内核态执行流切换
1. 内核态执行流的切换也是通过ret指令完成,在完成内核栈切换后,切换后的内核栈栈顶保存着切换目标线程之前在内核态被切换走时保存的内核现场
通过ret指令将栈顶元素出栈到EIP寄存器,就实现了内核态执行流的切换
2. 下面以IA-32 + Linux 2.4内核为例,说明内核态执行流的切换过程。没有选择Linux 0.11内核进行说明,是因为Linux 0.11内核使用TSS段(而不是内核栈)完成进程切换

schedule函数在调用switch_to函数时传递的参数,分别指向切换前后线程的TCB(task_struct结构)。其中prev指向当前线程,next指向下一个要执行的线程

此处的switch_to函数先后完成了内核栈切换与内核态执行流切换,具体分析如下,
#define switch_to(prev,next,last) do {
asm volatile(
// 将esi / edi / ebp寄存器压栈保存
// 保存在prev线程内核栈中
"pushl %%esi\n\t"
"pushl %%edi\n\t"
"pushl %%ebp\n\t"
// 内核栈切换
// movl esp, prev->thread.esp
// movl next->thread.esp, esp
"movl %%esp,%0\n\t"
"movl %3,%%esp\n\t"
// 保存prev线程执行断点,即标号1位置处
// mov $1f, prev->thread.eip
"movl $1f,%1\n\t"
// 准备next线程执行断点,压入当前内核栈中(也就是next线程的内核栈)
// 后续通过一条ret指令,即可以恢复next线程执行断点
// next线程的执行断点也是标号1位置处,由next线程之前调用schedule时保存
// pushl next->thread.eip
"pushl %4\n\t"
// 内核态执行流切换
// 通过jmp指令跳转到__switch_to函数执行,该函数的右括号被编译为ret指令
// 该ret指令会将最后压栈的next->thread.eip出栈到EIP寄存器中
// 从而实现内核态执行流切换
"jmp __switch_to\n"
"1:\t"
// 此时执行的已经是next线程
// 从next线程内核栈中恢复ebp / edi / esi寄存器
"popl %%ebp\n\t"
"popl %%edi\n\t"
"popl %%esi\n\t"
// 0号参数,prev->thread.esp,前一线程内核栈,存储在内存中,只写
// 1号参数,prev->thread.eip,前一线程执行断点,存储在内存中,只写
:"=m" (prev->thread.esp),"=m" (prev->thread.eip),
// 2号参数,存储在ebx寄存器中,只写
"=b" (last)
// 3号参数,next->thread.esp,下一线程内核栈,存储在内存中
// 4号参数,next->thread.eip,下一线程执行断点,存储在内存中
:"m" (next->thread.esp),"m" (next->thread.eip),
// 5号参数,前一线程TCB,存储在eax寄存器中
// 6号参数,下一线程TCB,存储在edx寄存器中
"a" (prev), "d" (next),
// 7号参数,前一线程TCB,存储在ebx寄存器中
"b" (prev));
} while (0)说明:如何向__switch_to函数传递参数?
__switch_to函数在声明时使用FASTCALL修饰,本质上是使用GCC的regparm(3)属性对函数声明进行修饰,表示函数会用3个寄存器(EAX / EDX / ECX)来传递参数,其余的参数通过栈进行传递
![]()

结合swtich_to函数的实现,此处使用EAX传递prev指针,使用EDX传递next指针
4.2.3.5 中断返回(用户态执行流切换)
1. 用户态执行流切换通过iret指令完成,在调用iret指令之前,需要将内核栈先恢复为如下形式,也就是线程从用户态陷入内核态时处理器保存的栈状态
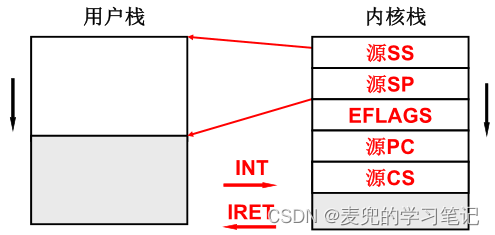
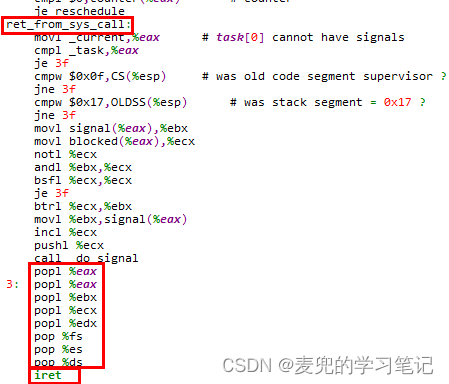
2. 由于在中断处理入口会进一步保存线程在用户态执行的信息,因此在调用iret指令之前,需要从栈中弹出这些信息,以恢复线程在用户态的执行状态。但是需要注意的是,此时恢复的是切换后内核线程的用户态执行状态
同样以Linux 0.11内核中处理系统调用的中断处理程序为例,在调用iret指令返回用户态之前,会使用pop指令将之前用push指令压栈保存的数据弹出,用于恢复现场
4.3 内核级线程创建
创建内核级线程就是人为构造内核线程第一次被切换执行时的场景,如下图所示,

相应的伪代码如下,
void ThreadCreate(parameter)
{
// 分配内核级线程TCB,只能在内核态分配
TCB *tcb = kmalloc(TCB_SIZE);
// 分配内核栈,并且将stack指针指向栈顶(满减栈)
long *stack = kmalloc(STACK_SIZE) + STACK_SIZE;
// 对应从用户态陷入内核态时,处理器切换到内核栈并压栈的内容
// 在中断处理程序调用iret返回用户态之前,内核栈必须是如下状态
*(--stack) = 用户栈段选择子(用户数据段)
*(--stack) = 用户栈指针(可以由ThreadCreate函数的参数传入)
*(--stack) = 用户态初始EFLAGS
*(--stack) = 用户代码段选择子(用户代码段)
*(--stack) = 用户程序入口地址(可以由ThreadCreate函数的参数传入)
// 用户态初始状态,对应中断处理函数返回前的出栈操作
*(--stack) = eax;
*(--stack) = ebx;
...
// 内核态执行流切换目的地址
*(--stack) = 内核态执行流切换目的地址;
// 关联TCB与内核栈
tcb->esp = stack;
}说明1:用户栈的分配与初始化
① 在上述伪代码中,用户栈通过ThreadCreate函数传入,而且用户态已被初始化
② 在实际实现中,用户栈需要在新创建线程的用户地址空间中分配
说明2:用户态初始状态如何恢复?
① 在创建内核级线程时,用户态初始状态已经被压入内核栈,因此需要配合中断返回前的状态恢复操作进行恢复,例如系统调用处理的返回部分

② 也可以专门实现一个内核级线程首次被调度时的内核态执行流切换目的函数,在该函数中完成用户态初始状态恢复并进行中断返回
5 Linux 0.11进程操作实例
5.1 进程操作基础设施简介
说明:与IA-32体系结构中GDT / LDT / TSS机制相关的内容可参考如下笔记,本文不再赘述,只说明与进程操作相关的部分
5.1.1 GDT布局与使用
5.1.1.1 GDT存储
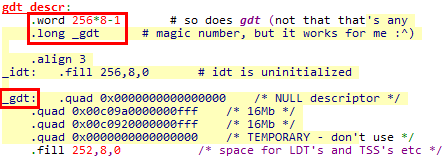
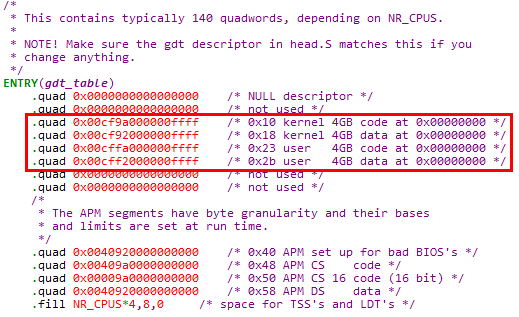
1. Linux 0.11最终使用的GDT表在boot/head.s中定义,线性基地址为_gdt标号,表界限为256项。其中前4项在GDT定义中已经设置,后续252项先填充为全0(导致表项中的P位为0,即表项不存在)
这样做的好处是,后续表项可以随着进程的创建填充,但是无需再重新加载GDT
2. 在C语言中访问GDT时,使用数组名gdt,在数组名在include/linux/head.h中声明。gdt数组共256个成员,每个成员8B(即一个描述符的长度)

说明1:内核代码段

① DT = 1 & TYPE = 0b1010 & DPL = 0
存储段描述符,内核代码段(可执行、可读、非依从)
② Base = 0x0,内核代码段线性基地址为0x0
③ G = 1 & Limit = 0x00FFF,内核代码段长度为16MB
④ 内核代码段的段选择子为0x08
说明2:内核数据段
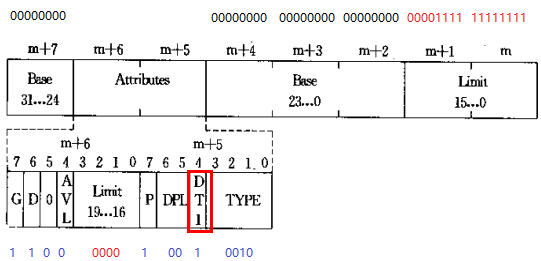
① DT = 1 & TYPE = 0b0010 & DPL = 0
存储段描述符,内核数据段(可读可写,向上扩展)
② Base = 0x0,内核代码段线性基地址为0x0
③ G = 1 & Limit = 0x00FFF,内核代码段长度为16MB
④ 内核代码段的段选择子为0x10
5.1.1.2 GDT布局
Linux 0.11中GDT与LDT的总体布局如下图所示,由GDT映射的地址空间为全局地址空间,由LDT映射的地址空间为每个任务的局部地址空间

5.1.1.3 构造与登记GDT段描述符
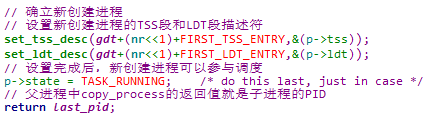
随着进程的创建,相应的LDT段和TSS段表项将被填充到GDT中,该操作通过set_tss_desc & set_ldt_desc宏实现
文件:include/asm/system.h

5.1.1.3.1 set_tss_desc宏调用分析
set_tss_desc宏共2处调用点,
1. 在sched_init函数中设置0号任务的TSS段描述符

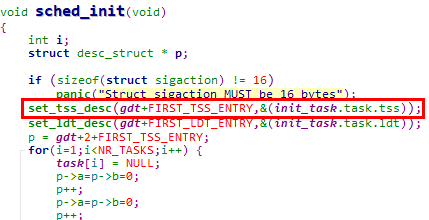
2. 在copy_process函数中设置新创建进程的TSS段描述符,其中nr为新创建进程的PID

可见调用set_tss_desc宏的参数如下,
1. TSS段描述符在GDT中的线性地址
① 由于数组名gdt的类型为struct desc_struct *,因此算术运算的步长为struct desc_struct结构体的长度
② 对于每个进程,进程对应的TSS段描述符表项在GDT中的索引为(4 + PID * 2)
2. TSS段的线性基地址
说明:此处可以直接取task_struct中tss结构体的地址作为TSS段的线性基地址,用于构造TSS段描述符。是因为在系统启动阶段,分段机制对内核态使用了平坦模型,且分页机制对16MB内存进行了恒等映射
可参考Linux 0.11内核分析02:系统启动 chapter 3.4.4 & 3.4.7
5.1.1.3.2 set_ldt_desc宏调用分析
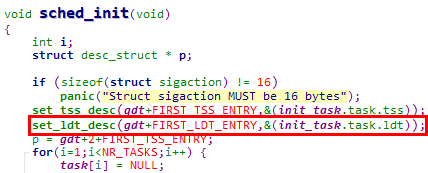
set_ldt_desc宏的调用点与set_ldt_desc宏在一起,
1. 在sched_init函数中设置0号任务的LDT段描述符

2. 在copy_process函数中设置新创建进程的LDT段描述符,其中nr为新创建进程的PID
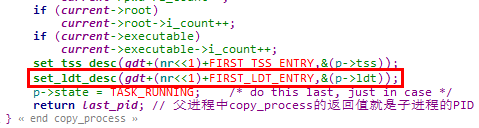
调用set_tss_desc宏的参数如下,
1. LDT段描述符在GDT中的线性地址
对于每个进程,进程对应的LDT段描述符表项在GDT中的索引为(5 + PID * 2)
3. LDT段的线性基地址
5.1.1.3.3 _set_tssldt_desc宏实现分析
set_tss_desc & set_ldt_desc宏最终调用_set_tssldt_desc宏实现功能,只是构造的系统段描述符类型不同,_set_tssldt_desc宏将按系统段描述符格式组装各参数
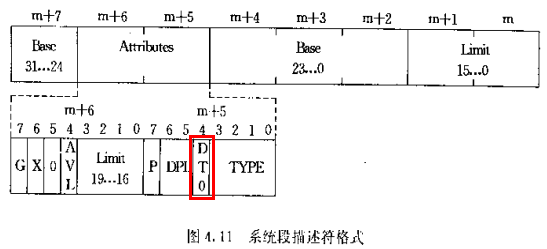
具体的构造过程分析如下,
// n:TSS段或LDT段描述符在GDT中的线性地址
// addr:TSS段或LDT段的线性基地址,填入系统段描述符的Base字段
// type:系统段描述符类型,填入系统段描述符的Attribute字段的第m+5字节
#define _set_tssldt_desc(n,addr,type) \
__asm__ (
// 将104写入Limit字段,写入2B,这是不包含IO许可位图的TSS段界限
"movw $104,%1\n\t" \
// 将TSS段或LDT段的线性基地址写入(m + 2)Base字段,写入2B
// 线性基地址共4B,此处使用ax寄存器,因此写入的是低2B
"movw %%ax,%2\n\t" \
// 将线性基地址的高2B循环移位到eax寄存器的低16位,也就是ax寄存器中
"rorl $16,%%eax\n\t" \
// 将线性基地址的第3B写入(m + 4)Base字段,写入1B
"movb %%al,%3\n\t" \
// 将系统段描述符类型写入Attribute字段低字节
"movb $" type ",%4\n\t" \
// 将0写入Attribute字段高字节
"movb $0x00,%5\n\t" \
// 将线性基地址的第4B写入(m + 7)Base字段,写入1B
"movb %%ah,%6\n\t" \
// 再次循环右移eax寄存器,恢复传入的线性基地址
// 此处将eax寄存器的值恢复,应该是因为没有在内嵌汇编的破坏部分描述eax的值会被破坏
"rorl $16,%%eax" \
// 0号参数:TSS段或LDT段的线性基地址,存储在eax寄存器
// 1号参数:系统段描述符在GDT中的线性地址m字节,Limit字段
// 2号参数:系统段描述符在GDT中的线性地址m + 2字节,Base字段
// 3号参数:系统段描述符在GDT中的线性地址m + 4字节,Base字段
// 4号参数:系统段描述符在GDT中的线性地址m + 5字节,Attribute字段,低字节
// 5号参数:系统段描述符在GDT中的线性地址m + 6字节,Attribute字段,高字节
// 6号参数:系统段描述符在GDT中的线性地址m + 7字节,Base字段
::"a" (addr), "m" (*(n)), "m" (*(n+2)), "m" (*(n+4)), \
"m" (*(n+5)), "m" (*(n+6)), "m" (*(n+7)) \
)说明1:之所以可以在set_tss_desc和set_ldt_desc宏中直接使用gdt中各表项的线性地址以及task_struct中的TSS段和LDT段的线性基地址,是因为
① 这些设置均在内核态完成,此时加载的是内核代码段和内核数据段描述符,而这2个描述符基地址均为0,段界限均为16MB(平坦模型)
② 内核的system组件的链接地址从0开始,而且被加载到物理地址0处,而且分页机制也对0 ~ 16MB范围进行了恒等映射。此时链接地址(虚拟地址) = 线性地址 = 物理地址(运行地址)
说明2:系统段描述符类型
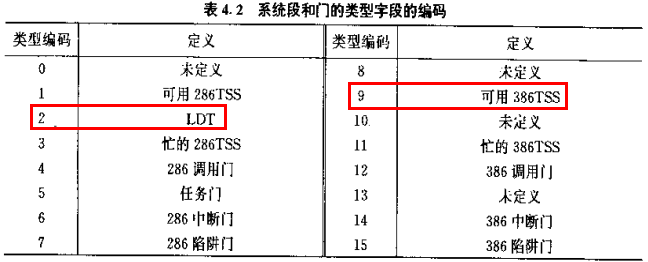
① set_tss_desc宏传递的type字段为0x89,即0b1000 1001,对应可用386TSS段
② set_ldt_desc宏传递的type字段为0x82,即0b1000 0010,对应LDT段
说明3:关于段界限
在_set_tssldt_desc宏中,将TSS段和LDT段描述符的Limit字段都设置为104,这是TSS段的段界限,其实是有些偷懒了~~
5.1.1.4 索引GDT段描述符
5.1.1.4.1 _TSS宏与_LDT宏实现分析
在GDT中构造完TSS段和LDT段描述符之后,就可以用段选择子对其进行索引,段选择子格式如下,

在Linux 0.11内核中,通过_TSS宏和_LDT宏构造段选择子,参数n为进程PID
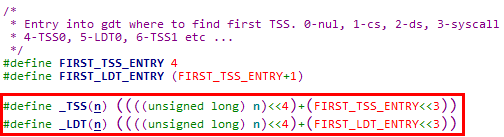
1. 构造的RPL和TI字段均为0,即在内核态加载并且在GDT中进行索引
2. 描述符索引从bit [3]开始,之所以将PID左移4位,是构造描述符索引时需要将PID *2
① TSS段描述符表项在GDT中的索引为(4 + PID * 2)
② 进程对应的LDT段描述符表项在GDT中的索引为(5 + PID * 2)
5.1.1.4.2 _TSS宏调用分析
1. 在ltr宏中使用TSS段选择子设置TR寄存器
![]()
2. 在switch_to宏中设置要切换的目标任务的TSS段选择子,最终会由IA-32基于TSS段的任务切换机制将该选择子设置到TR寄存器中

