目录
Hudi源码编译
第一步:下载Maven并安装且配置Maven镜像
第二步:下载Hudi源码包(要求对应Hadoop版本、Spark版本、Flink版本、Hive版本)
第三步:执行编译命令,完成之后运行hudi-cli脚本,如果可以运行,则说明编译成功
https://github.com/apache/hudi官网查看不同版本的编译命令,要一一对应
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FBqXKEAY-1654954849724)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112136722.png)]](https://img-blog.csdnimg.cn/bfc7feaafb0048bba63870df9ef87935.png)
Hudi大数据环境准备
安装HDFS
安装Spark
安装Flink
Hudi扫盲
表数据结构
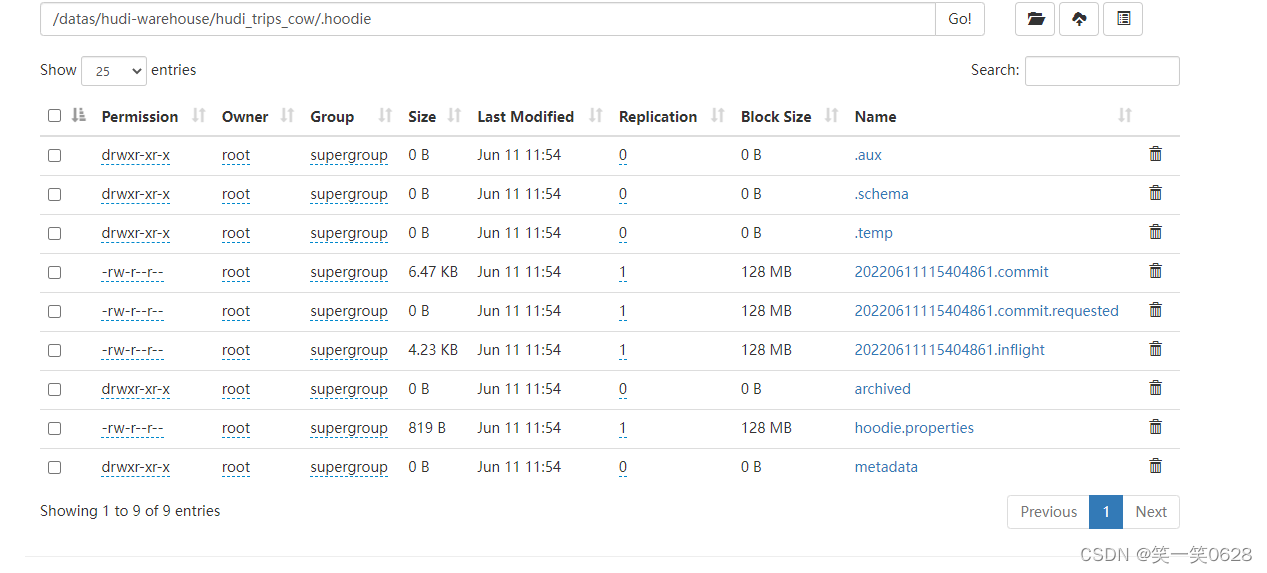
Hudi表的数据文件,分为两类,一类是.hoodie文件,一类是实际的数据文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5g4FprIQ-1654955084436)(../AppData/Roaming/Typora/typora-user-images/image-20220611124122225.png)]](https://img-blog.csdnimg.cn/2e724576cd634298b58ba6b26ee5ab88.png)
.hoodie文件:由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多以后,会严重影响HDFS的性能,Hudi因此设计了一套文件合并机制,.hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
Hudi把随着时间流逝,对表的一系列CRUD操作叫做TimeLine,TimeLine中某一次的操作,叫做Instant。
Instant Action:记录本次操作是一次数据提交commit,还是文件合并compaction,或者是文件清理cleans
Instant Time:本次操作的时间
Instant State:操作的状态,发起requested、进行中inflight、已完成commit
数据文件:Hudi真实的数据文件使用Parquet文件格式存储,其中包含了一个metadata元数据文件和数据文件parquet列式存储。
Hudi为了实现数据的CURD,需要能够唯一标识一条记录,Hudi将把数据集中的唯一字段(record key)+数据所在分区(partitionPath)联合起来当作数据的唯一主键。
基于Spark-shell集成Hudi
目的:使用spark-shell命令行,以本地模式方式运行,模拟产生trip乘车交易数据,将其保存至Hudi表中,并且从Hudi表加载数据查询分析,其中Hudi表数据最后存储在HDFS分布式文件系统中。
启动spark-shell
以下命令需要联网,--packages会基于ivy下载相关jar包到本地,然后加载到CLASSPATH中
spark-shell \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.11.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
通过--jars指定本地依赖(需要把jar包放入Spark的lib目录下,或者指定jar包的全局路径
bin/spark-shell \
-- jars hudi-spark3.2-bundle_2.12-0.11.0.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9LZst6KA-1654954849734)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112138684.png)]](https://img-blog.csdnimg.cn/e0d47b403952468594b6c089856d69af.png)
导入相关依赖,构建DataGenerator模拟生成乘车数据
# 导入Spark和Hudi的相关依赖包
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
# 定义表的名称和数据的存储路径
val tableName = "hudi_trips_cow"
val basePath = "hdfs://bigdata:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
# 模拟生成10条数据
val inserts = convertToStringList(dataGen.generateInserts(10))
