目录
2 线性模型
深度学习步骤
- 数据集 —— 拿到的训练集,要分成两部分,训练集,交叉验证集 和 测试集
- 模型
- 训练
- 推理
ML常用损失函数

模型可视化 visdom包
- 训练过程中,要存盘
- visdom 可视化
'''
线性模型——— 用直线 预测相关的值
'''
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
w_list =[]
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
print('w=', w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_pred_val, loss_val)
print("MSE=", l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
3 梯度下降
随机梯度下降:随机选一个点
批量梯度下降
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w=0
def forward(x):
return x*w
def cost (xs, ys):
cost = 0;
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost/len(xs)
def gradient(xs, ys):
grad = 0
for x,y in zip(xs, ys):
grad += 2*x*(x*w-y)
return grad / len(xs)
print("Predict (before training", 4, forward(4))
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('Epoch:',epoch, 'w=',w,'loss=', cost_val)
print('predict(after training', 4, forward(4))
4 反向传播
矩阵的求导公式
matirx cookbook
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0])
w.requires_grad = True
def forward(x):
return x*w
# w is a tensor type variable
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print("predict:", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x,y)
l.backward() # 自动计算梯度,并且反向传播
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print("progress:", epoch, l.item())
print("predict", 4, forward(4).item())
5 用pytorch 实现线性回归
确定模型,,定义损失函数,优化损失函数
准备数据集,用类设计模型,,构造损失函数和优化器,,写训练周期(前馈,反馈,更新)
numpy中的自动广播机制
不同维度的矩阵,是不能直接进行加法的
所以,在numpy中,会 把维度小的向量,自动复制成维度大的向量
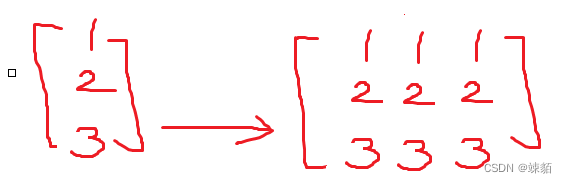
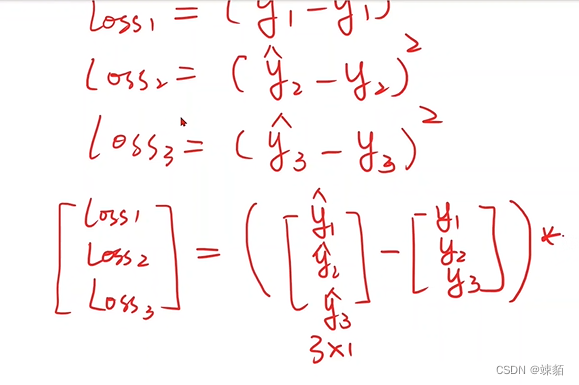
线性单元—— y = w*x+b
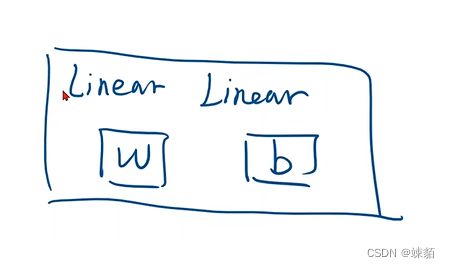

函数中传递参数,常用的形式
def func(*args, **kwargs):
print(args)
print(kwargs)
func(1,2,4,3, x=3, y=5)
(1, 2, 4, 3)
{'x': 3, 'y': 5}
*arg : 可以传递很多参数,会进行自动匹配,,结果是一个元组
**kwargs : 是作为一个字典使用
模型训练
#训练模型
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss)