说明:ltr指令格式与指令执行过程
① ltr指令的格式如下,其中r/m16中存储的是16位TSS段选择子
ltr r/m16 ;ltr bx
;ltr [0x208b]② ltr指令执行过程如下图所示,最终是让TR寄存器可以指向TSS所在的内存段

5.1.1.4.3 _LDT宏调用分析
1. 在lldt宏中使用LDT段选择子设置LDTR寄存器
![]()
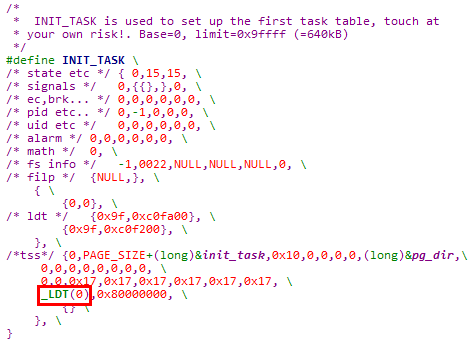
2. 在INIT_TASK宏中设置0号进程TSS段中的LDT段选择子字段
3. 在copy_process函数中设置新创建任务TSS段中的LDT段选择子字段

说明:lldt指令格式与指令执行过程
① lldt指令的格式如下,其中r/m16中存储的是16位LDT段选择子
lldt r/m16 ;lldt dx
;lldt [0x208d]② lldt指令执行过程如下图所示,最终是让LDTR寄存器可以指向LDT所在的内存段
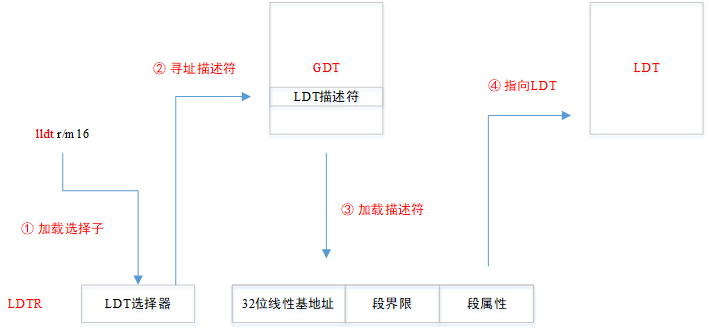
此处再附上在多任务系统中,GDTR / LDTR / TR寄存器的指向关系图

5.1.1.5 全局线性地址空间布局
在说明了GDT的布局与使用之后,就可以得出全局线性地址空间布局如下,
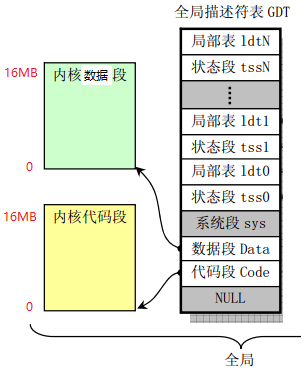
全局线性地址空间只定义了内核代码段和内核数据段,且两个段的范围重叠,均从0到16MB,因此在内核态的分段机制中使用了平坦模型
5.1.2 LDT布局与使用
5.1.2.1 LDT存储与布局
1. 与GDT不同,GDT是全局使用一份,而LDT是每个进程持有一份,用于描述进程自己的局部地址空间布局
2. 在Linux 0.11内核中,进程的LDT存储在task_struct结构的ldt字段,每个进程的LDT表中包含3个表项
① 空表项
② 用户代码段
③ 用户数据段

5.1.2.2 构造与登记LDT段描述符
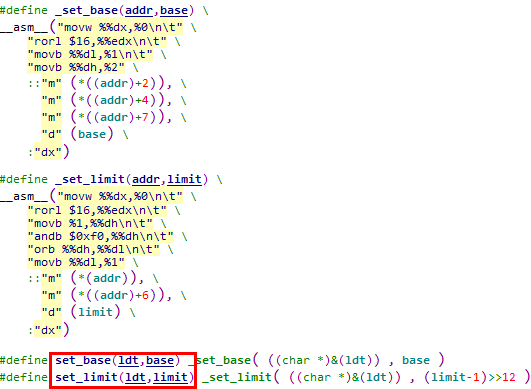
Linux 0.11内核中用于操作LDT段描述符的宏如下图所示,即set_base / set_limit / get_base / get_limit
文件:include/linux/sched.h

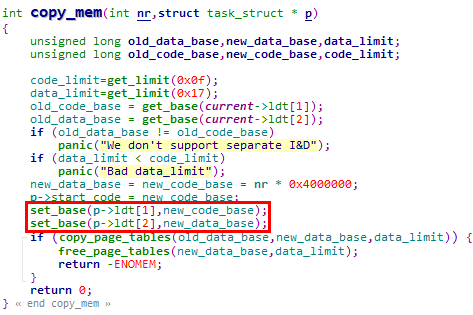
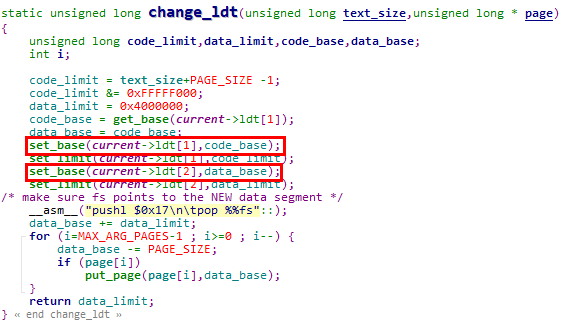
5.1.2.2.1 set_base宏调用分析
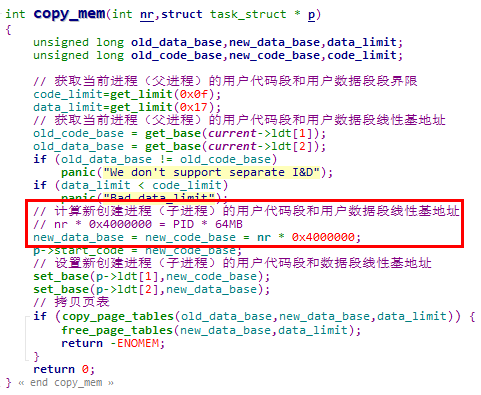
1. 在copy_mem函数中设置新创建进程的LDT表项(copy_mem函数被copy_process函数调用)
2. 在change_ldt函数中设置执行execve系统调用进程的LDT表项(change_ldt函数被do_execve函数调用)
5.1.2.2.2 _set_base宏实现分析
set_base宏最终调用_set_base宏实现功能,_set_base宏按存储段描述符格式设置其中的Base字段

具体实现过程分析如下,
#define _set_base(addr,base) \
__asm__(
// 将存储段线性基地址低2B写入段描述符(m + 2)Base字段,写入2B
"movw %%dx,%0\n\t" \
// 将存储段线性基地址的高2B循环移位到edx寄存器的低16位,也就是dx寄存器中
"rorl $16,%%edx\n\t" \
// 将存储段线性基地址的第3B写入(m + 4)Base字段,写入1B
"movb %%dl,%1\n\t" \
// 将存储段线性基地址的第4B写入(m + 7)Base字段,写入1B
"movb %%dh,%2" \
// 0号参数,存储段描述符在LDT中线性地址m + 2字节,Base字段
::"m" (*((addr)+2)), \
// 1号参数,存储段描述符在LDT中线性地址m + 4字节,Base字段
"m" (*((addr)+4)), \
// 2号参数,存储段描述符在LDT中线性地址m + 7字节,Base字段
"m" (*((addr)+7)), \
// 3号参数,存储段线性基地址,存储在edx寄存器
"d" (base) \
// 会破坏edx寄存器中的值
:"dx")说明:set_base宏调用_set_base宏的方式如下,&ldt是取得一个LDT中段描述符表项的地址
![]()
此处之所以可以直接使用一个LDT中段描述符表项的地址(是一个链接地址 / 虚拟地址),是因为
① LDT段包含在task_struct结构中,是在内核空间分配的
② 而内核镜像链接地址从0开始,以及内核空间的平坦模型(是的链接地址 / 虚拟地址 = 线性地址) + 恒等映射(使得线性地址 = 物理地址 / 运行地址)确保了在内核态可以直接访问
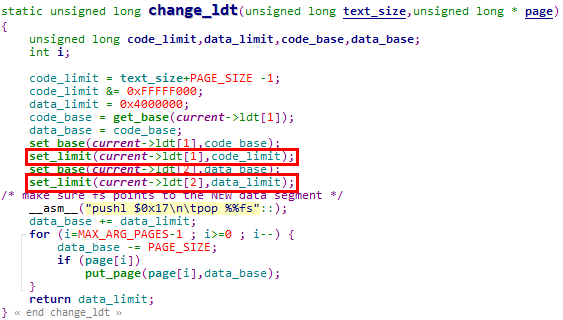
5.1.2.2.3 set_limit宏调用分析
在change_ldt函数中设置执行execve系统调用进程的LDT表项(change_ldt函数被do_execve函数调用)
说明:为什么在copy_mem函数中不用设置LDT表项的段界限?
① 在通过fork系统调用创建进程时,子进程拷贝父进程的用户线性地址空间
② 但是在Linux 0.11内核中,不同进程的用户线性地址空间起始地址不同,因此在copy_mm函数中只调用set_base宏设置了新进程用户线性地址空间的起始地址,而无需设置段界限

5.1.2.2.4 _set_limit宏实现分析
#define _set_limit(addr,limit) \
__asm__(
// 将存储段界限值低2B写入段描述符(m)Limit字段,写入2B
"movw %%dx,%0\n\t" \
// 将存储段界限值高2B循环移位到edx寄存器的低16位,也就是dx寄存器中
// 段界限的有效内容在dl寄存器中,也就是dx寄存器的低8位中
"rorl $16,%%edx\n\t" \
// 将段描述符(m + 6)字节读入dh寄存器
"movb %1,%%dh\n\t" \
// 将读入的段描述符(m + 6)字节的低4位清零
// 也就是将原先Attribute字段中的4位Limit信息清零
"andb $0xf0,%%dh\n\t" \
// 设置Attribute字段中的4位Limit信息
"orb %%dh,%%dl\n\t" \
// 将组装好的dl寄存器值写入段描述符(m + 6)Attribute字段
"movb %%dl,%1" \
// 0号参数,存储段描述符在LDT中线性地址m字节,Limit字段
::"m" (*(addr)), \
// 1号参数,存储段描述符在LDT中线性地址m + 6字节,Attribute字段,其中包含Limit信息
"m" (*((addr)+6)), \
// 2号参数,存储段界限值,存储在edx寄存器
"d" (limit) \
// 会破坏edx寄存器中的值
:"dx")说明:set_limit宏调用_set_limit宏的方式如下,需要注意2点
![]()
① 此处的&ldt也是取得一个LDT中段描述符表项的地址,可以使用的原因与set_base宏的说明相同
② 调用set_limit宏时的段界限单位是字节,在调用_set_limit宏时,需要将其转换为以4KB为单位
对于向上扩展且粒度为4KB的数据段,实际使用的段界限值按如下方式计算。因此在调用_set_limit宏时,是先将以字节为单位的limit – 1,再除以4KB
描述符中的段界限 * 0x1000 + 0xFFF5.1.2.2.5 get_base宏调用与实现分析
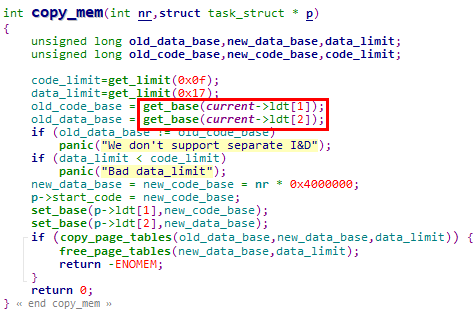
1. get_base宏用于获取LDT中存储的段描述符的Base字段,在代码中多处被调用。以copy_mm函数为例,使用get_base宏取出当前进程的用户代码段和用户数据段线性基地址
2. get_base宏通过_get_base宏实现功能,是一个拼接段描述符中Base字段的过程
#define _get_base(addr) ({\
unsigned long __base; \
__asm__(
// 将Base[31:24]读取到dh寄存器,读取1B
"movb %3,%%dh\n\t" \
// 将Base[23:16]读取到dl寄存器,读取1B
// 此时dx寄存器中保存了Base[31:16]
"movb %2,%%dl\n\t" \
// 将dx中的Base[31:16]左移到edx寄存器的高16位
"shll $16,%%edx\n\t" \
// 将Base[15:0]读取到dx寄存器,读取2B
"movw %1,%%dx" \
// 0号参数,输出部分,__base变量保存在edx寄存器中
:"=d" (__base) \
// 1号参数,(m + 2)Base字段,2B
:"m" (*((addr)+2)), \
// 2号参数,(m + 4)Base字段,1B
"m" (*((addr)+4)), \
// 3号参数,(m + 7)Base字段,1B
"m" (*((addr)+7))); \
// 最后返回的是__base变量,此时该变量中已包含存储段的线性基地址
__base;})说明:get_base宏调用_get_base宏的方式如下,还是传递LDT中段描述符的地址
![]()
5.1.2.2.6 get_limit宏调用与实现分析
1. get_limit宏用于获取LDT中存储的段描述符的Limit字段,在代码中多处被调用。以copy_mm函数为例,使用get_limit宏获取当前进程的用户代码段和用户数据段的段界限
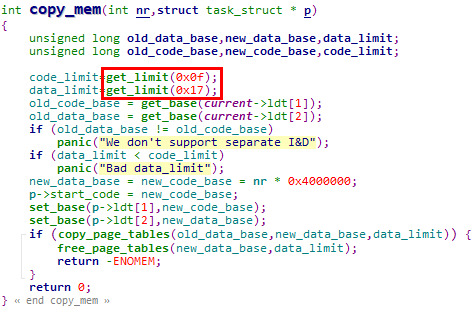
2. get_limit宏通过LSL(Load Segment Limit)指令实现,指令的参数为段选择子。LSL指令从段选择子索引的段描述符中取出分散的段界限,并且拼接成完整的段界限值存储在指定的寄存器中


3. 在调用get_limit宏时,传递的段选择子只有2个,
① 0xf:0b1[index] 1[TI] 11[RPL],即用户代码段选择子
② 0x17:0b10[index] 1[TI] 11[RPL],即用户代码段选择子
需要特别注意的是,由于传递的是用户代码段和数据段的段选择子,因此只能获取LDTR指向的LDT中的段描述符Limit字段,也就是只能获取当前任务的用户代码段或用户数据段段界限(在Linux 0.11内核代码中,也确实只有获取当前任务用户段界限的需求)
最为对比,set_base / set_limit / get_limit宏可以通过task_struct结构操作非当前任务的指定任务
5.1.2.3 索引LDT段描述符
由于LDT中有效的局部段描述符只有用户代码段和用户数据段,所以直接使用对应的段选择子索引。如上文所述,0xf索引用户代码段,0x17索引用户数据段,而且只能索引当前任务(本质上是LDTR寄存器指向的LDT)

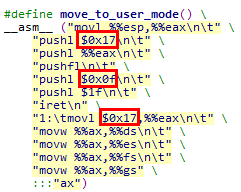
说明:Linux 0.11内核通过段选择子直接索引LDT段实例
在move_to_user_mode宏中,将当前进程(0号进程)的用户数据段和用户代码段段选择子压栈,构造异常返回场景,从而实现从内核态向用户态的返回
5.1.2.4 局部线性地址空间布局
说明:需要特别注意的是,局部线性地址空间是进程在用户态运行时使用。当进程因中断或异常陷入内核态执行时,会切换段选择子,使用全局线性地址空间
5.1.2.4.1 0号进程局部线性地址空间布局
0号进程的局部线性地址空间通过INIT_TASK宏静态创建,
![]()

1. 0号进程用户代码段
存储段描述符:0x00c0fa00_0000009f

① DT = 1 & TYPE = 0b1010 & DPL = 3
存储段描述符,用户代码段(可执行、可读、非依从)
② Base = 0x0,0号进程用户代码段线性基地址为0x0
③ G = 1 & Limit = 0x0009F,0号进程用户代码段长度为640KB
2. 0号进程用户数据段
存储段描述符:0x00c0f200_0000009f
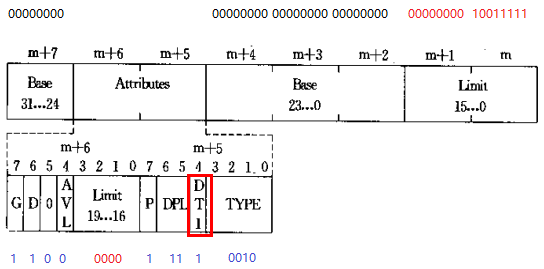
① ① DT = 1 & TYPE = 0b0010 & DPL = 3
存储段描述符,用户数据段(可读可写,向上扩展)
② Base = 0x0,0号进程用户数据段线性基地址为0x0
③ G = 1 & Limit = 0x0009F,0号进程用户数据段长度为640KB
说明1:为什么0号进程的用户代码段和用户数据段只有640KB?
① 0号进程是由内核启动后通过move_to_user_mode宏切换状态生成,本质上就是内核镜像本身
② 在系统启动阶段,内核镜像所在的system组件最大长度为192KB(可参考02. 系统启动 chapter 1.3.4)
③ 在IA-32体系结构起始1MB的memory map中,内存使用0x0 ~ 0x9FFFF的640KB,这就是0号进程用户代码段和用户数据段长度只有640KB的由来

说明2:由上述分析可见,每个进程LDT描述的进程局部线性地址空间也使用平坦模型
5.1.2.4.2 其他进程局部线性地址空间布局
在Linux 0.11内核中,其他进程使用fork系统调用创建,在创建进程的过程中,copy_process函数会调用copy_mem函数拷贝父进程的用户态线性地址空间