# 将模拟数据转化为DataFrame数据集
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l2rEN5kr-1654954849735)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112137284.png)]](https://img-blog.csdnimg.cn/8e647fc85ea04a6883cfd0f3443c92e9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wZ15mtpx-1654954849736)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112137842.png)]](https://img-blog.csdnimg.cn/5e5aac0c35fe445b928ea47e3f706a6f.png)
插入数据
将模拟产生的数据保存到Hudi表中,直接通过format指定数据源source,设置相关属性保存即可
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
getQuickstartWriteConfigs:设置写入/更新数据至Hudi时,Shuffle时分区数目,可以在源码中看到

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RRC4As8K-1654954849738)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112138547.png)]](https://img-blog.csdnimg.cn/a14febcd6e2c4ef2a145e8a62a661c45.png)
PRECOMBINE_FIELD_OPT_KEY:数据合并时,依据主键字段·
RECORDKEY_FIELD_OPT_KEY:每条记录的唯一id,支持多个字段
PARTITIONPATH_FIELD_OPT_KEY:用于存放数据的分区字段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OfWtV7kS-1654954849739)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112138172.png)]](https://img-blog.csdnimg.cn/7c99c77bb05f45768fc0e95dbcdb8719.png)
数据保存之后,可以在HDFS上看到,路径为设置的save路径,并且可以看到,数据是以PARQUET列式方式进行存储的
查询数据
从Hudi表中读取数据,通过指定format数据源和相关参数Options即可
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
# 打印获取Hudi表数据的Schema信息
tripsSnapshotDF.printSchema()
比原先保存到Hudi表中的数据多了5个字段,这些字段属于Hudi管理数据时使用的相关字段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u10aEFxN-1654954849739)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112138001.png)]](https://img-blog.csdnimg.cn/7ce4825921354e2188c1bc77e36da26a.png)
将获取Hudi表数据注册为临时视图,采用SQL方式依据业务查询分析数据
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
# 查询乘车费用大于20的信息数据
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
# 选取字段查询数据
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WevyWBSu-1654954849740)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112138553.png)]](https://img-blog.csdnimg.cn/fadace10454c4bb5b2eaf29cae55a524.png)
基于Spark-Hive集成Hudi手动创建HIVE表
环境准备
在Hive中创建表关联至Hudi表,将集成JAR包hudi-hadoop-mr-bundle-0.11.0.jar,放入HIVE的 lib目录下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gVaX0i2p-1654954849740)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139732.png)]](https://img-blog.csdnimg.cn/7cace3d75c8e47fe8894f3adba28ef65.png)
创建数据库和表
连接HIVE
# 启动metastore
hive --service metastore
# 启动hiveserver2
hiveserver2
# 启动beeline
bin/beeline -u jdbc:hive2://bigdata:10000 -n root -p root