optimizer.zero_grad() # 梯度归0
loss.backward()
optimizer.step()
训练过程,其实就是,先算y_pred, 计算损失函数,,反向传播,,更新参数,四部分组成
import torch
x_data = torch.tensor( [ [1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0] ])
class LinearModel(torch.nn.Module):
def __init__(self): #构造函数
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# 损失函数
criterion = torch.nn.MSELoss(size_average=False) # false表示不求均值
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# model.parameters() : 告诉模型,,要对哪些参数进行优化
#训练模型
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 梯度归0
loss.backward()
optimizer.step()
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred =', y_test.data)
6 逻辑回归——分类
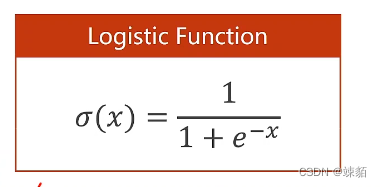
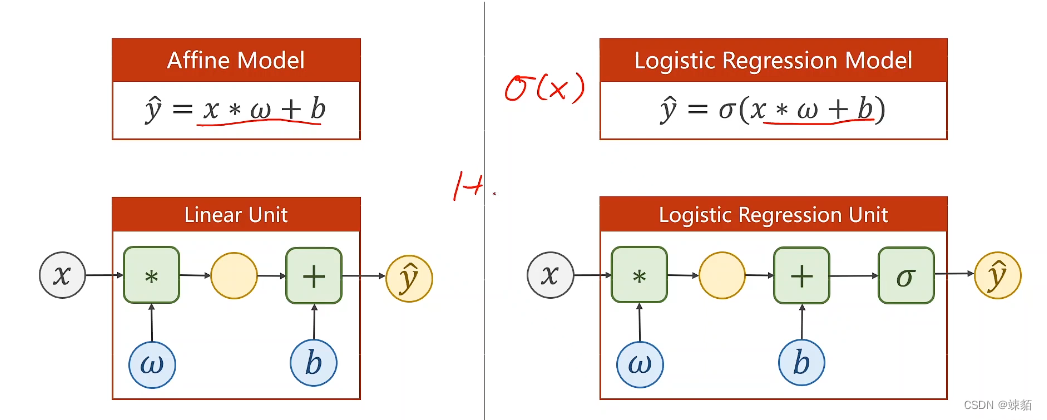
逻辑回归损失函数

上述函数被称为,,BCE损失函数
import torchvision
import torch
import torch.nn.functional as F
# train_set = torchvision.datasets.MNIST(root='./dataset/mnist', train=True, download=True)
# test_set = torchvision.datasets.MNIST(root='./dataset/mnist', train=False, download=True)
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[0.0], [0], [1]])
# 逻辑回归
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
# y_pred = F.sigmoid(self.linear(x))
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# 交叉熵损失函数 —— BCE
criterion = torch.nn.BCELoss(size_average=False) # false表示不求均值
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#训练模型
for epoch in range(100):
y_pred = model(x_data)
# y_pred = y_pred.to(torch.float32)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 梯度归0
loss.backward()
optimizer.step()
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred =', y_test.data)
7. 处理多特征的输入
矩阵就是 一个空间变换的方程,,线性模型,,几乎都用矩阵实现的
用 sigmoid函数,,给线性变换,增加非线性因素
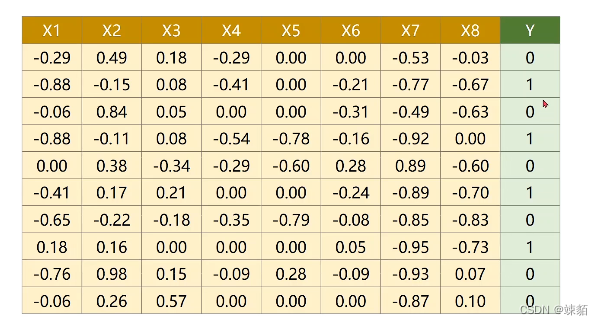
糖尿病病情是否加重,,保险费是否增加等等,这种二分类的问题,,往往使用线性回归解决
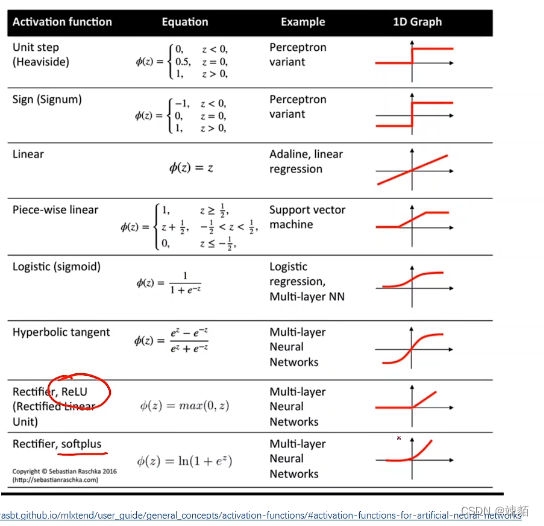
各种各样的激活函数
数据混在一起,前几列是训练数据,后一列是标签,如何分割?