在copy_mm函数中会设置新创建进程的用户代码段和用户数据段线性基地址
5.1.2.4.3 局部线性地址空间总体布局
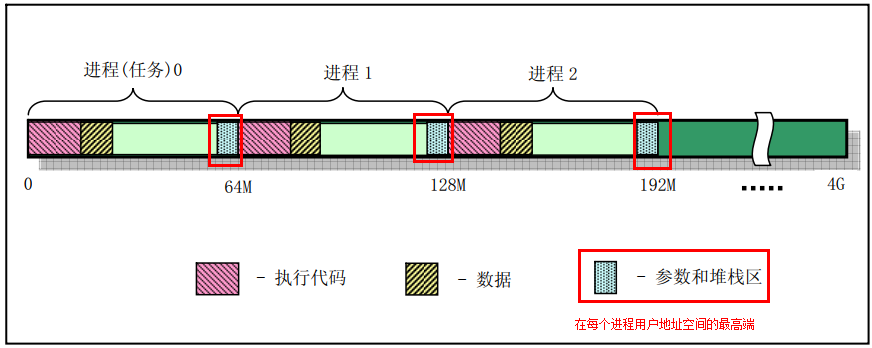
1. 由上述分析可见,在Linux 0.11内核中,最多有64个任务,每个任务的局部线性地址空间为64MB,正好划分4GB的CPU线性地址空间
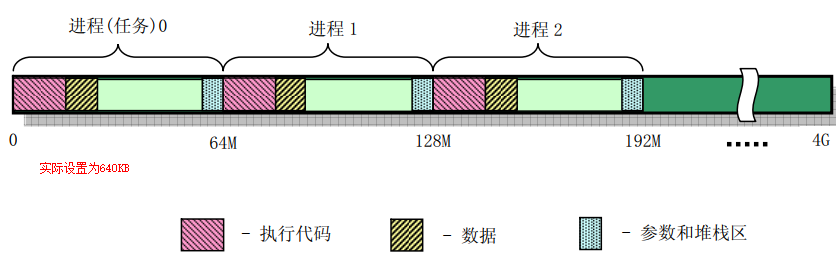
2. 结合GDT与LDT的布局,Linux 0.11内核中完整的全局线性地址空间和局部线性地址空间布局如下

说明1:Linux 0.11内核划分局部线性地址空间带来的特性
① 由于是所有64个任务划分4GB线性地址空间,因此可以只使用一个页目录和一套页表。当进程切换时,其实无需切换CR3寄存器
但是在Linux 0.11内核中,由于使用TSS段机制实现进程切换,所以还是会随着进程的切换重新设置CR3寄存器。只不过在Linux 0.11内核中,不同进程写入CR3寄存器的值是相同的,都是pg_dir标号的线性地址
② 当进程因中断或异常陷入内核态时,会切换段选择子,使用全局线性地址空间。全局线性地址空间的范围为0 ~ 16MB,而此时使用的页表就是进程0的页表
进程0的页表在系统启动阶段创建,该页表对0 ~ 16MB物理内存创建了恒等映射,相关内容可参考Linux 0.11内核分析02:系统启动 chapter 3.4.7
③ Linux 0.11内核这种划分局部线性地址空间的缺点也是很明显的,就是每个进程可使用的用户线性地址空间被限制在64MB。这在Linux 0.11的时代是可行的,但是明显无法支持后续应用程序对用户线性地址空间的的需求
说明2:后续Linux内核版本的改进
① 以Linux 2.4内核为例,在GDT中创建了内核代码段 / 内核数据段 / 用户代码段 / 用户数据段的段描述符,而且线性地址范围均为0 ~ 4GB
也就是说,每个进程都有完整的4GB线性地址空间,不再是划分线性地址空间
② 由于每个进程都有4GB线性地址空间,因此不再实际使用LDT机制
③ 由于每个进程的线性地址空间是重叠的,所以每个进程需要有自己的页目录和页表集,切换进程时需要设置CR3寄存器以切换页表

5.1.3 TSS及其布局
5.1.3.1 TSS存储
1. 每个进程(任务)都有一个对应的TSS段
2. TSS段存储在task_struct结构体的tss字段,该字段的tss_struct结构体类型按照IA-32体系结构TSS段的要求设置

5.1.3.2 0号进程TSS初值分析
0号进程的TSS段内容在INIT_TASK宏中静态设置,

各字段含义如下,
|
TSS字段 |
值 |
|
前一个任务的指针 back_link |
0 |
|
esp0 |
PAGE_SIZE + (long)&init_task 进程内核栈高端 |
|
ss0 |
0x10,内核数据段 |
|
esp1 |
0,实际未使用 |
|
ss1 |
0,实际未使用 |
|
esp2 |
0,实际未使用 |
|
ss2 |
0,实际未使用 |
|
cr3 |
(long)&pg_dir 页目录线性地址 |
|
eip |
0 |
|
eflags |
0 |
|
eax |
0 |
|
ecx |
0 |
|
edx |
0 |
|
ebx |
0 |
|
esp |
0 |
|
ebp |
0 |
|
esi |
0 |
|
edi |
0 |
|
es |
0x17,用户数据段 |
|
cs |
0x17,用户数据段 |
|
ss |
0x17,用户数据段 |
|
ds |
0x17,用户数据段 |
|
fs |
0x17,用户数据段 |
|
gs |
0x17,用户数据段 |
|
LDT段选择子 ldt |
_LDT(0) 0号进程的LDT段选择子 |
|
IO映射基地址 trace_bitmap |
0x80000000 |
|
i387 |
全零 |
说明:此处将TSS段中的cs初值设置为用户数据段,虽然是不严谨的,但是出于以下2点原因也不会造成问题
① 0号进程目前正在运行,进程状态保存在物理寄存器中,此处0号进程TSS段中的内容会在任务切换时被物理寄存器中的值覆盖
② 在通过fork系统调用创建新的进程时,会使用正确的值设置新创建进程的TSS段
说明2:Linux 0.11内核中将浮点协处理器的上下文信息存储在TSS段中,具体的i387_struct结构体如下
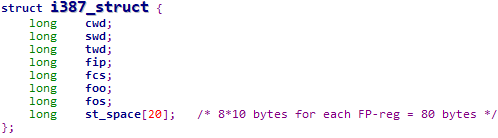
5.2 进程切换
5.2.1 switch_to函数调用分析
1. Linux 0.11内核中使用switch_to函数实现进程切换
2. switch_to函数被schedule函数调用,参数为切换目标进程的PID

5.2.2 switch_to函数实现分析

// n: 切换目标进程的PID
#define switch_to(n) {\
struct {long a,b;} __tmp; \
__asm__(
// 判断要切换的目标进程是否就是当前进程
// 如果是,则直接跳转到标号1处,不进行进程切换
"cmpl %%ecx,_current\n\t" \
"je 1f\n\t" \
// 将目标进程TSS段选择子存储在__tmp.b中
// 也就是__tmp变量的高2B,存储2B
"movw %%dx,%1\n\t" \
// 将current指向切换目标进程
"xchgl %%ecx,_current\n\t" \
// 通过ljmp指令发起基于TSS段的进程切换
"ljmp %0\n\t" \
// 至clts指令,与浮点协处理器相关
"cmpl %%ecx,_last_task_used_math\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
// 0号参数,存储__tmp.a在内存中
// 1号参数,存储__tmp.b在内存中
::"m" (*&__tmp.a),"m" (*&__tmp.b), \
// 2号参数,存储目标进程TSS段选择子,存储在edx寄存器中
// 3号参数,存储目标进程的task_struct结构体指针,存储在ecx寄存器中
"d" (_TSS(n)),"c" ((long) task[n])); \
}
说明:关于__tmp变量与ljmp指令
① 在通过ljmp指令进行基于TSS段的进程切换时,指令格式如下,
ljmp 16位TSS段选择子:将被忽略的32位偏移量也就是说,此时需要48位全指针,其中偏移量在低4B,TSS段选择子在高2B
② 正是根据48位全指针的地址要求,构造了__tmp变量,并且将切换目标进程的TSS段选择子存储在__tmp变量的高2B处
5.2.3 基于TSS段的进程切换过程
如上文所述,基于TSS段进行进程切换时,只需要执行一条ljmp指令,该指令的执行过程如下,
1. 根据TR寄存器,在GDT中找到当前任务的TSS段描述符
2. 根据TSS段描述符找到当前任务TSS段所在的内存区域
3. 将物理CPU中的寄存器值存放在当前任务的TSS段中,相当于给当前任务状态拍摄一个快照
4. 根据ljmp指令的操作数,在GDT中找到目标任务的TSS段描述符
5. 根据TSS段描述符找到目标任务TSS段所在的内存区域
6. 将目标任务TSS段中的内容恢复到物理CPU的寄存器中,相当于恢复目标任务上次被切换走时的状态快照
7. 将TR寄存器只写目标任务的TSS段
5.3 进程创建
5.3.1 进程创建的思路
创建进程一般有2种思路,
1. 完全新建
根据一个进程所需的资源清单,从头创建一个新的进程
2. 拷贝新建
① 以一个已经在运行的进程为模板来创建新的进程,在总体拷贝模板进程资源状态的基础上进行必要的修改
② Linux操作系统使用拷贝新建方案,并通过fork系统调用创建进程
5.3.2 0号进程的静态创建
5.3.2.1 INIT_TASK宏设置0号进程状态

之前已经分析了INIT_TASK宏中的LDT和TSS段部分,下面分析其他字段值
|
task_struct字段 |
值 |
|
进程执行状态 state |
0 TASK_RUNNING |
|
进程时间片 counter |
15 |
|
进程优先级 priority |
15 |
|
信号相关字段 signal / sigaction / blocked |
均为0 |
|
exit_code |
0 |
|
start_code / end_code end_data / brk / start_stack |
均为0 |
|
pid / father / pgrp / session / leader |
0 / -1 / 0 / 0 / 0 |
|
uid / euid / suid |
均为0 |
|
gid / egid / sgid |
均为0 |
|
alarm / utime / stime / cutime / cstime / start_time |
均为0 |
|
used_math |
0 |
|
tty |
-1 表示没有使用tty子设备号 |
|
umask |
0022(八进制) |
|
3个inode pwd / root / executable |
均为NULL |
|
close_on_exec |
0 |
|
打开的文件结构 filp[NR_OPEN] |
均为NULL |
5.3.2.2 sched_init函数确立0号进程
所谓确立0号进程,有2层含义,
1. 在体系结构中注册0号进程的信息
2. 使得体系结构中的系统寄存器指向上面注册的0号进程信息
确立0号进程的工作由sched_init函数完成,在该函数中会注册0号进程的TSS段和LDT段,之后将TR和LDTR寄存器指向注册的信息

说明1:sched_init函数在内核启动阶段被main函数调用

说明2:在sched_init函数中清除了当前EFLAGS寄存器中的NT位
① 首先来回顾下NT控制位的作用
|
NT(Nested Task) 嵌套任务标志位 |
如果NT = 1,则执行任务切换操作 |
② 由于Linux 0.11内核中并没有使用任务门机制,也没有使用call指令 + TSS段机制进行任务切换,所以不会构成任务间的嵌套关系
此处将NT位清零,可以确保后续调用iret指令时进行常规的中断返回操作
5.3.2.3 move_to_user_mode函数将0号进程切换到用户态
1. 0号进程由内核启动阶段的main函数调用move_to_user_mode函数切换到用户态
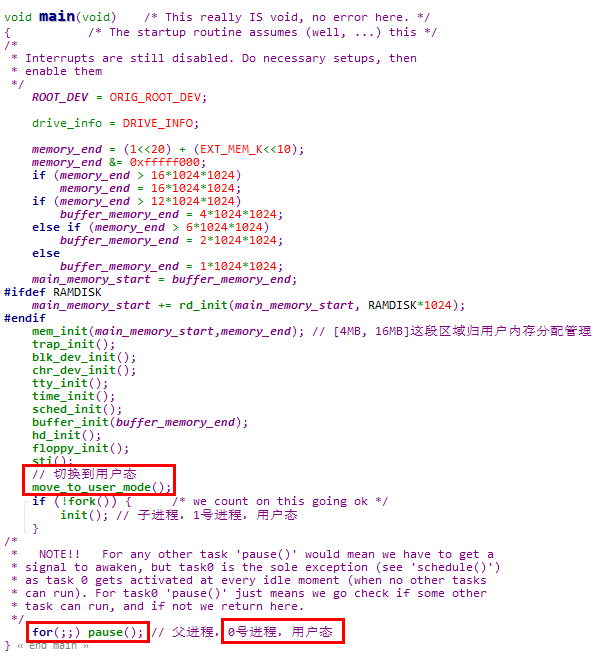
2. 在调用move_to_user_move函数之后,main函数中调用的都是用户态函数,例如fork和pause函数,都是系统调用封装例程

3. move_to_user_mode函数分析如下,
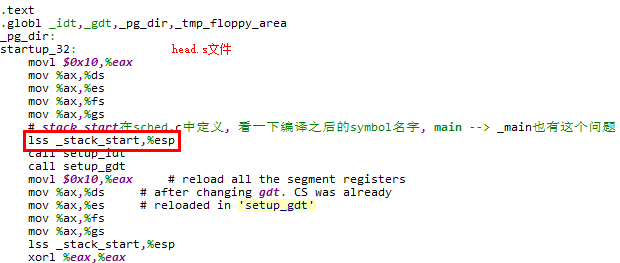
#define move_to_user_mode() \
__asm__ (
// 将栈指针esp保存到eax寄存器
// 当前esp指向0号进程的用户栈user_stack区域,但是是使用内核数据段进行访问
"movl %%esp,%%eax\n\t" \
// 构造异常返回栈
// 将用户态SS段选择子压栈,用户数据段
"pushl $0x17\n\t" \
// 将用户态栈指针esp压栈
"pushl %%eax\n\t" \
// 将EFLAGS寄存器压栈
"pushfl\n\t" \
// 将用户态CS段选择子压栈,用户代码段
"pushl $0x0f\n\t" \
// 将用户态EIP压栈,将标号1逻辑/线性地址压栈
"pushl $1f\n\t" \
// 异常返回,触发特权级和栈的切换
"iret\n" \
// 0号进程切换到用户态后继续运行
// 将DS / ES / FS / GS段寄存器均设置为用户数据段
"1:\tmovl $0x17,%%eax\n\t" \
"movw %%ax,%%ds\n\t" \
"movw %%ax,%%es\n\t" \
"movw %%ax,%%fs\n\t" \
"movw %%ax,%%gs" \
// 破坏部分,会破坏eax寄存器的值
:::"ax")说明1:0号进程的用户栈
① 在main函数调用move_to_user_mode之前,内核启动阶段使用的栈为user_stack。在head.s文件加载user_stack时,使用的SS段选择子为内核数据段,也就是是以内核栈的形式加载的
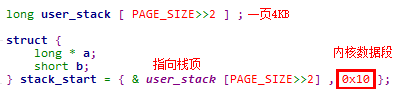
② 在move_to_user_mode函数中,将user_stack切换为0号进程的用户栈,ESP栈指针的值沿用,但是栈段选择子切换为0x17,也就是用户数据段
之所以可以这么做,是因为内核数据段是从0 ~ 16MB,而0号进程的用户数据段为0 ~ 640KB。因此切换栈段选择子之后,经过段机制映射出的栈段线性地址是相同的
说明2:0号进程的内核栈
0号进程的内核栈就是0号进程task_struct结构所在内存页的顶端


5.3.3 fork系统调用分析
5.3.3.1 fork系统调用使用实例
1. 在main函数通过move_to_user_mode函数切换到用户态成为0号进程后,会调用fork系统调用创建1号进程,并在1号进程中执行init函数
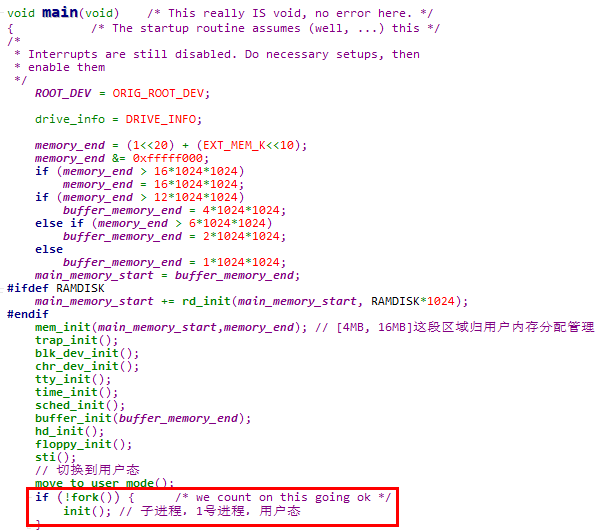
2. 在1号进程中,会调用fork系统调用创建2号进程,并且在2号进程中启动shell
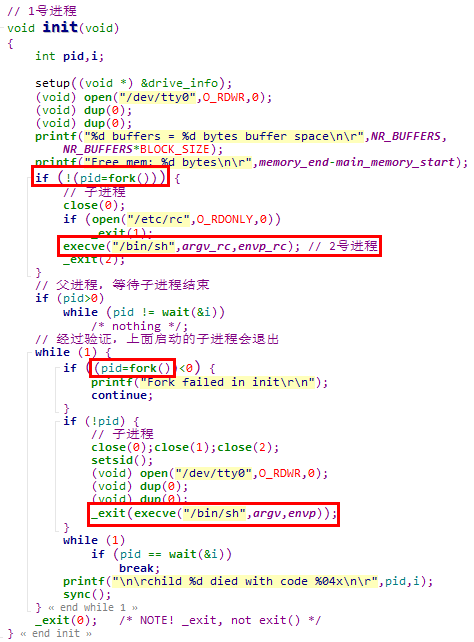
fork函数是fork系统调用的封装例程,fork是一个无参数系统调用