通过Spark将数据写入Hudi表之后,要想通过Hive访问到这块数据,就需要创建一个Hive外部表,因为Hudi配置了分区,所以为了能读到所有的数据,此时外部表也得分区,分区字段名可随意配置。
# 创建数据库
create database db_hudi;
# 使用数据库
use db_hudi;
# 创建hive外部表
CREATE EXTERNAL TABLE `tbl_hudi_trips`(
`begin_lat` double,
`begin_lon` double,
`driver` string,
`end_lat` double,
`end_lon` double,
`fare` double,
`partitionpath` string,
`rider` string,
`uuid` string,
`ts` bigint
)
PARTITIONED BY (country string,province string,city string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'/datas/hudi-warehouse/hudi_trips_cow';
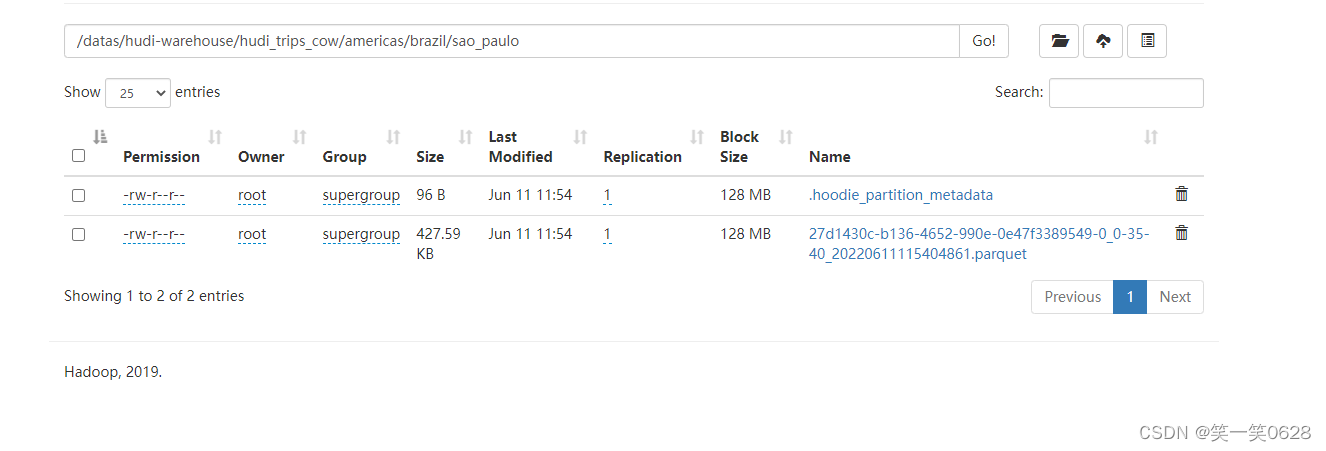
由于Hudi表属于分区表,所以Hive创建的表也是分区表,需要手动添加分区数据
# 分配分区
alter table tbl_hudi_trips add if not exists partition(`country`='americas',`province`='brazil',`city`='sao_paulo') location '/datas/hudi-warehouse/hudi_trips_cow/americas/brazil/sao_paulo';
alter table tbl_hudi_trips add if not exists partition(`country`='americas',`province`='united_states',`city`='san_francisco') location '/datas/hudi-warehouse/hudi_trips_cow/americas/united_states/san_francisco';
alter table tbl_hudi_trips add if not exists partition(`country`='asia',`province`='india',`city`='chennai') location '/datas/hudi-warehouse/hudi_trips_cow/asia/india/chennai';
# 查看分区
SHOW PARTITIONS tbl_hudi_trips;
# 查询表
select * from tbl_hudi_trips;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AnWW3voX-1654954849741)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139386.png)]](https://img-blog.csdnimg.cn/f8c365db45a24f4e9d716734e98a5500.png)
基于SparkSQL集成Hudi自动创建HIVE表
启动Spark-sql,给个版本启动方式根据官网说明
spark-sql \
--master local[2] \
-- jars /opt/module/spark-3.2.1-bin-hadoop3.2/jars/hudi-spark3.2-bundle_2.12-0.11.0.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
设置参数,Hudi的默认并发度是1500
set hoodie.upsert.shuffle.parallelism=1;
set hoodie.insert.shuffle.parallelism=1;
set hoodie.delete.shuffle.parallelism=1;
设置不同步Hudi表元数据(默认为true,会自动根据SparkSQL设置的进行分区,置为false,需要手动建立分区)
set hoodie.datasource.meta.sync.enable=false;
创建表,表的类型为COW,主键为uuid,分区字段为partitionpath,合并字段默认为ts
# 创建表时,指定location存储路径,表就是外部表
CREATE TABLE test_hudi_hive(
`begin_lat` double,
`begin_lon` double,
`driver` string,
`end_lat` double,
`end_lon` double,
`fare` double,
`partitionpath` string,
`rider` string,
`uuid` string,
`ts` bigint
) using hudi
PARTITIONED BY (partitionpath)
options (
primarykey='uuid',
type='cow'
)