import numpy as np
import torch
xy = np.loadtxt('iris.csv', delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # 所有行,只要最后一列
# 需要一个矩阵,,所有,又加了一个中括号
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(4,2)
self.linear2 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
model = Model()
# 二分类的任务
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(10000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
损失函数绘图(有坑)
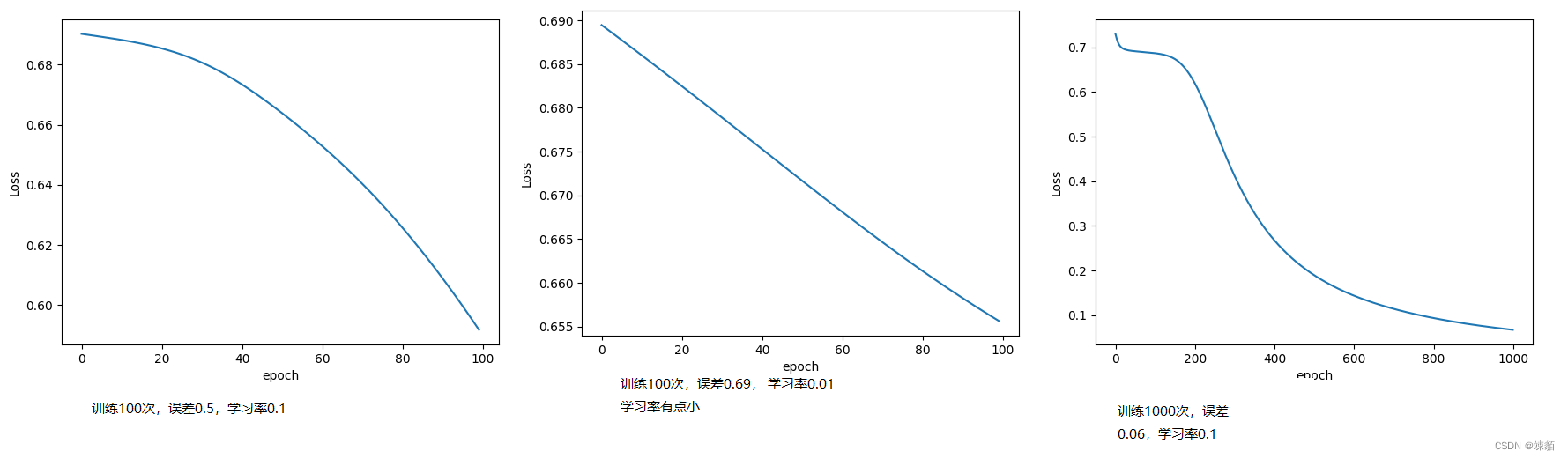
import numpy as np
import torch
import matplotlib.pyplot as plt
xy = np.loadtxt('iris.csv', delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # 所有行,只要最后一列
# 需要一个矩阵,,所有,又加了一个中括号
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(4,2)
self.linear2 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
model = Model()
# 二分类的任务
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
total_loss = []
total_epoch = []
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# 损失函数绘图
total_loss.append(loss.detach().numpy())
total_epoch.append(epoch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#损失函数绘图
plt.plot(total_epoch, total_loss)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
8 加载数据集
Dataset自定义

如果数据集不够大,那就直接在 init()函数中,初始化,读取到内存中,,如果数据集很大,,那init()函数只留下文件名即可,,到getitem()函数在具体读数据
windows多线程,有坑,,要这么写

import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
# 数据都加载到内存中
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('iris.csv')
train_loader = DataLoader(dataset=dataset, batch_size=10, shuffle=True, num_workers=1)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(4, 2)
self.linear2 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 这里不加 main的话,,会报错
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
9 多分类问题
损失函数——交叉熵
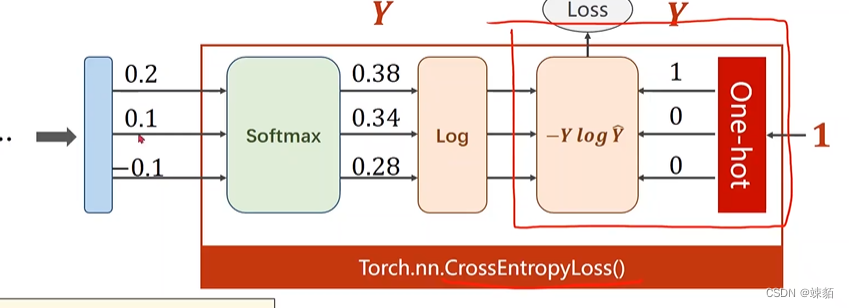
弄清楚,交叉熵损失函数,,和 其他损失函数的区别?