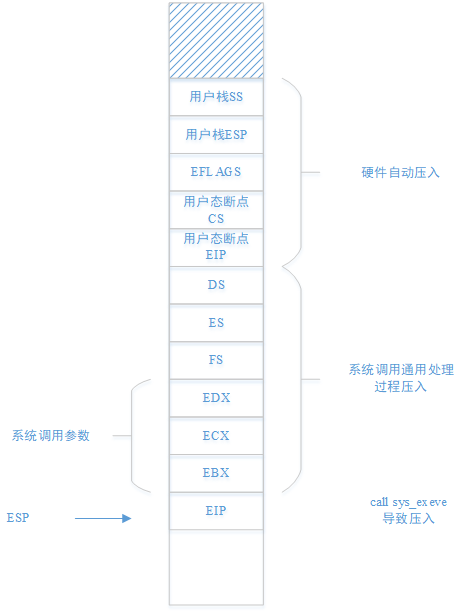
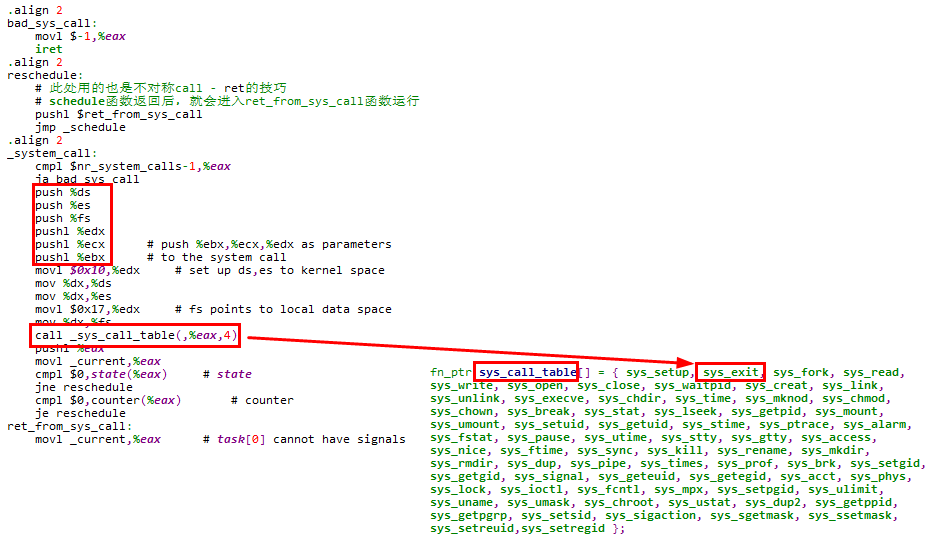
5.3.3.2 系统调用通用处理部分
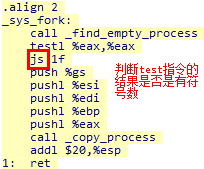
下面是系统调用的通用处理部分,对于fork系统调用,会在进行一系列压栈操作之后调用sys_fork函数
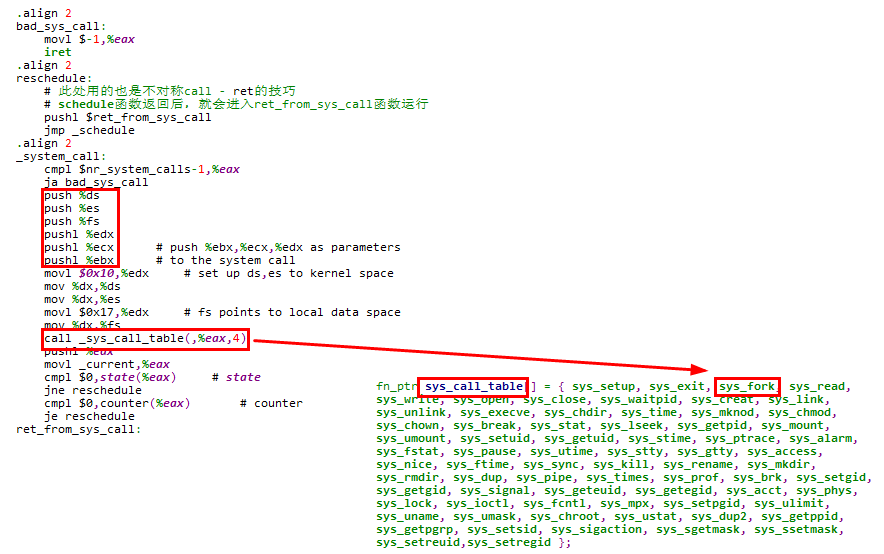
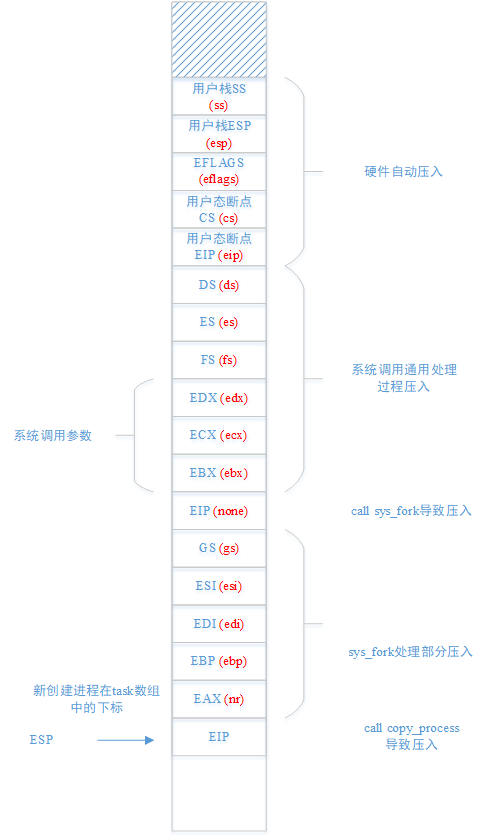
在跳转到sys_fork函数执行时,内核栈状态如下,

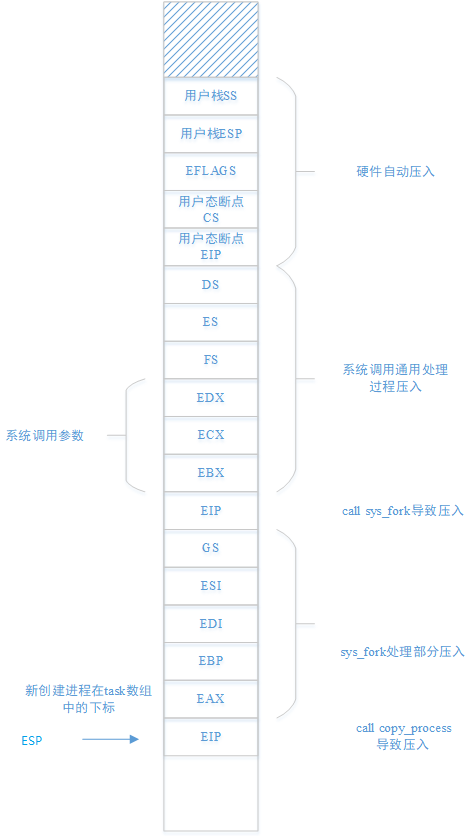
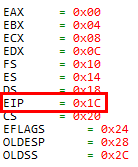
5.3.3.3 sys_fork处理部分
sys_fork函数首先会查找是否有剩余的task_struct可用,如果有,则会进一步压栈,并调用copy_process函数复制进程状态

在跳转到copy_process函数执行时,内核栈状态如下,这些压栈的内容将作为copy_process函数的参数使用
说明:find_empty_process函数完成如下2个任务,
① 查找task数组中的空闲元素,表示系统中还可以创建新的进程(上限为64个)
② 生成新创建进程的PID

如果还可以创建新的进程,则find_empty_process函数的返回值在[1, 63]之间,是一个正数;当task数组已耗尽,无法再创建新的进程时,则返回-EAGAIN,是一个负数
这样就可以理解sys_fork函数对find_empty_process函数返回值的判断了,
5.3.3.4 copy_process函数分析
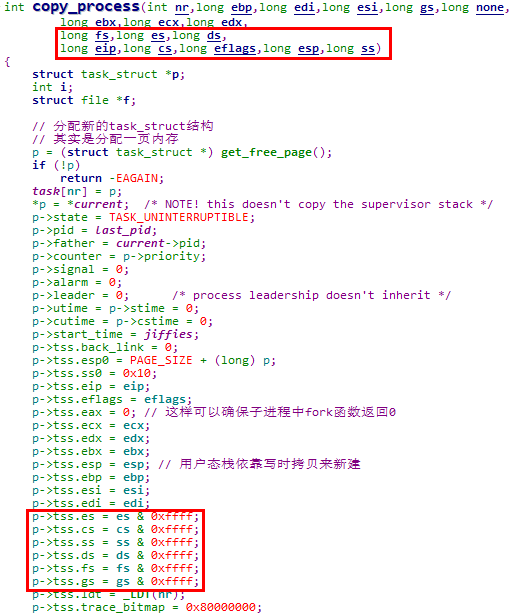
5.3.3.4.1 copy_process函数参数分析
copy_process函数的参数如下图所示,

该函数的参数均从内核栈获取,对应关系如下图所示,可见匹配地完美无缺。这么做的目的,就是从系统寄存器层面复刻父进程的状态
说明1:由于子进程复刻了父进程的用户态断点,后续会设置到子进程TSS段的EIP字段,因此在通过TSS段机制切换到子进程运行时,会从与父进程相同的断点继续执行
而这个断点的位置就是父进程调用fork系统调用封装例程时,int 0x80触发系统调用后的一条指令
说明2:如果不使用TSS段机制进行进程切换
① 此处稍微扩展一下,如果不使用TSS段机制进行进程切换,只保留用户态断点则是不行的。因为使用TSS段机制进行进程切换时,相当于可以同时完成执行流和特权级的切换
例如对于新创建进程的场景,保存的断点信息是在用户态的,但是可以从内核态通过TSS段机制直接切换到新创建进程的用户态执行
② 但是如果不使用TSS段机制进行进程切换,在内核态就需要有内核栈切换和内核态执行流切换的步骤,这就需要在switch_to函数中部署一个内核态执行流的切换点
以Linux 2.4内核的switch_to函数为例,标号1就是这个部署的内核态指令流切换点。在进行内核态的进程切换时,会将标号1的地址保存在前一个进程的thread.eip中。当再次切换到该进程执行时,会将thread.eip中记录的标号1地址压栈,之后通过_switch_to函数右括号编译出的ret指令实现执行流切换

5.3.3.4.2 copy_process函数流程分析
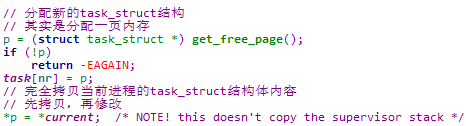
5.3.3.4.2.1 创建task_struct结构
此处是通过get_free_page函数分配一页内存,将其低端作为task_struct结构体使用,高端作为新创建进程的内核栈使用(以联合体的方式共用)
5.3.3.4.2.2 设置新创建进程的task_struct结构
此处需要注意2点,
① 在新创建进程没有设置好之前,进程状态为TASK_UNINTERRUPTIBLE,以避免该进程被调度
② 将新创建进程TSS段中的EAX字段设置为0,这样可以确保子进程返回后,fork系统调用的返回值为0,进而可以通过返回值判断出父子进程

5.3.3.4.2.3 拷贝父进程的用户态线性地址空间
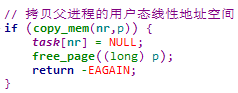
其中的核心操作,就是参考父进程创建子进程的页表,相关内容在后续内存管理章节分析

5.3.3.4.2.4 与父进程共享文件系统信息

5.3.3.4.2.5 确立新创建进程
此处父进程返回的是子进程的PID
5.4 执行程序
通过fork系统调用创建新进程后,由于子进程基本上拷贝了父进程的状态,因此子进程会和父进程执行相同的代码。而我们创建子进程一般是希望执行新的程序,此时就需要使用execv系统调用
5.4.1 execve系统调用使用实例
在1号进程中,会创建新进程,并通过execv系统调用启动shell

execve函数是execve系统调用的封装例程,execve是带有3个参数的系统调用,参数为,
![]()
1. char *file:可执行文件名
2. char **argv:参数字符串数组(char *argv[])
3. char **envp:环境变量字符串数组(char *anvp[])
5.4.2 execve系统调用分析
5.4.2.1 系统调用通用处理部分
系统调用的通用处理部分都是相同的,只是此处调用的是sys_execve函数

在跳转到sys_execve函数执行时,内核栈状态如下,
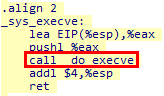
5.4.2.2 sys_execv处理部分
sys_execve函数首先通过LEA指令取出内核栈中保存用户态断点EIP处的有效地址,然后将其压栈,也作为调用do_execve函数的参数
在跳转到do_execve函数执行时,内核栈状态如下,
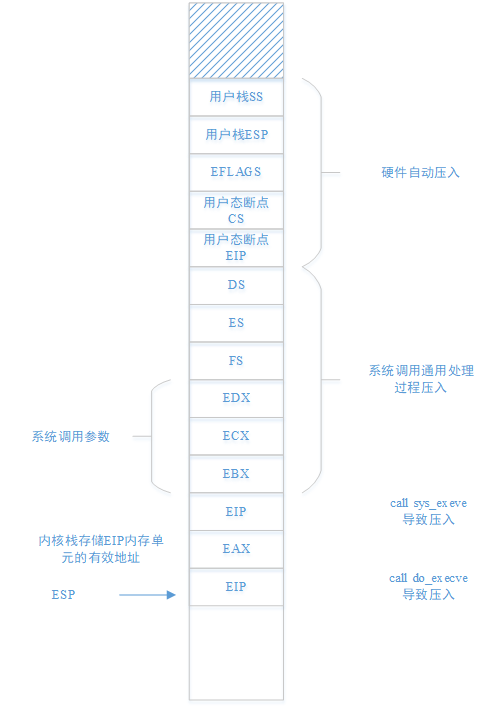
5.4.2.3 do_execve函数分析
5.4.2.3.1 do_execve函数参数分析

该函数的参数均从内核栈获取,对应关系如下图所示,

5.4.2.3.2 do_execve函数流程分析
由于do_execve函数涉及较多内存管理与文件系统的内容,此处仅进行概要说明,详细内容可参考后续笔记
5.4.2.3.2.1 判断调用合法性
eip[1]中保存的是保存在内核栈上的用户态断点CS,应该是0x0f(用户代码段),do_execve函数只允许在用户态调用
此处还计算了命令行参数与环境变量参数的个数
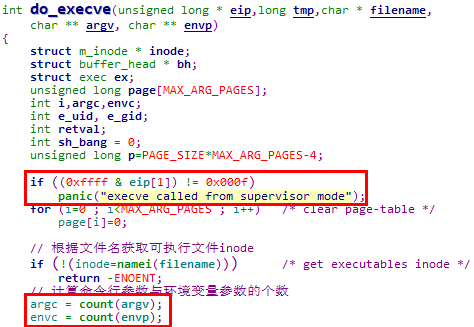
5.4.2.3.2.2 读取可执行文件并处理可执行文件头结构

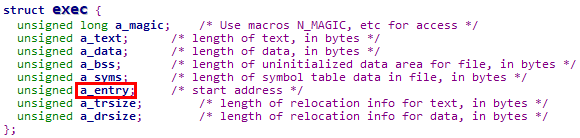
可执行文件头结构如下,其中的a_entry就是可执行文件的入口点
说明:此处只读取了可执行文件的第一块数据,更多的数据将在缺页异常处理中从磁盘读入内存,并创建页表建立映射关系
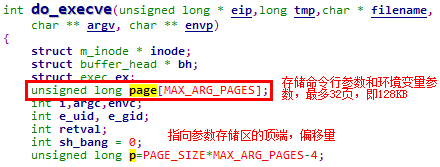
5.4.2.3.2.3 处理命令行参数与环境变量参数
通过一系列对copy_string函数的调用,将用户态传递的命令行参数和环境变量参数拷贝到分配的内核页中。所使用的内核页地址记录在page数组中,最多32页,也就是最多使用128KB存储参数
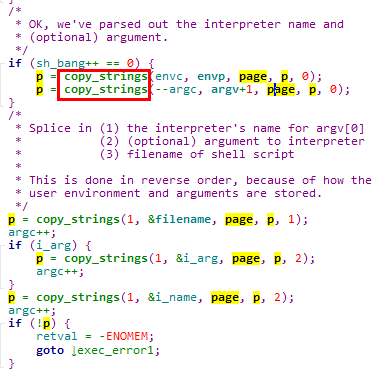
5.4.2.3.2.4 重置进程的用户态地址空间
此处包含对段表和页表的重建
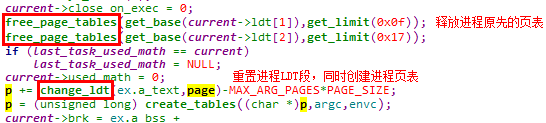
需要特别注意的是,在change_ldt函数重建进程页表时,将参数区映射到进程用户地址空间的最高端,将用户栈也设置在此处

调用create_tables函数后,构建的新创建进程用户栈状态如下图所示,
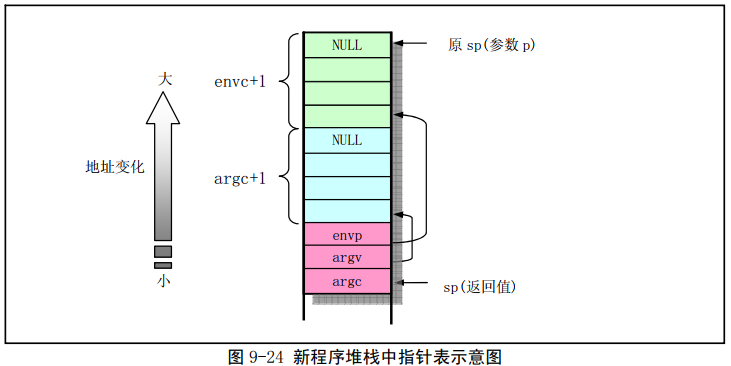
5.4.2.3.2.6 重置进程用户栈与返回地址
此处使用可执行程序入口地址重置了内核栈中保存的用户态断点EIP,同时重置了内核中保存的用户栈指针,
![]()
5.5 进程终止
5.5.1 exit系统调用使用实例
在1号进程中,会在execve系统调用出错时,调用_exit系统调用终止进程

_exit函数是exit系统调用的封装例程,exit是带有一个参数的系统调用,参数为进程退出码

5.5.2 exit系统调用分析
5.5.2.1 系统调用通用处理部分
系统调用的通用处理部分都是相同的,只是此处调用的是sys_exit函数
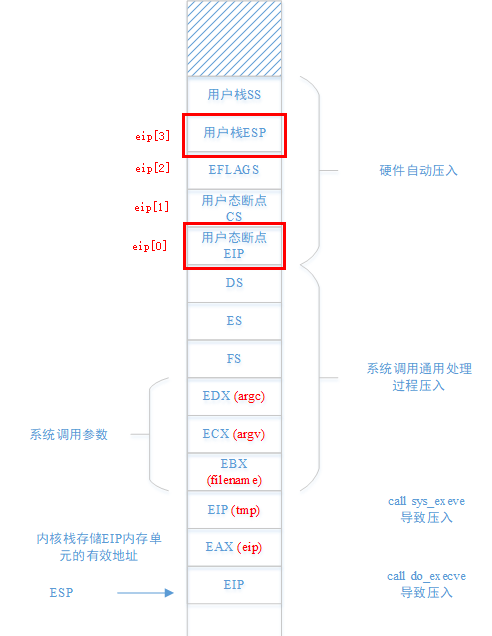
在跳转到sys_execve函数执行时,内核栈状态如下。因为fork系统调用只有一个参数,此时只有通过EBX传递的参数有效

5.5.2.2 do_exit函数分析
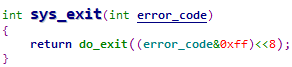
sys_exit函数将进程退出码error_code转换后,调用do_exit函数实现进程的终止
do_exit函数的主要操作,就是释放该进程持有的各种资源(e.g. 内存相关、文件系统相关)

说明1:进程在调用exit系统调用之后,释放了他所持有的资源,但是该进程对应的task_struct结构(也就是内核栈)并未释放,要等到他的父进程通过wait系统调用回收释放
说明2:kill_session函数
kill_session函数查找所有与当前进程处于同一个会话的进程,并向他们发送SIGHUP信号

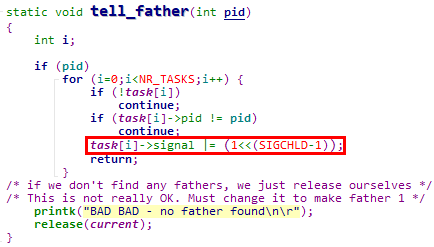
说明3:tell_father函数
① do_exit函数调用tell_father函数时传递的参数,是父进程的PID,因此有一个根据PID查找父进程task_struct结构体的过程
② 在找到父进程的task_struct结构体之后,向其发送SIGCHLD信号
5.6 进程回收
5.6.1 wait系统调用使用实例
在1号进程中,父进程会通过wait系统调用回收终止的子进程

wait函数最终调用waitpid函数实现功能,而waitpid函数是waitpid系统调用的封装例程,waitpid是带有3个参数的系统调用,参数为,

① pid_t pid:要回收的进程PID
- pid > 0,表示等待进程号等于pid的子进程
- pid = 0,表示等待进程组号等于当前进程组号的任何子进程
- pid = -1,表示等待任何子进程
- pid < -1,表示等待进程组号等于pid绝对值的任何子进程
② int *wait_stas:用于返回要回收进程的退出码
③ options:回收操作可选参数
- options = WNOHANG,宏值为1,表示如果没有子进程退出或终止就马上返回
- options = WUNTRACED,宏值为2,表示如果子进程是停止的,也马上返回
5.6.2 wait系统调用分析
5.6.2.1 系统调用通用处理部分
系统调用的通用处理部分都是相同的,只是此处调用的是sys_waitpid函数
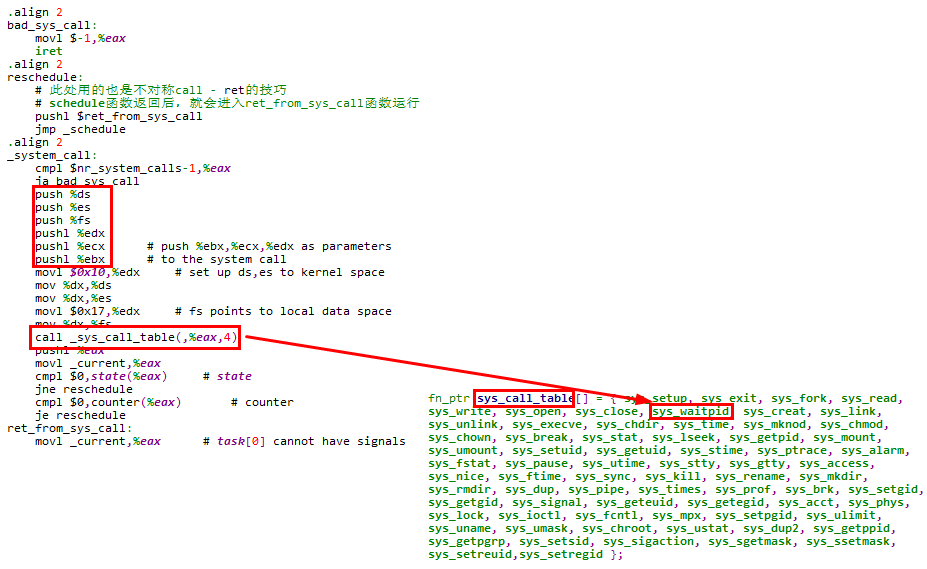
在跳转到sys_execve函数执行时,内核栈状态如下,
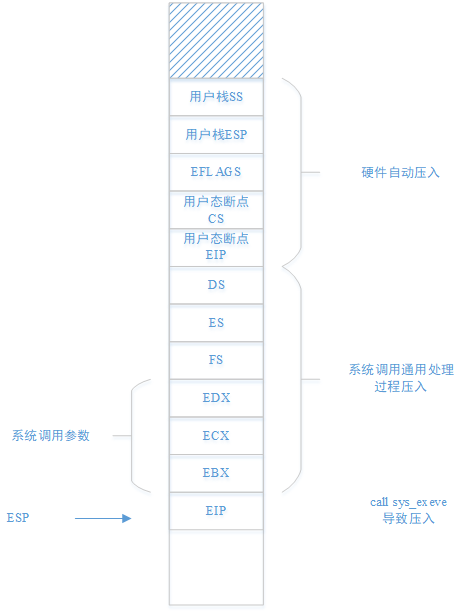
5.6.2.2 sys_waitpid函数分析
5.6.2.2.1 sys_waitpid函数参数分析
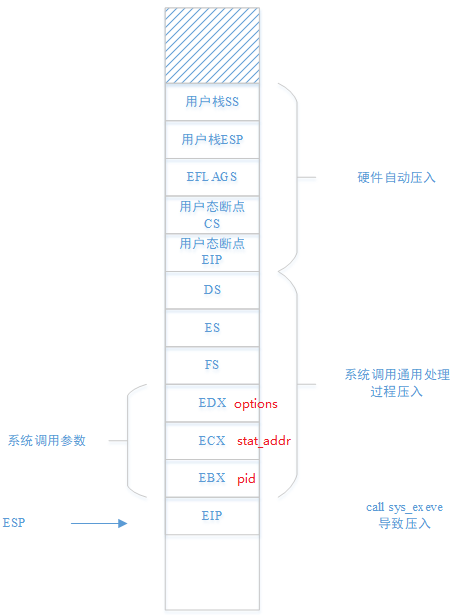
sys_waitpid函数的参数如下图所示,

该函数的参数均从内核栈获取,对应关系如下图所示,
5.6.2.2.2 sys_waitpid函数流程分析
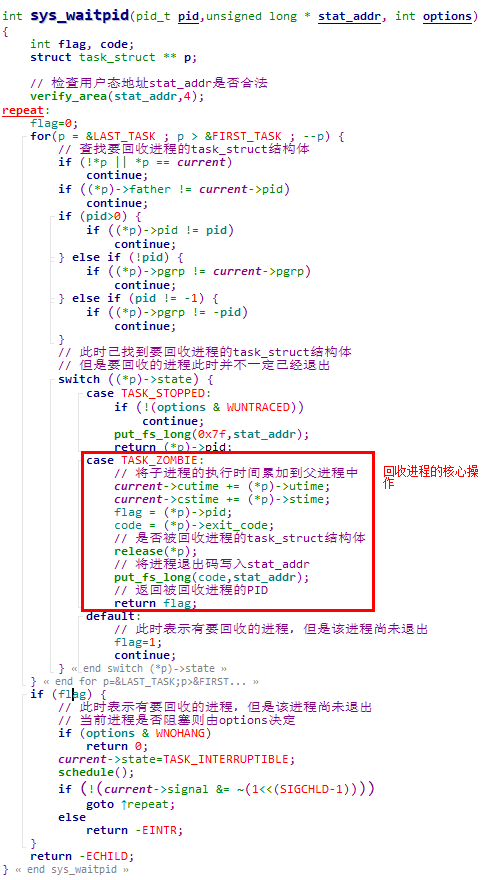
说明1:verify_area函数
① verify_area函数对当前进程从addr到addr + size这段地址空间,以页为单位进行写操作前的检测

② 其中write_verify函数的核心就是获取address线性地址对应的页表项,并检查是否具有写权限。如果没有写权限,则调用un_wp_page函数进行写时复制操作

③ un_wp_page函数中分配新的内存页,并拷贝页内数据

说明2:release函数
① release函数释放指定进程占用的任务槽和task_struct结构体占用的内存
② 从release函数的实现可见,如果一个进程调用exit终止后,其父进程不调用wait系统调用将其回收,那么任务槽和task_struct结构体就都不会释放,从而会影响后续的进程创建
6 CPU调度
6.1 CPU调度的含义
1. CPU调度是多进程视图下自然引出的问题
2. CPU调度就是在进程就绪队列中选择一个合适的进程,再通过进程切换机制将CPU资源分配给选择出来的进程
3. 关于CPU调度的基本单位,如果操作系统支持线程,那线程就是CPU调度的基本单位;否则进程就是CPU调度的基本单位(本节后续将他们统称为任务)
6.2 CPU调度算法衡量准则
6.2.1 基本准则
CPU调度的关键在于如何确定选择哪一个任务更合适,因此有一些列的调度算法衡量标准
1. 任务周转时间短
即任务从新建进入操作系统到完成离开操作系统所经历的全部时间要短
2. 任务响应时间短
即从用户向某任务发起一个交互操作(e.g. 点击鼠标、按下键盘)到该任务响应这个操作之间经历的时间要短
3. 系统吞吐量大
即一段时间内系统能完成的任务总数要大
6.2.2 调度算法总原则
1. 上述3个衡量调度算法的基本准则之间是有一定冲突的
例如要使得响应时间短,就需要更多的切换次数,从而增加任务切换的开销,最终会降低吞吐量
2. 不同任务关注的调度标准不同
① 交互式任务(前台任务)更关注响应时间
② 非交互式任务(后台任务)更关注周转时间
3. 需要根据不同的场景以及不同任务类型进行折中与综合,设计出合适的调度算法。下面给出2个示例场景,
① 对于工作在卫星、导弹和汽车等设备上的操作系统,系统处理任务的实时性是关键指标,因此调度算法应采用实时调度
② 对于工作在PC上的操作系统,用户希望交互动作尽快得到响应,同时也希望在一段时间内能处理尽可能多的任务。但是在处理任务时,通常没有严格的截至时间要求,也就是对实时性要求不高
6.3 CPU调度基本算法
6.3.1 先来先服务调度
1. 先来先服务(Fist Come First Service,FCFS)调度算法选择就绪队列头部的任务执行,该算法简单、易于实现且公平
2. 但是先来先服务调度算法对待各任务的绝对公平,会导致无法利用任务特征实现任务调度的整体优化。以任务周转时间为例,假设任务的到达时间和执行时间如下,
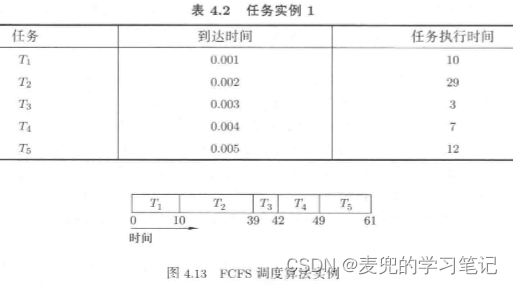
那么这5个任务的平均周转时间为,其中分子为每个任务的周转时间之和,
(10 + 39 + 42 + 49 + 61) / 5 = 40.23. 假设调换T2和T3的调度顺序,虽然总的任务执行时间不变,但是任务的平均周转时间会降低,

(10 + 13 + 42 + 49 + 61) / 5 = 35
4. 调换T2和T3的调度顺序,相当于增加长任务T2的周转时间而降低短任务T3的周转时间,从而换取整体调度性能的提升,这里体现了2点,
① 将短任务调度提前虽然在总体上提升了调度性能,但是也是有代价的,也就是长任务的周转时间上升,这在最终综合的调度算法中是需要考虑的
② 将短任务调度提前,体现了按任务特征进行调度
说明:需要特别注意的是,先来先服务调度算法中,任务的执行是不可抢占的。只有在一个任务执行完成后,下一个任务才能执行
6.3.2 最短作业优先调度
1. 最短作业优先(Shortest Job First,SJF)调度按照任务的执行时间从小到大排序,并按该顺序调度执行
2. 将FCFS算法中的任务实例按SJF算法进行处理,

那么5个任务的平均周转时间会降低,而且可以证明,SJF算法是平均周转时间最小的调度算法
(3 + 10 + 20 + 32 + 61) / 5 = 25.23. 将SJF算法改进为最短剩余时间优先调度(Shortest Remaining Time First,SRTF)算法
由于在实际系统中,任务不可能是同时出现在0时刻,因此无法在开始调度时对任务按执行时间进行排序,在实际环境中可以工作的是SRTF算法
SRTF算法在每次有新任务到达时,选择当前剩余执行时间最短的那个任务执行。由此可见,SRTF算法是一种可抢占式调度,而抢占点就是有新任务出现且新任务的剩余执行时间更短
SRTF算法调度实例如下图所示,

4. SJF算法及其改进的SRTF算法可以很好地优化任务的平均周转时间,因此对于旨在缩小周转时间的非交互式任务,SJF算法是合适的
但是对于系统中的交互式任务,SJF算法并不合适,因为SJF算法不能优化响应时间指标。同样是SRTF调度算法的任务实例,对于任务T2,响应时间太长,需要等待所有任务执行时间比他短的任务执行完成后才能执行
说明:SJF算法和SRTF算法还有一个问题,就是任务执行时间和任务剩余执行时间在调度时只能预估,在任务执行完成前无法得到其确切值
6.3.3 时间片轮转调度
1. 为了确保任务在最差情况下的响应时间,引入了时间片轮转(Round Robin,RR)调度,即给每个任务分配一个执行时间片,当前任务的时间片用完就切换到下一个任务执行
2. 假设任务的到达时间和执行时间如下,使用RR调度算法,每个任务的响应时间均有上界
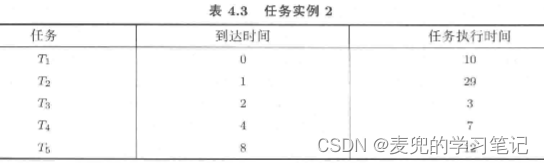

3. 对于有N个任务且时间片长度为t的系统,任务的响应时间(Response Time,RT)满足如下条件,
RT ≤ N * t通过合理设计N和t,可以确保任务响应时间的上界。因此,RR调度算法对于交互式任务是合适的
4. 关于RR调度算法中时间片长度的设置也需要折中,
① 如果时间片长度太长,则响应时间太长
② 如果时间片长度太短,则系统吞吐量小(因为任务切换太频繁)
说明:RR调度算法在优化任务响应时间的同时,就无法达到最小的任务周转时间。而且RR调度算法会增加任务切换次数,从而增加系统开销。从这里也可以看出,任何调度算法都有利弊,需要在合适的场景下使用
6.3.4 多级队列调度(Multilevel Queue Scheduling)
1. 如上文分析,SJF / SRTF算法可以处理非交互式任务,RR算法可以处理交互式任务,而且操作系统中既有非交互式任务也有交互式任务。一个自然的想法,就是将不同类型的任务组织在不同的队列中并且用不同的调度算法处理,其中,
① 将交互式任务(前台任务)组织在一个队列中,并使用RR算法调度
② 将非交互式任务(后台任务)组织在一个队列中,并使用SJF / SRTF算法调度
③ 在两个任务队列之间,使用优先级调度,通常让前台队列具有更高的优先级。即只要前台任务队列中存在就绪任务,就一直采用RR算法调度处理这个队列中的任务

2. 多级队列调度存在的问题
首先需要强调的是,引入多级队列调度,是为了让系统中不同的类型的任务均能满意。但是这种静态的类型划分存在如下问题,
① 如果有前台任务不断加入,那么系统将始终调度前台任务运行,将会导致后台任务饥饿
② 当轮到后台任务执行时,需要等待该任务执行完成后才能释放CPU,从而影响前台任务的响应时间
③ 更为重要的是,在创建任务时,无法体现该任务是交互式任务还是非交互式任务(e.g. fork & execve系统调用没有相应的参数进行区分)。而且任务的特性也不是一成不变的,在执行的不同时期可能体现不同的特性(e.g. 后台任务有时也需要交互操作,前台任务有时也会进行批处理)
6.3.5 多级反馈队列调度(Multilevel Feedback Queue Scheduling)
1. 多级队列调度的改进方向
多级反馈队列调度的实现,源自对多级队列调度的改进,主要体现在如下2点,
① 后台任务也按照时间片来调度,即使有前台任务,后台任务也能得到一个执行时间片。这样既能保证前台任务的响应时间,也能保证后台任务不至于完全饥饿
② 任务的类型不是在任务创建时静态划分,而是根据任务在执行过程中的具体表现进行动态调整。也就是说,前后台任务不使用固定的优先级,而是可以动态进行调整
这些动态的调整,就体现了”反馈”的含义
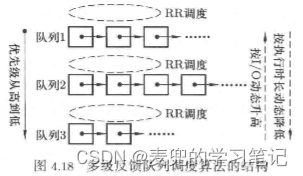
2. 动态调整的思路
① 根据IO操作进行动态调整
IO操作是区分前后台任务的一个典型特征,一般前台任务的IO操作较多,因此通过IO操作可以近似解决前台任务的识别问题
根据任务执行的IO操作动态提高任务的优先级,可以较好地确保前台任务的响应时间
② 根据执行时长进行动态调整
如果一个任务在执行完一个时间片之后仍然需要执行,说明该任务没有发生IO操作,也没有执行完成。可以近似确定该任务是一个非交互式任务,而且是一个长作业,因此可以动态降低其优先级
7 Linux 0.11进程调度实例
7.1 schedule函数分析
Linux 0.11内核schedule函数总体处理流程如下,