满足正态分布的数据,神经网络训练是最好的
因为全连接的神经网络,对于,数据局部信息把握的不是特别好,所以训练误差到0.03就很难优化了
Mnist 数字分类
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
# 均值 和标准差,,为了能把图像数据映射成 (0,1)分布
])
train_dataset = datasets.MNIST(root='./dataset/mnist',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False,)
# 2.构建网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # 展开,改变形状,,把图片,变成线性的!!
x = F.relu(self.l1(x))
x = F.relu((self.l2(x)))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练 —— 把一轮循环 封装成函数
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# 优化器清零
# 前馈,反馈,更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' %(epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
def test():
corret = 0
total = 0
with torch.no_grad(): # 测试集不需要计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # 返回两个值,一个是最大值,一个最大值下标
total += labels.size(0)
corret += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' %(100*corret / total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
test()
实验结果:
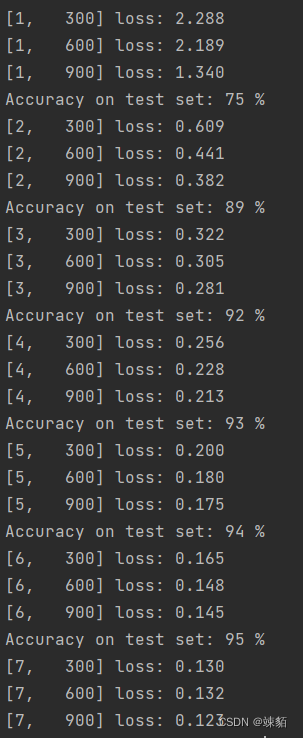
10 CNN (基础)
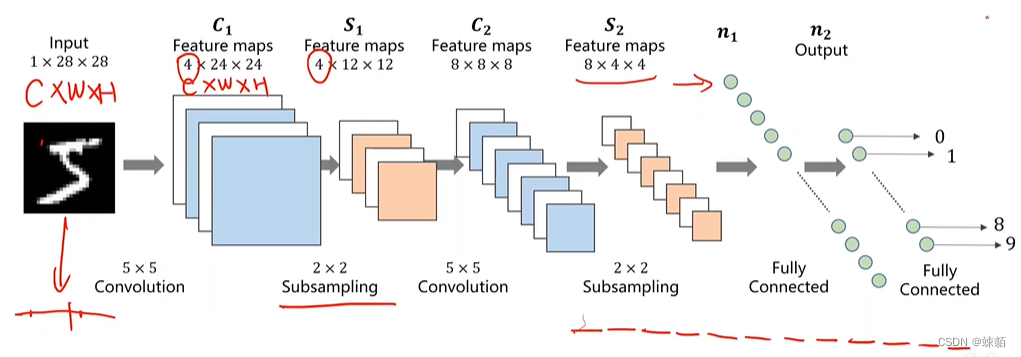
卷积层——保留图像的空间信息,用于提取图像特征
用于提取图像特征
下采样——通道数不变,降低运算量
构建神经网络时,要明白,输入是什么,输出是什么
栅格图像 和 矢量图像
栅格图像:像素点组成,放大失真
矢量图像:圆心,,位置,坐标,颜色,等等,放大不失真
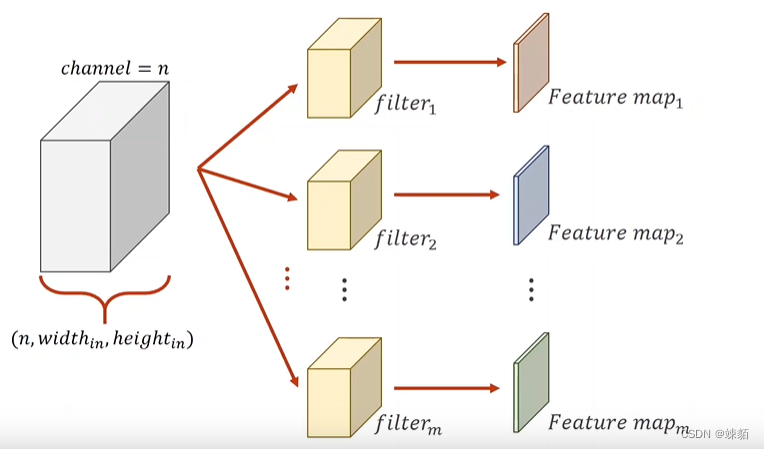
卷积之后,M通道是如何实现的?