7.2 调度算法核心分析
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
// 处理定时器与信号
// ...
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
// 从就绪态任务中选择counter值最大的任务执行
// 此时越过了处于阻塞态的任务
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
// 如果找到,则跳出while(1)循环,并切换到该任务执行
if (c) break;
// 执行到此处,说明c为0,也就是所有就绪态任务的counter值均为0
// 此时需要重置任务的时间片 / 优先级,也就是counter值
// 在重置counter值时,包含就绪态和阻塞态的任务
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
// (*p)->counter >> 1,将进程剩余时间片除以2,这是针对处于阻塞态的进程
// (*p)->priority,是进程的优先级,也是进程的初始时间片
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
// 在重置时间片 / 优先级之后,会再次开始while(1)循环
// 选择出当前优先级最高的任务
} // while (1)
// 实现进程切换
switch_to(next);
}7.3 counter作用分析
说明:counter变量的使用是Linux 0.11调度算法的核心,该变量兼具三重功能
7.3.1 体现优先级
1. 在调度时,选择就绪态任务中counter值最大的进程执行
2. 在重置counter值时,基础为进程的优先级priority
7.3.2 体现时间片
在时钟中断处理函数中,会递减当前执行进程的counter值,当其减为0时,则调用schedule函数触发调度

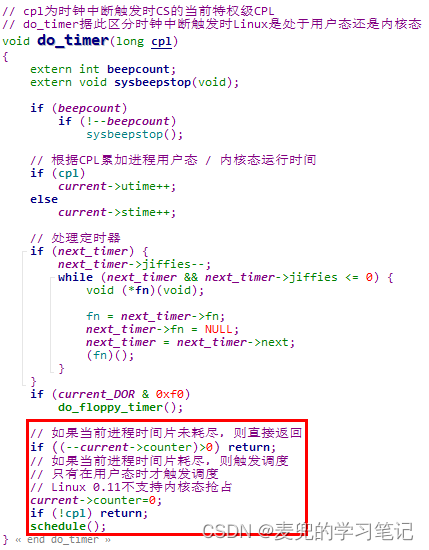
说明1:do_timer函数的参数
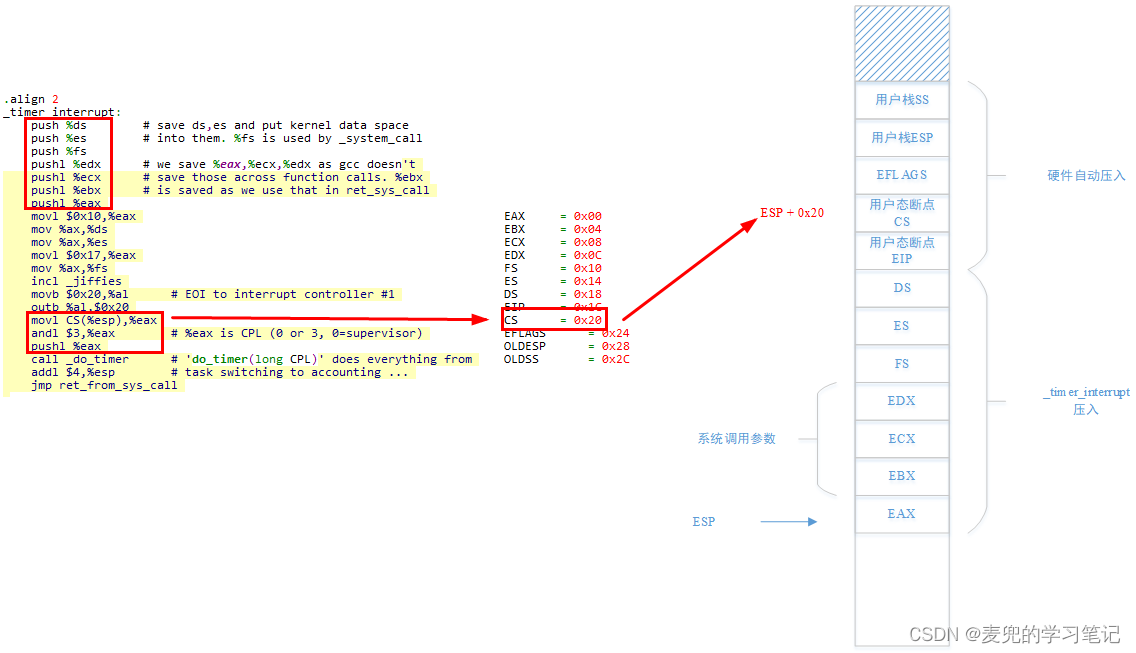
① 上图中假设被时钟中断打断的程序在用户态执行,因此硬件会保存用户栈信息;如果被时钟中断打断的程序在内核态执行,则没有用户栈信息需要保存。但是上述两种情况,都不影响对断点CS的索引
② ESP + 0x20索引的是内核栈中保存的断点CS,其中的最后2位表示程序被打断时的CPL,通过该值可以确定程序是在用户态还是在内核态被打断
说明2:时钟中断处理函数timer_interrupt在调用do_timer函数之前已经进行了EOI操作,因此才可以在do_timer函数中调用schedule函数触发进程调度与切换
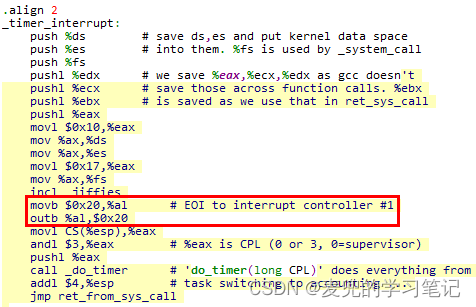
这里需要注意的是,在进入do_timer函数时,
① 处理器处于关中断中断
在进入中断处理时,处理器会将EFLAGS的IF位置为0
② 已经对8059A中断处理器进行了EOI操作,8059A可以继续产生后续中断(包括时钟中断)
也就是说,此时处于处理器关中断,但是中断控制器开中断的状态。关于在中断处理函数中触发进程调度与切换的讨论,可参考X86汇编语言从实模式到保护模式18:中断和异常的处理与抢占式多任务 chapter 4.2
7.3.3 体现优先级动态调整
1. 在do_timer函数中,会递减当前执行进程的counter值,相当于降低了该进程的优先级
2. 在重置进程时间片 / 优先级时,对于处于阻塞态的进程,会将剩余时间片除以2并加入counter值中。从而提高了因IO阻塞后重新进入就绪态的进程优先级,相当于照顾了前台任务
说明:根据schedule函数中重置时间片 / 优先级的逻辑,一个进程因IO阻塞的时间越长,重置的counter值越大,但是该值是有上界的
C(0) = p // priority
C(1) = C(0) / 2 + p = p/2 + p
C(t) = C(t - 2) / 2 + p = p + p / 2 + p / 2^2 + .... = 2p // 无穷级数收敛于2p由于每个进程的时间片有上界,就确保了系统中的响应时间有上界。只要合理地设置优先级和进程个数,就可以将所有任务的响应时间控制在用户可以接受的范围内
7.4 schedule调度时机
在Linux 0.11内核的进程调度机制中,通常有以下两种情况需要进行调度,
1. 进程时间片耗尽
e.g. 在时钟中断处理函数中进程时间片递减为0
2. 进程无法再继续执行
e.g. 进程因等待资源主动放弃CPU,或者进程执行完毕调用exit系统调用退出
8 实验:基于内核栈完成进程切换
8.1 任务目标
1. 目前无论是Linux还是Windows,进程切换都没有使用Intel提供的TSS段机制,只有早期的Linux内核版本使用该机制
2. 修改Linux 0.11内核代码,将进程切换的实现方式从使用TSS段机制转换为使用内核栈
8.2 Linux 2.4内核进程切换分析
Linux 2.4.0 + i386实现中,已不再使用TSS段机制实现进程切换,而是使用内核栈。因此我们以该组合为模板,分析基于内核栈的实现方式。其中涉及系统调用处理、进程创建与进程切换
8.2.1 系统调用通用处理
文件:arch/i386/kernel/entry.S

说明:系统门在trap_init函数中安装

8.2.1.1 保存现场
系统调用通用处理过程中的保存现场,可以理解为由3部分构成,
1. 处理器保存部分
这部分包括用户栈信息、EFLAGS和用户态断点信息
2. 保存系统调用号
这部分由pushl %eax完成
3. 进一步保存寄存器并且将系统调用参数压栈
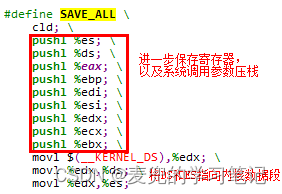
这部分由SAVE_ALL宏完成,该宏实现如下
说明1:系统调用通用处理部分保存现场后,内核栈布局如下图所示,

其中的pt_regs结构体成员布局与内核栈布局相同,后续作为传递给系统调用服务例程的参数类型,以sys_fork函数为例

说明2:关于asmlinkage宏
① Linux 2.4内核中所有系统调用服务例程均使用asmlinkage修饰,而asmlinkage在i386体系结构中是设置了regparm属性
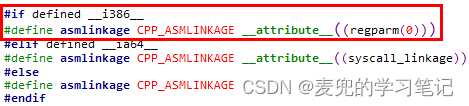
② __attribute__ ((regparm(n)))属性用于指定最多可以使用n个寄存器传递参数,超过n个的参数使用栈传递。对于系统调用服务例程,属性指定为regparm(0),也就是所有参数均通过栈传递
说明3:在SAVE_ALL宏中执行了cld指令,该指令用于将EFLAGS寄存器中的DF位清零,从而实现正向传送
|
DF(Direction Flag) 方向标志位 |
当DF = 1,每步之后变址寄存器递减,也就是地址递减 |
8.2.1.2 获取当前进程task_struct结构体
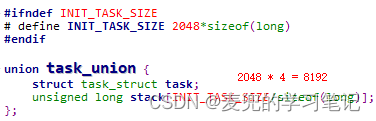
1. 获取当前进程task_struct结构体通过GET_CURRENT宏实现,实际的计算就是将esp寄存器值的低13位清零并保存在ebx寄存器中
![]()
2. 之所以是将esp寄存器值的低13位清零,是因为在Linux 2.4内核中,内核栈为8KB且task_struct结构体位于内核栈地址低端。因此内核栈向下8KB对齐的位置,存储的就是对应进程的task_struct结构体
3. 将当前进程的task_struct结构体保存在ebx寄存器中,后续对调度、信号的处理将会使用到

8.2.1.3 调用系统调用服务例程
1. 在Linux 2.4内核中,系统服务例程也是组织为sys_call_table数组,其中的每个成员对应一个系统调用服务例程的函数指针

2. 最终通过call指令调用相应的系统调用服务例程,此处增加了一次解引用,其实在GCC对函数指针的处理中可以不增加这次解引用

3. 当系统调用服务例程返回后,将返回值eax存储在内核栈中对应于EAX的位置,供后续恢复现场。该值也将作为系统调用的返回值,被返回到用户态的系统调用封装例程中
8.2.1.4 恢复现场与异常返回
1. 在Linux 2.4内核中,RESTORE_ALL宏同时完成了恢复现场与异常返回。执行iret指令后,执行流返回用户态

2. 在执行iret指令之前,RESTORE_ALL宏恢复之前由SAVE_ALL宏保存的现场,并且丢弃在系统调用通用处理入口保存的orig_eax。从而使内核栈恢复到从用户态陷入内核态时的状态,即栈顶为处理器自动压入的用户栈信息、ELFAGS寄存器和用户态断点信息
8.2.2 进程创建概要
8.2.2.1 调用do_fork函数
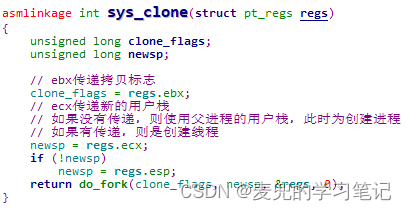
1. sys_fork函数调用do_fork函数创建进程,

对照do_fork函数的参数,传递的参数如下,
![]()
① clone_flags:进程拷贝参数,sys_fork传递的是SIGCHLD,该宏值为17,也就是bit [4]和bit [0]为1
② stack_start:用户栈指针,sys_fork传递的是regs.esp,即父进程用户栈指针,也就是从用户态陷入内核态时处理器保存的用户栈指针。由于是使用写时复制机制创建进程,此处子进程会共享父进程的用户栈
③ regs:压入内核栈的现场以及系统调用参数
④ stack_size:该参数实际没有使用
2. 在Linux 2.4内核中,sys_fork / sys_clone / sys_vfork系统调用最终都通过do_fork函数创建进程 / 线程,只是调用的参数不同

8.2.2.2 分配内核栈,拷贝父进程task_struct结构体

其中alloc_task_struct函数会分配2页内存,也就是8KB
![]()
8.2.2.3 设置子进程内核栈
1. 在do_fork函数中会调用一系列函数设置子进程的状态,其中copy_thread函数会设置子进程内核栈,这与后续的进程切换密切相关

2. copy_thread函数将父进程内核栈的内容拷贝到子进程内核栈,并对其中的一些字段进行修改,目的是使得第一次切换到该进程时可以正确执行

copy_thread函数执行后,从父进程内核栈拷贝了pt_regs结构体,子进程内核栈状态如下,

说明:关于copy_thread函数中的chilldregs->esp = esp操作
① childregs->esp = esp操作的目的是设置新建进程 / 线程的用户栈指针
② 对于fork和vfork系统调用,新建进程和父进程共享用户栈指针,因此此处设置的用户栈指针就是从pt_regs结构体中取出
这也是我一开始分析时觉得疑惑的地方,此时chilldregs->esp = esp操作相当于没有修改从父进程拷贝的内核栈内容


③ 但是对于clone系统调用,可以指定新建进程 / 线程的用户栈地址,而不共享父进程的用户栈,此时在copy_thread函数中就需要chilldregs->esp = esp操作来设置正确的用户栈指针

3. 根据copy_thread函数的设置,当子进程被首次调度执行时,入口点为ret_from_fork函数。最终调用RESTORE_ALL宏恢复现场并返回用户态,与父进程相比,子进程fork系统调用的返回值为0(子进程内核栈中EAX字段为0)
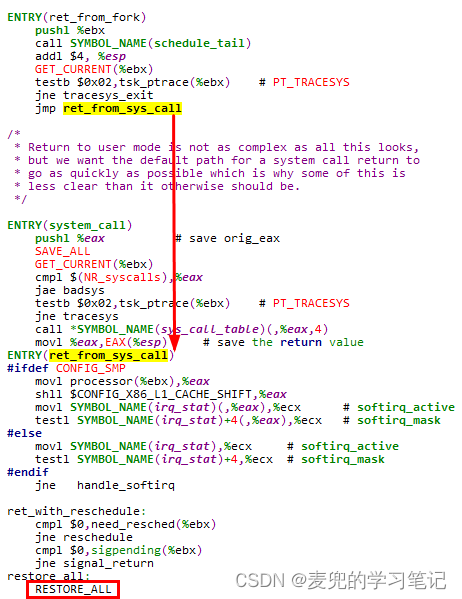
8.2.3 进程切换
8.2.3.1 进程切换函数分析
关于i386 + Linux 2.4的进程切换,在本文chapter 4.2.3.4已有分析,下面重点说明新建进程首次被调度执行的场景
#define switch_to(prev,next,last) do {
asm volatile(
// 将esi / edi / ebp寄存器压栈保存
// 保存在prev线程内核栈中
"pushl %%esi\n\t"
"pushl %%edi\n\t"
"pushl %%ebp\n\t"
// 内核栈切换
// movl esp, prev->thread.esp
// movl next->thread.esp, esp
// 此时esp指向新创建进程内核栈中的pt_regs结构体
"movl %%esp,%0\n\t"
"movl %3,%%esp\n\t"
// 保存prev线程执行断点,即标号1位置处
// mov $1f, prev->thread.eip
"movl $1f,%1\n\t"
// 准备next线程执行断点,压入当前内核栈中(也就是next线程的内核栈)
// 后续通过一条ret指令,即可以恢复next线程执行断点
// pushl next->thread.eip
// 新创建进程的执行断点为ret_from_fork
"pushl %4\n\t"
// 内核态执行流切换
// 通过jmp指令跳转到__switch_to函数执行,该函数的右括号被编译为ret指令
// 该ret指令会将最后压栈的next->thread.eip出栈到EIP寄存器中
// 从而实现内核态执行流切换
"jmp __switch_to\n"
"1:\t"
// 对于新创建的线程,不会执行到标号1处
// 此时执行的已经是next线程
// 从next线程内核栈中恢复ebp / edi / esi寄存器
"popl %%ebp\n\t"
"popl %%edi\n\t"
"popl %%esi\n\t"
// 0号参数,prev->thread.esp,前一线程内核栈,存储在内存中,只写
// 1号参数,prev->thread.eip,前一线程执行断点,存储在内存中,只写
:"=m" (prev->thread.esp),"=m" (prev->thread.eip),
// 2号参数,存储在ebx寄存器中,只写
"=b" (last)
// 3号参数,next->thread.esp,下一线程内核栈,存储在内存中
// 4号参数,next->thread.eip,下一线程执行断点,存储在内存中
:"m" (next->thread.esp),"m" (next->thread.eip),
// 5号参数,前一线程TCB,存储在eax寄存器中
// 6号参数,下一线程TCB,存储在edx寄存器中
"a" (prev), "d" (next),
// 7号参数,前一线程TCB,存储在ebx寄存器中
"b" (prev));
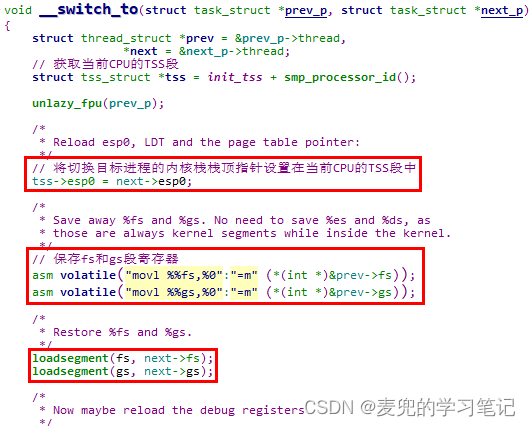
} while (0)8.2.3.2 __switch_to函数分析
1. 首先来分析一下__switch_to函数的声明,regparm(3)属性表示会用3个寄存器(EAX / EDX / ECX)来传递参数,其余参数通过栈传递