有多个卷积核,,每个核心,得到一道通道,
mnist 书写数字识别
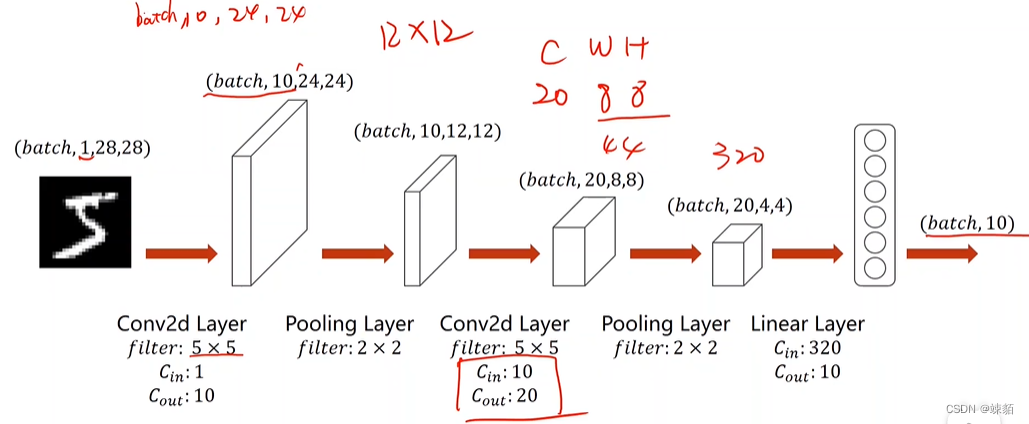
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
# 均值 和标准差,,为了能把图像数据映射成 (0,1)分布
])
train_dataset = datasets.MNIST(root='./dataset/mnist',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False,)
# 2.构建网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0) # 这一步在干什么 ,得到样本数量
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, 320)
x = self.fc(x) # 交叉熵损失函数,最后一层没有激活函数,请注意
return x
model = Net()
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练 —— 把一轮循环 封装成函数
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# 优化器清零
# 前馈,反馈,更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' %(epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
def test():
corret = 0
total = 0
with torch.no_grad(): # 测试集不需要计算梯度
for data in test_loader:
images, labels = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # 返回两个值,一个是最大值,一个最大值下标
total += labels.size(0)
corret += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' %(100*corret / total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
test()
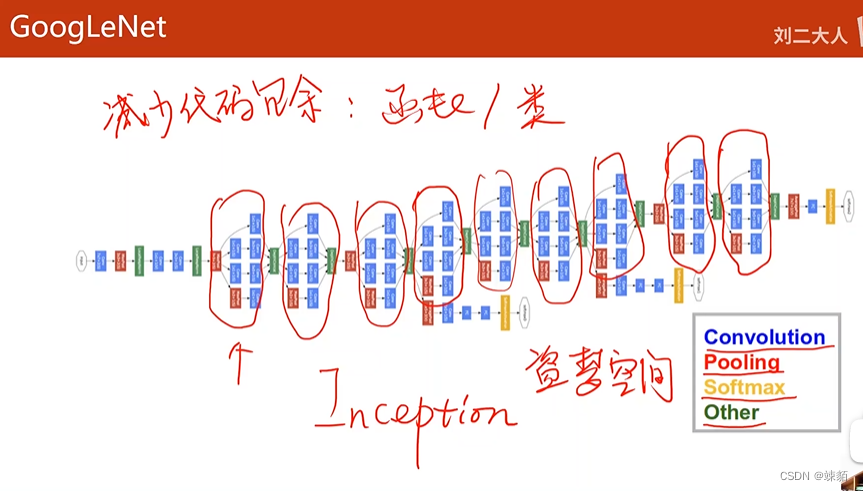
11 CNN(advanced)
GoogleNet
1*1 卷积核,有什么用?