但是__switch_to函数只使用了2个参数,结合switch_to函数内嵌汇编语句中的参数说明,EAX中存储的是prev指针,EDX中存储的是next指针,与__switch_to函数的参数是匹配的

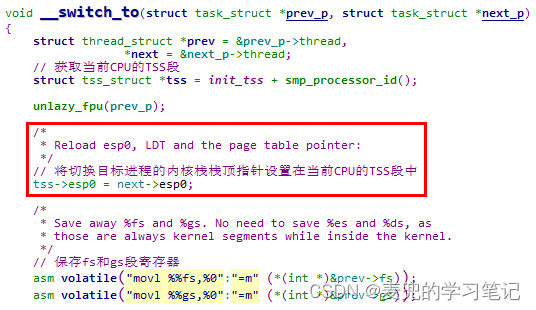
2. __switch_to函数中的核心操作,是将切换目标进程的内核栈栈顶指针设置在当前CPU的TSS段中。这样当从用户态陷入内核态时,就可以找到相应进程的内核栈,从而完成栈的切换
8.2.3.3 对TSS段的有限使用
1. 首先来分析一下Linux 2.4内核中GDT的布局,因为TSS段和LDT段都是登记在GDT中的

在Linux 2.4内核中对TSS段和LDT段都是有限使用,在SMP环境下,为每个CPU创建了一个TSS段和一个LDT段
2. TSS段的定义
Linux 2.4内核全局定义了init_tss数组,每个CPU一个TSS段

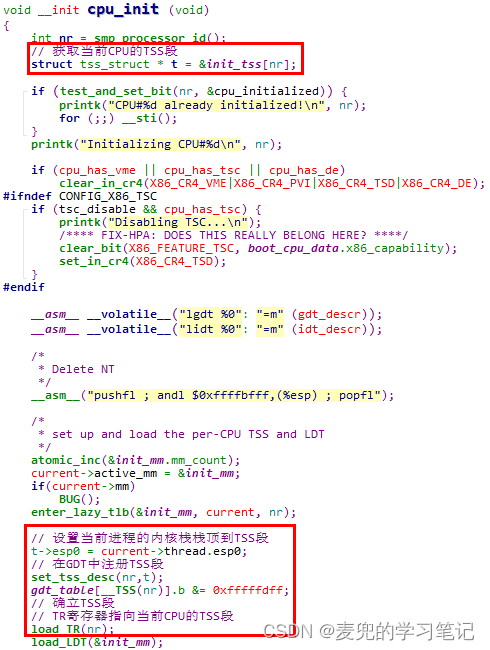
3. TSS段的使用
对TSS段的注册与确立均在cpu_init函数中完成,在系统启动过程中,每个CPU均会执行到该函数
4. Linux 2.4内核对TSS段的使用,仅限于在切换进程时将目标进程的内核栈栈顶设置在当前CPU的TSS段中,以确保切换后该进程从用户态陷入内核态时,可以正确找到相应的内核栈
8.2.3.4 对LDT段的有限使用
1. LDT段的定义
默认的LDT段共有5个表项,但实际只使用到其中2个,部署了2个调用门,用以确保在iBCS和Solaris/x86环境下编译的程序可以在Linux中运行
![]()

2. LDT段的使用
① 在cpu_init函数中,会调用load_LDT函数登记并注册本CPU的LDT段

② 在绝大多数情况下,进程使用的都是默认LDT段。只有通过modify_ldt系统调用设置LDT段时,才会为该线程创建单独的LDT段
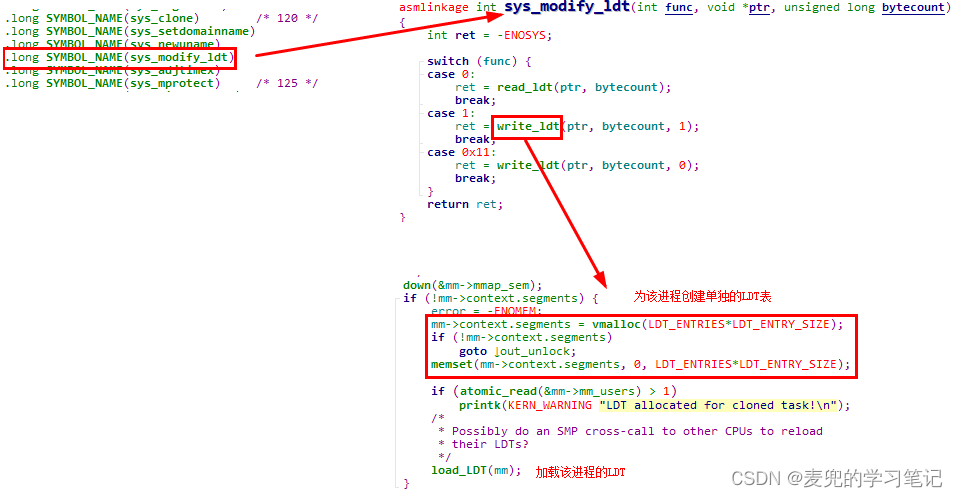
说明:在没有通过modify_ldt系统调用设置进程LDT段的情况下,进程mm->context.segments的值均为NULL。在切换进程前进行进程地址空间切换的switch_mm函数中,不会触发重新加载LDT表
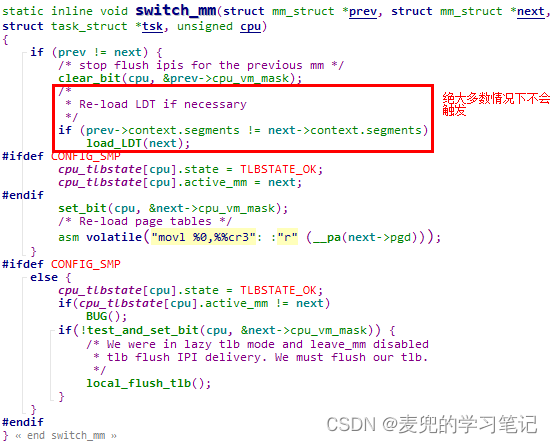
8.3 修改分析
8.3.1 系统调用处理部分
1. Linux 0.11内核在系统调用通用部分压栈内容较少,在通过fork系统调用创建进程时,还需要依靠sys_fork处理部分进行压栈
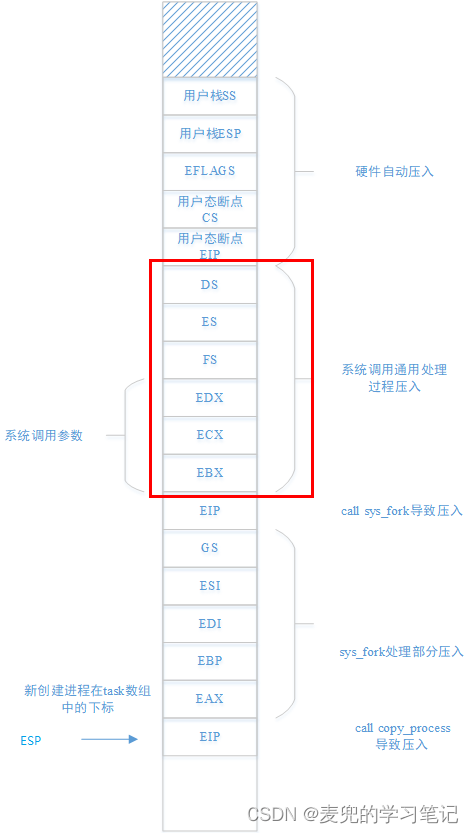
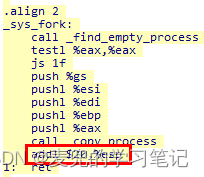
2. 在进入copy_process函数执行时,压入父进程内核栈中的参数已经完整保存了父进程的状态,保存的状态是截至copy_process函数调用之前
但是需要注意的是,sys_fork处理阶段压栈的5个寄存器,在copy_process函数被调用后,不是恢复到寄存器,而是直接被丢弃。如果改为使用内核栈进行进程切换,这部分寄存器是需要恢复的(其中的EAX寄存器还负责向子进程返回fork系统调用的状态)
8.3.2 进程切换部分
8.3.2.1 切换流程差异
1. 基于TSS段机制进行进程切换时,新建进程首次执行不会经过系统调用恢复现场与异常返回的流程,而是直接切换到用户态执行
因此在构造新建进程的TSS段时,构造的就是直接返回用户态执行的状态
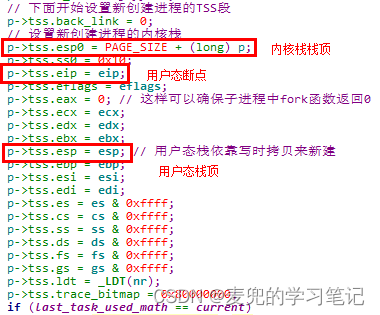
2. 如果改为基于内核栈的进程切换,则需要按顺序经历如下过程,
① 内核栈切换
② 内核态执行流切换(通过ret指令)
③ 用户态执行流切换(通过iret指令)
8.3.2.2 内核栈构造
按照上面的流程,就需要明确在上述执行流切换时,内核栈应具有的状态,从而指导进程的创建,
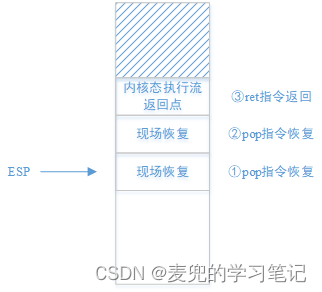
1. 内核态执行流切换
① 执行ret指令时,内核栈栈顶必须是next进程期待执行的指令流,
- 对于非新建进程,应该返回之前被切换走时的内核位置
- 对于新建进程,应该在创建该进程时指定返回位置
② 如果内核栈切换之后,ret指令执行之前,执行流程中还有恢复现场的操作,在新建进程时,需要有相应地压栈操作
③ 按照上述要求,在内核态执行流切换时,内核栈需要按如下方式构造,
2. 用户态执行流切换
① 执行iret指令时,内核栈栈顶布局必须如下图所示,

② 如果在内核态执行流切换之后,iret指令执行之前,执行流程中还有恢复现场的操作,在新建进程时,也需要有相应地压栈操作
③ 按照上述要求,完整的内核栈构造如下,
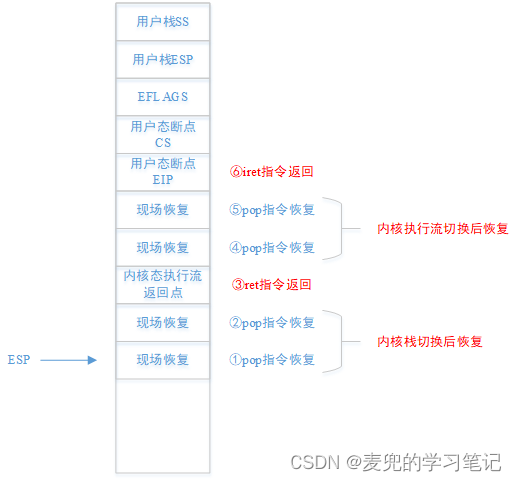
说明:内核栈构造要点小结
① 2处执行流切换点
- 内核态执行流切换点
- 用户态执行流切换点
② 3处现场恢复
- 内核栈切换后现场恢复(软件执行)
- 内核态执行流切换后现场恢复(软件执行)
- 用户态执行流切换后现场恢复(处理器执行)
8.3.2.3 内核栈指针存储
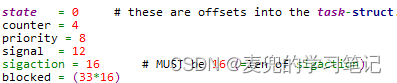
在Linux 0.11的task_struct结构中,没有存储内核栈的字段,需要添加。但是添加的位置必须在blocked字段之后

这是因为在system_call.s文件中,对task_struct中一些字段的操作有硬编码,将新增字段加在blocked字段之后,可以确保原有代码无需修改

说明:Linux 2.4内核通过在task_struct结构中增加thread_struct结构来记录与体系结构相关的信息,封装了对不同体系结构的支持
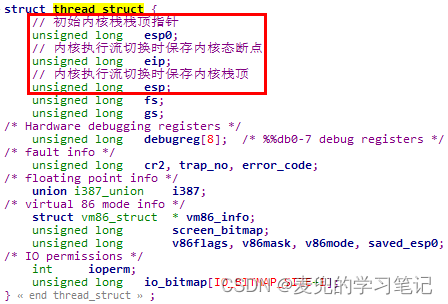
作为对比,下面列出Linux 2.4内核中ARM体系结构的thread_struct结构,


8.3.3 进程创建部分
1. 因为使用内核栈进行进程切换,所以创建进程的流程需要修改。之前将新建进程的上下文保存在TSS段中,现在需要保存在内核栈中
2. 这部分操作的核心,依然在copy_process函数中
8.3.4 对TSS段的使用
1. 只保留一个全局的TSS段,而不是为每个进程创建一个。为简化实现,可以系统中所有进程都使用0号进程的TSS段
2. 在对TSS段的使用中,仅用其存储当前进程的内核栈信息(即esp0与ss0字段),以确保进程从用户态陷入内核态时,可以正确找到相应的内核栈
3. 在切换进程时,需要将目标进程的内核栈信息登记在全局的TSS段中
8.3.5 对LDT段的使用
1. 因为Linux 0.11内核通过LDT段实现进程地址空间的隔离,因此需要保留每个进程的LDT段
2. 在基于TSS段机制进行进程切换时,LDTR寄存器的切换由处理器完成。而在基于内核栈进行进程切换时,需要在切换进程时由程序调用lldt指令将LDTR寄存器指向目标进程的LDT段
8.4 修改流程
8.4.1 修改schedule函数
修改文件:kernel/sched.c
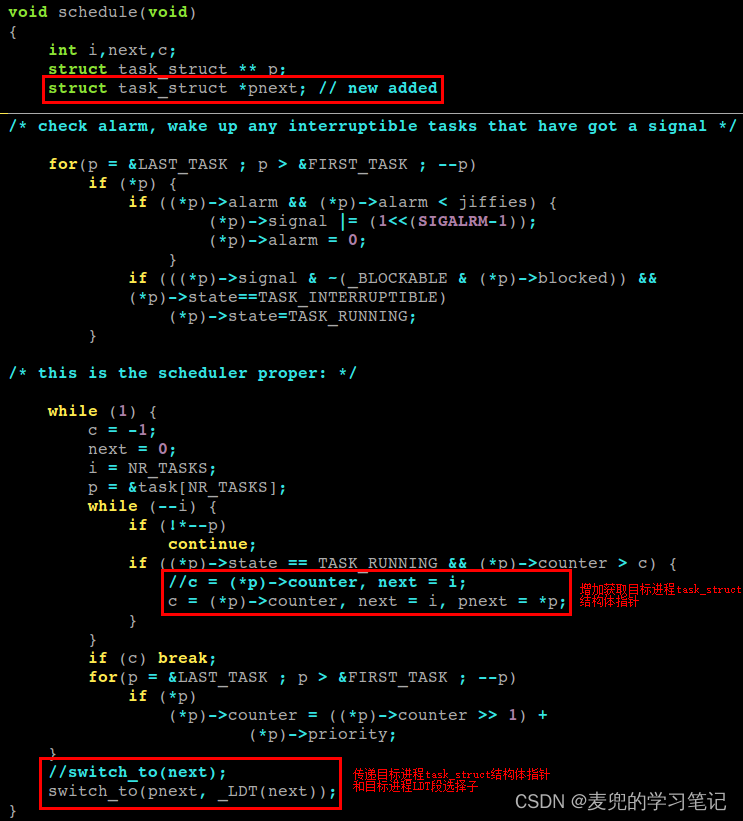
修改schedule函数的主要原因是为了向新版switch_to函数传递所需参数,原先的switch_to函数只需要目标进程在task数组中的下标,但是新版switch_to函数需要传递如下2个参数,
1. 目标进程的task_struct结构体指针
2. 目标进程的LDT段选择子(用于在switch_to函数中切换LDTR寄存器指向)
其实只传递目标进程在task数组中的下标也可以索引到这2个信息,但是直接传递可以简化switch_to函数的实现
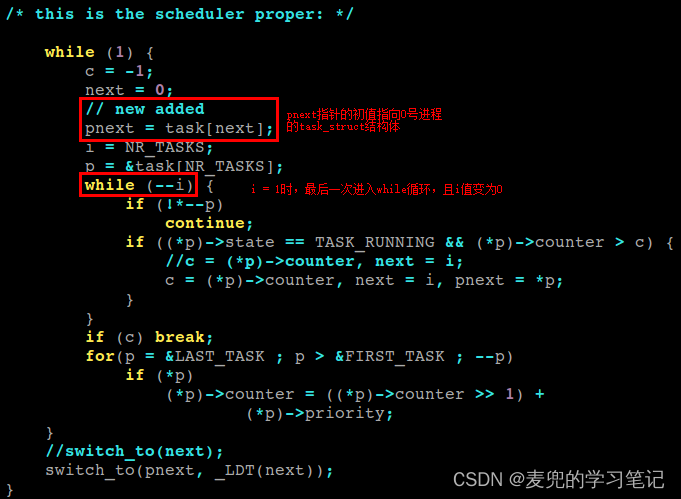
补充:schedule函数中还有一处需要修改,否则当系统中只有0号进程时,调用switch_to函数时会传递空指针
如果系统中只有0号进程,在while(–i)循环中,不会遍历到0号进程,此时pnext为空指针
8.4.2 新增switch_to函数实现文件
1. 首先注释掉之前的switch_to函数实现
修改文件:include/linux/sched.h

2. 新增kernel/switch_to.s文件,用于实现新版switch_to汇编函数
![]()
同时修改kernel/Makefile文件,将新增文件加入编译

8.4.3 新增tss全局变量
修改文件:kernel/sched.c
1. 系统中所有进程都使用0号进程的TSS段

2. 由于系统中所有进程都使用0号进程的TSS段,所以TR寄存器的指向也不会修改,而TR寄存器的初始化仍然是依靠sched_init函数中的ltr(0)操作
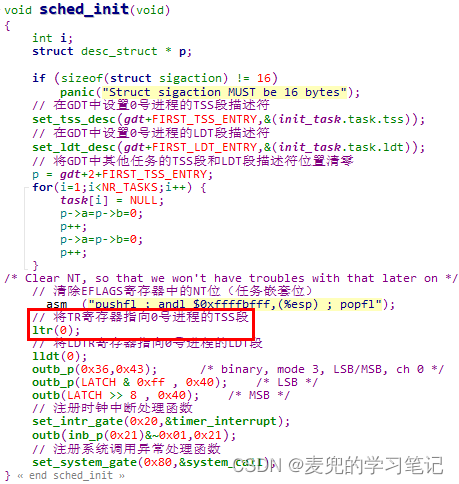
8.4.4 在task_struct结构体中新增kernelstack字段
1. 如上文分析,在task_struct结构体中新增kernelstack字段,并且存储在blocked字段之后
修改文件:include/linux/sched.h
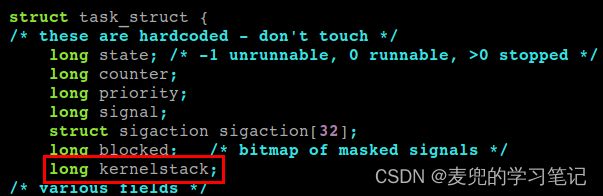
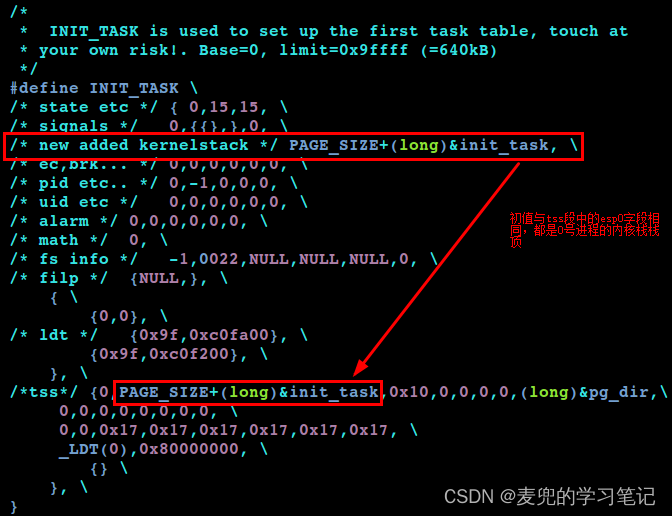
2. 由于在task_struct结构体中新增了字段,因此需要在INIT_TASK宏中对其进行初始化,否则会影响0号进程task_struct结构体中的其他字段初始化
修改文件:include/linux/sched.h
8.4.5 实现新版switch_to函数

说明:在实现新版switch_to函数时,先不要考虑新建进程的首次启动,而是专注于正常2个进程的切换,之后再由进程切换的过程指导进程创建
8.4.5.1 构造栈帧
pushl %ebp
movl %esp, %ebp
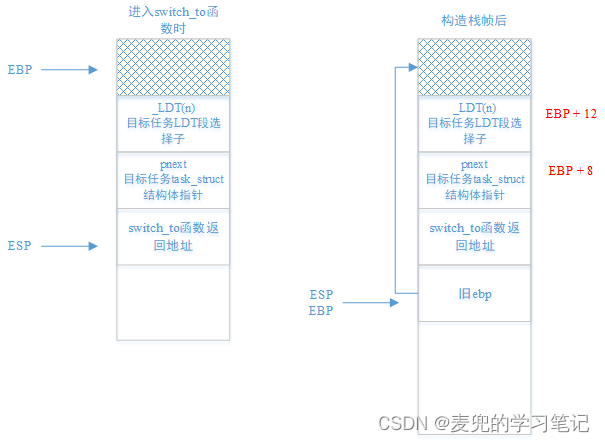
1. 首先需要注意的是,新版switch_to函数是一个完全由汇编实现的函数,而不是一段内嵌汇编。因此对进入函数时的栈帧创建,需要手动完成
而此处构造栈帧的目的,是为了使用ebp寄存器作为一个稳定的基址寄存器来访问函数参数
2. 进入switch_to函数以及构建栈帧后的内核栈状态如下图所示,
8.4.5.2 保存寄存器
pushl %ecx
pushl %ebx
pushl %eax1. 保存eax / ebx / ecx寄存器,是因为后续流程会修改这3个寄存器
2. 此处将eax / ebx / ecx寄存器压入prev进程的内核栈,压栈后状态如下图所示,
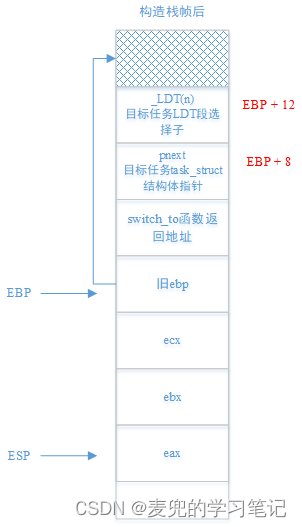
8.4.5.3 判断当前进程
此处通过EBP寄存器从prev进程的内核栈中取出pnext参数,用于判断是否需要进行进程切换
movl 8(%ebp), %ebx # pnext field
cmpl %ebx, current
je 1f8.4.5.4 切换PCB
movl %ebx, %eax
xchgl %eax, current切换完成后,各寄存器和全局变量的指向如下,
current:指向切换目标进程(next进程)
ebx:指向切换目标进程(next)
eax:指向切换prev进程,此时尚未完成切换
8.4.5.5 设置全局TSS段
movl tss, %ecx
addl $4096, %ebx
movl %ebx, 4(%ecx) # esp0 field
1. 此时ebx指向切换目标进程,所以ebx + 4096为切换目标进程的内核栈栈顶
2. 此时ecx指向共用的0号进程的TSS段,ecx + 4指向其中的esp0字段
8.4.5.6 切换内核栈
movl %esp, 532(%eax) # kernelstack field
movl 8(%ebp), %ebx # pnext field
movl 532(%ebx), %esp # kernelstack field
1. 切换内核栈的步骤如下,
① 将当前esp寄存器值记录在prev进程的PCB中
② 将next进程PCB中保存的内核栈指针写入esp寄存器
2. 内核栈指针在task_struct结构体中的偏移量为532,是因为blocked字段在task_struct结构体中的偏移量为(33 * 16 = 528),而kernelstack字段在blocked字段之后(528 + 4 = 532)

8.4.5.7 切换LDT段
此处需要注意的是,_LDT(n)生成的LDT段选择子为4B,参数压栈时也为4B,但是实际有效的只有低2B,也就是cx寄存器中的内容(也就是lldt指令所需的操作数)
movl 12(%ebp), %ecx # _LDT(n) field
lldt %cx8.4.5.8 重新加载用户数据段
movl $0x17, %ecx
mov %cx, %fs如上文所述,每个进程的用户数据段选择子均为(0b1 0 111 = 0x17),但是在Linux 0.11内核中每个进程的用户数据段范围是不同的。此处使用0x17重新加载FS段寄存器,是为了刷新FS段寄存器的高速缓存部分,这部分对程序员不可见
如果在进程切换后,不重新加载FS段寄存器,则无法在内核态正确访问目标进程的用户数据段
8.4.5.9 浮点协处理器相关处理
这部分沿用了Linux 0.11内核中switch_to函数的操作
cmpl %eax, last_task_used_math
jne 1f
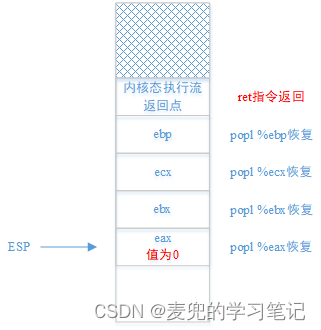
clts8.4.5.10 恢复寄存器
popl %eax
popl %ebx
popl %ecx
popl %ebp1. 首先需要特别注意的是,因为已经完成了内核栈的切换,此处恢复寄存器使用的是目标进程(next进程)的内核栈
2. 内核栈切换并恢复寄存器之后,prev & next进程的内核栈状态如下图所示,

8.4.5.11 切换内核态执行流
此时在next进程内核栈的基础上,通过ret指令就可以实现内核态执行流的切换,切换的目标地址是schedule函数中调用switch_to函数的返回地址

8.4.6 修改copy_process函数
copy_process函数的修改核心,就是将原先构造在TSS段中的新建进程初始状态改为保存在新建进程内核栈中。而修改的前提,就是分析清楚新建进程内核栈的最终构造
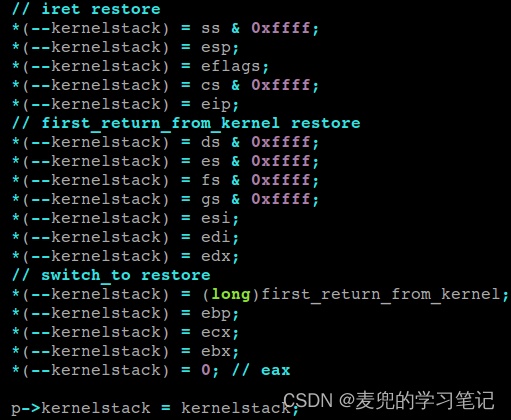
8.4.6.1 新建进程内核栈构造
1. 结合switch_to函数中的恢复寄存器和切换内核态执行流步骤,在新建进程时,在完成内核栈切换后的栈状态应该如下图所示,
2. 如上文分析,在执行iret指令进行用户态执行流切换时,内核栈的状态需要如下图所示
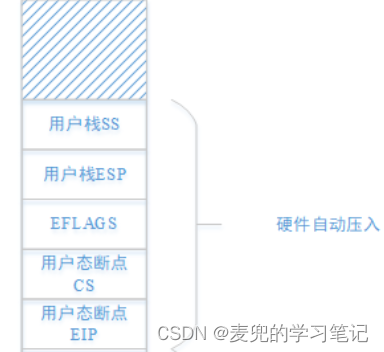
3. 对照上述两部分,剩余的寄存器需要在内核态执行流切换之后,用户态执行流切换之前进行恢复,因此最终新建进程内核栈的状态如下图所示,

说明:内核栈中ds到edx寄存器的布局没有硬性规定,只要和恢复处理流程匹配即可
4. 恢复ds到edx寄存器的操作由”内核态执行流返回点”程序执行,我们将其命名为first_return_from_kernel函数,在该函数完成恢复操作后,可以执行iret指令完成用户态执行流切换
8.4.6.2 copy_process函数修改
修改文件:kernel/fork.c
1. 注释掉copy_process函数中对进程TSS段的操作

说明:虽然我们不再操作新建进程的TSS段,但是并没有删除task_struct结构体中的tss_struct结构体
2. 获取新建进程内核栈栈顶
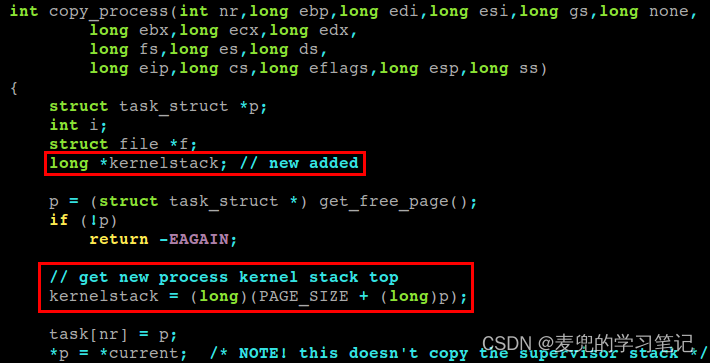
3. 构造新建进程内核栈
按照之前的分析,将父进程寄存器的值压栈即可
8.4.7 实现first_return_from_kernel函数
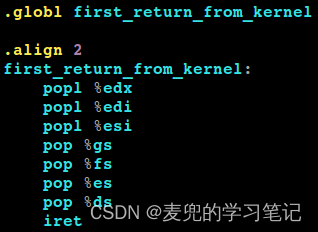
修改文件:将first_return_from_kernel函数也实现在kernel/switch_to.s文件中
first_return_from_kernel函数的核心就是按照新建进程内核栈的布局恢复寄存器,并且最终通过iret指令实现用户态执行流的切换
说明:父进程现场保存节点
① Linux 2.4内核的父进程现场保存节点为从用户态陷入内核态时
② Linux 0.11内核的父进程现场保存节点为调用copy_process函数时
8.5 上机验证
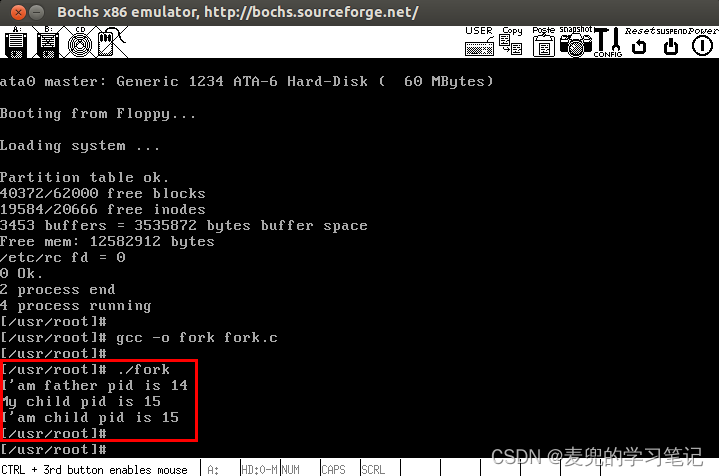
1. 修改后重新编译Linux 0.11内核,系统可以启动成功并正常运行
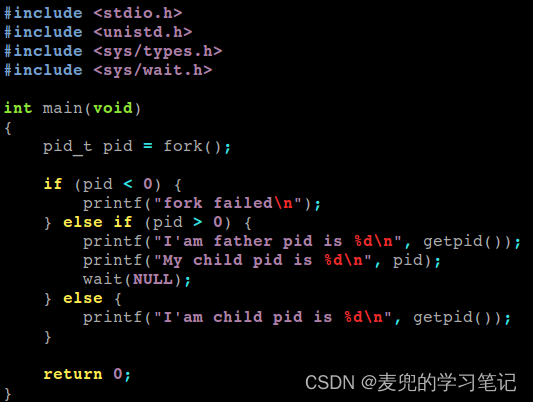
2. 使用如下测试用例验证fork系统调用
9 Linux 0.11内核定时器机制分析
说明:之所以将定时器机制的分析安排在本章,是因为在Linux 0.11内核中,定时器机制的实现在sched.c文件中
9.1 内核定时器结构
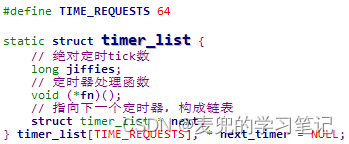
1. timer_list数组用于存储系统中的所有定时器,最多64个
2. next_timer指针为有序的定时器链表的头指针
9.2 添加内核定时器
9.2.1 add_timer函数调用分析
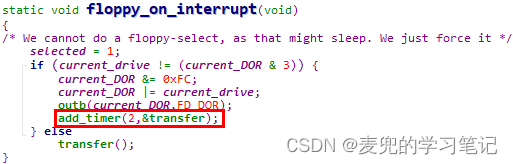
1. add_timer函数供内核模块注册定时器,参数为绝对定时tick值和定时器处理函数。当设置的定时值到期后,会调用定时器处理函数

2. 在Linux 0.11内核中,add_timer函数仅被do_fd_request和floppy_on_interrupt函数调用

9.2.2 add_timer函数实现分析

此处重点分析对定时器链表的排序方法,
// 前提:已有的定时器链表按升序保存递增定时值,新的定时器节点也按该规则插入
// p指针初值指向新增定时器节点
// 如果还有后继定时器节点,且后继定时器节点的递增定时值小于当前节点,则进入循环
while (p->next && p->next->jiffies < p->jiffies) {
// 计算当前节点的递增定时值
p->jiffies -= p->next->jiffies;
// 交换节点的定时器处理函数
fn = p->fn;
p->fn = p->next->fn;
p->next->fn = fn;
// 交换节点的递增定时值
jiffies = p->jiffies;
p->jiffies = p->next->jiffies;
p->next->jiffies = jiffies;
// 指向下一个节点
p = p->next;
}
1. 递增保存定时值
在对定时器链表进行排序的循环中,会将定时器的定时值修改为递增保存延时时间,即一个定时器的定时值 = 之前所有任务的定时值 + 本定时器的定时值

① 优点:处理定时器时,无需遍历定时器链表,只要从头开始处理即可
② 缺点:加入定时器时,需要对定时器链表进行排序,有开销
2. 交换节点内容而不是调整节点指针指向
在对定时器链表进行排序时,并不修改节点指针域的指向,而是直接交换节点的内容
说明1:定时器插入链表实例
假设在上图所示的定时器链表中插入绝对延时tick为8,定时器处理函数为timer3_func的定时器节点
① 首先将新增定时器加入表头

② 第一次循环处理后,新增定时器仍需后移

③ 第二次循环处理后,新增定时器处于正确的位置

说明2:根据上述对定时器插入流程分析,对于绝对定时tick相同的定时器,后插入的在前,先插入的在后
9.3 执行定时器

1. 在时钟中断处理函数中处理定时器链表
2. 由于已经将定时器按递增定时值升序组织在定时器链表中,所以处理比较简单。直接将定时器链表表头的定时器递增定时值减1,如果为0,则处理所有到期的定时器
3. 对于已经到期的定时器,除了调用其注册的定时器处理函数,还要
① 将fn字段置为NULL,标识该定时器结构体可被再次使用
② 将该定时器从定时器链表中删除