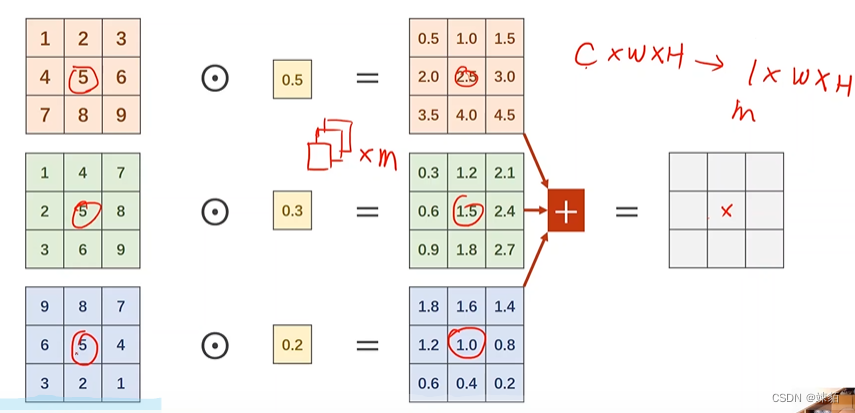
多通道的信息融合
用1*1的卷积,,可以改变通道数量,却不改变图像的大小,,可以改变计算量
192 * 28 28 —> 16128 * 128
inception
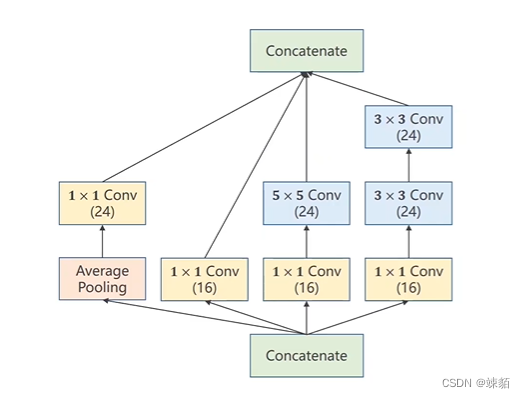
实现代码: 更改网络实现方法
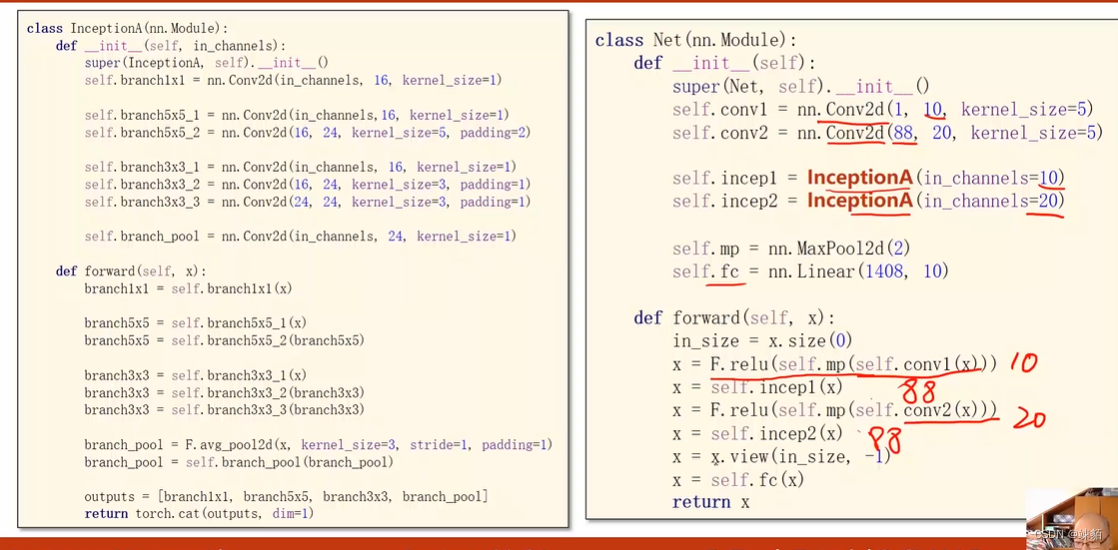
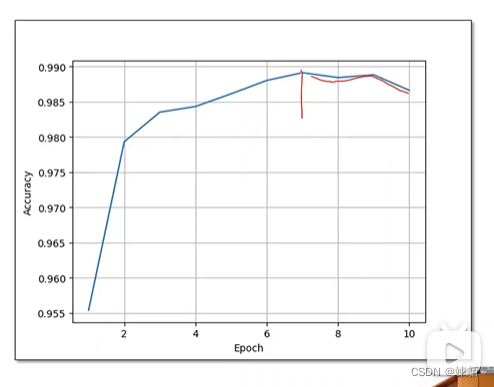
观察test来决定,网路训练多少轮比较合适
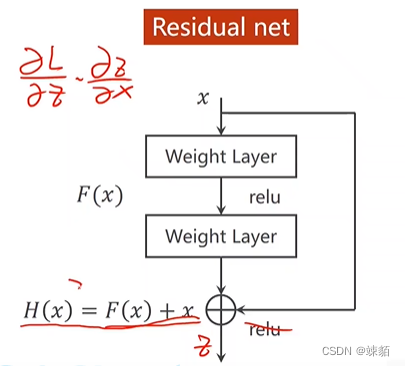
residual net —— 能解决梯度消失问题
并不是网络层数越深,训练效果越好
有可能是过拟合,也有可能是梯度消失
梯度消失,误差就不能及时的传播和更新参数,就导致,效果不好
网络架构
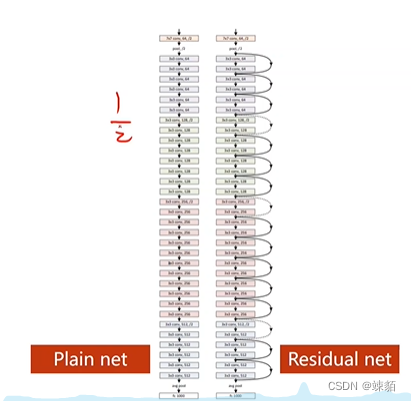
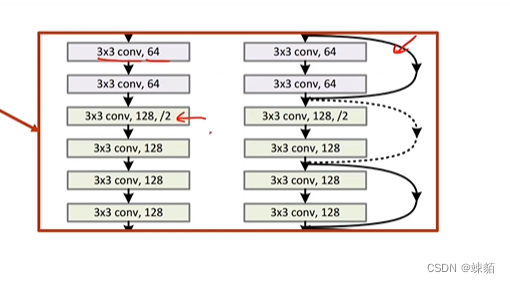
如何实现


找论文

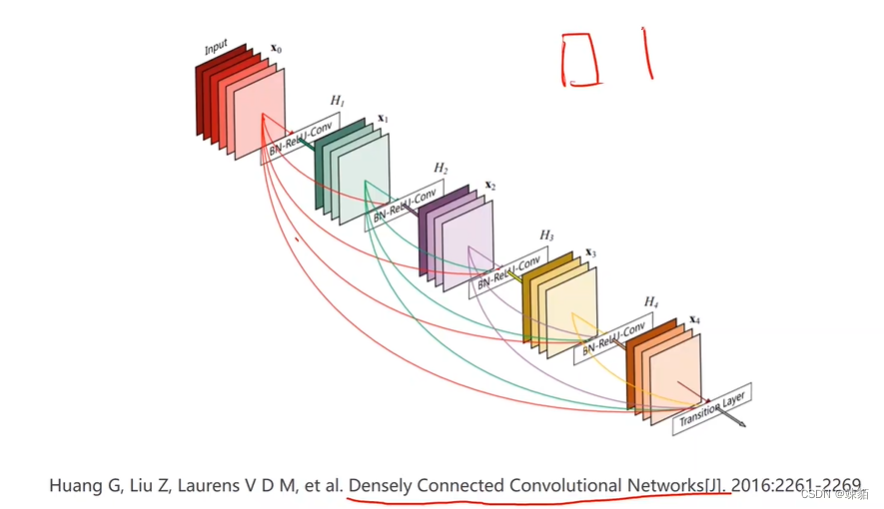
12 循环神经网络 basic RNN
循环神经网络 : 对于线性层的复用
处理带有序列的关系,,即前后之间有顺序的,比如,天气,股市,自然语言处理
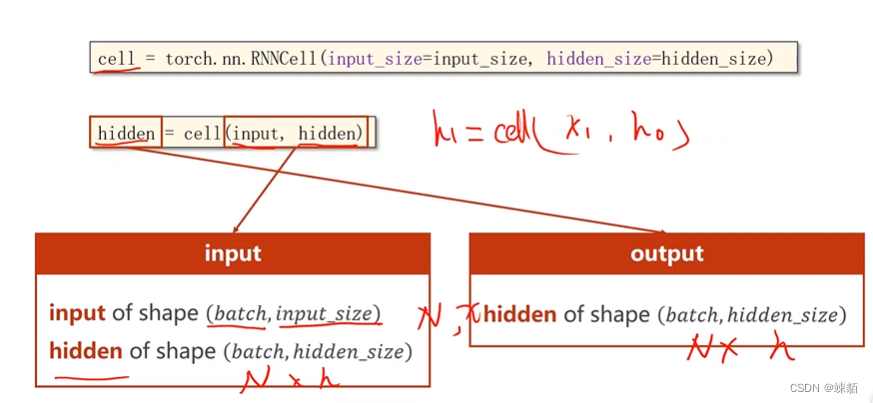
RNN cell
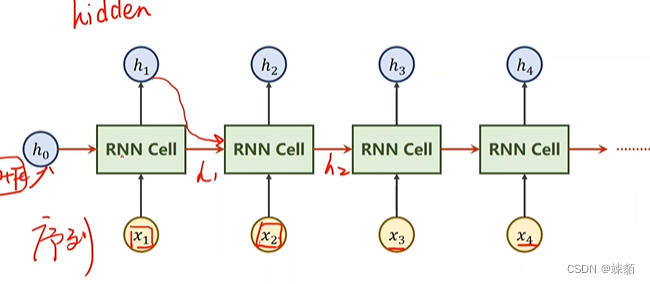
RNN cell 是同一个线性层,权重不变
RNN中喜欢用 tanh作为激活函数
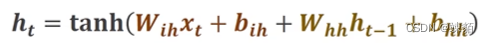
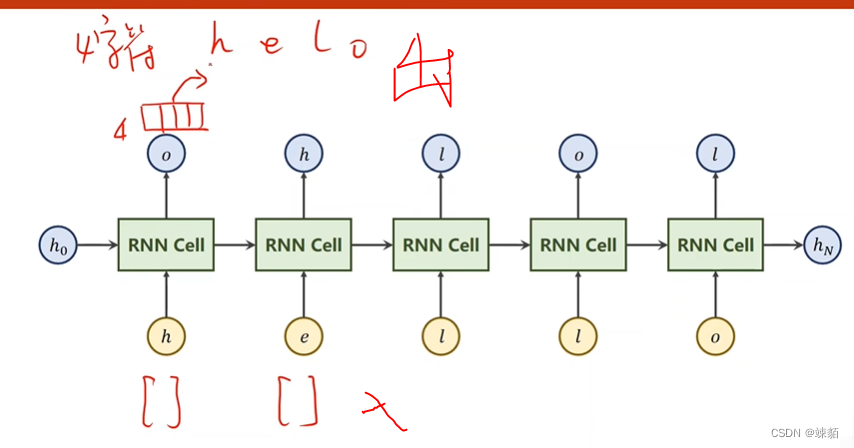
学习序列 ‘hello’ -> ‘ohlol’
直接,字母是没办法转化成序列的
对于字母进行处理,,,构成索引,,对字符串进行处理
变成向量(矩阵)
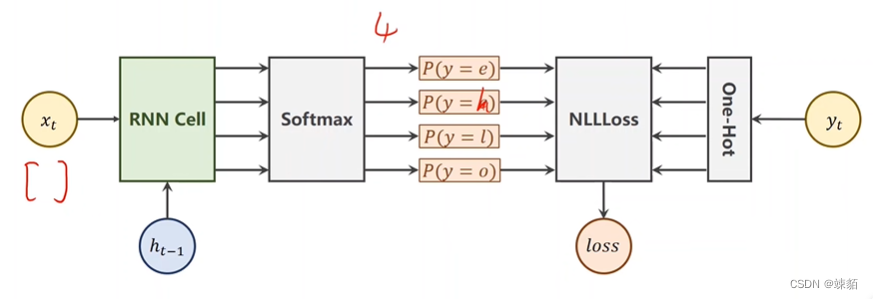
RN使用 NLLLoss
都热向量缺点
维度太高,稀疏,非学习得到
解决办法
可以用嵌入层,把独特向量,变成 稠密的表示
准备数据,构造模型,损失函数和优化器,训练模型
LSTM 计算能力差
GRU 是LSTM 和 RNN 的折中
学习序列 ‘hello’ -> ‘ohlol’
输入是:41 的向量
输出是:14 的向量,表示属于某个类别的概率,其实是个分类问题

# 还在报错
import torch
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
ont_hot_lookup = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
]
x_ont_hot = [ont_hot_lookup[x] for x in x_data] # 值是1,就取 one-hot向量的第一行
# inputs 维度 : (seqLen, batchSize, inputSize)
inputs = torch.tensor(x_ont_hot).view(-1, batch_size, input_size)
# labels维度: (seqSize, 1)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('predicted string:', end='')
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(',Epoch[%d/15 loss=%.4f' %(epoch+1, loss.item()))