location 'hdfs://bigdata:8020/datas/hudi-warehouse/hudi_spark_sql/';
# 查看创建后的表
show create table test_hudi_hive;
# 插入数据,会建立一个china分区
insert into test_hudi_hive select 0.1 as begin_lat, 0.2 as begin_lon, 'driver-1' as driver, 0.3 as end_lat, 0.4 as end_lon, 35 as fare, 'china' as partitionpath, 'rider-1' as rider, 'uuid-1' as uuid, 1654447758530 as ts;
# 插入数据,会建立一个america分区
insert into test_hudi_hive select 0.1 as begin_lat, 0.2 as begin_lon, 'driver-2' as driver, 0.3 as end_lat, 0.4 as end_lon, 35 as fare, 'america' as partitionpath, 'rider-2' as rider, 'uuid-2' as uuid, 1654447758531 as ts;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9xDRA3Na-1654954849742)(../AppData/Roaming/Typora/typora-user-images/image-20220611155639086.png)]](https://img-blog.csdnimg.cn/5cee74cc3cba4daf8d959f542d5a546a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GNr0IrLq-1654954849743)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139952.png)]](https://img-blog.csdnimg.cn/dbe2c8a4609c471d994d7b7600ada1fe.png)
基于FlinkSQL集成Hudi
Flink集成Hudi时,需要把hudi-flink1.13-bundle_2.11-0.11.0.jar,放到FLINK_HOME的lib目录下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lEqqaxRG-1654954849744)(../AppData/Roaming/Typora/typora-user-images/image-20220611163947941.png)]](https://img-blog.csdnimg.cn/aee3fadf17d14b939ea76cbd6a011474.png)
根据官网的说明,修改conf下的配置为文件flink-conf.yaml。给TaskManager分配Slots>=4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vNQ3Fzl1-1654954849745)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139076.png)]](https://img-blog.csdnimg.cn/fbbc144cb4bf428ab120f068cf044443.png)
配置之后启动FLINK集群bin/start-cluster.sh,如果在后续操作中报错类似找不到hadoop的类,则需要暴露一下hadoop的环境变量
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
启动FLINK SQL CLI
bin/sql-client.sh --embedded
创建表table
将数据存储到Hudi表中,底层HDFS存储,表的类型为MOR
# 更方便的展示数据
set execution.result-mode=tableau;
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://bigdata:8020/hudi-warehouse/hudi-t1',
'write.tasks' = '1',
'compaction.tasks' = '1',
'table.type' = 'MERGE_ON_READ'
);
插入数据
INSERT INTO t1 VALUES
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
在Flink集群上验证任务的执行状态,和Hadoop落盘的数据,已经验证SQL查询
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yDGIl6Sw-1654954849746)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139213.png)]](https://img-blog.csdnimg.cn/01132b393b8e4aa08d7f28eef80b8096.png)
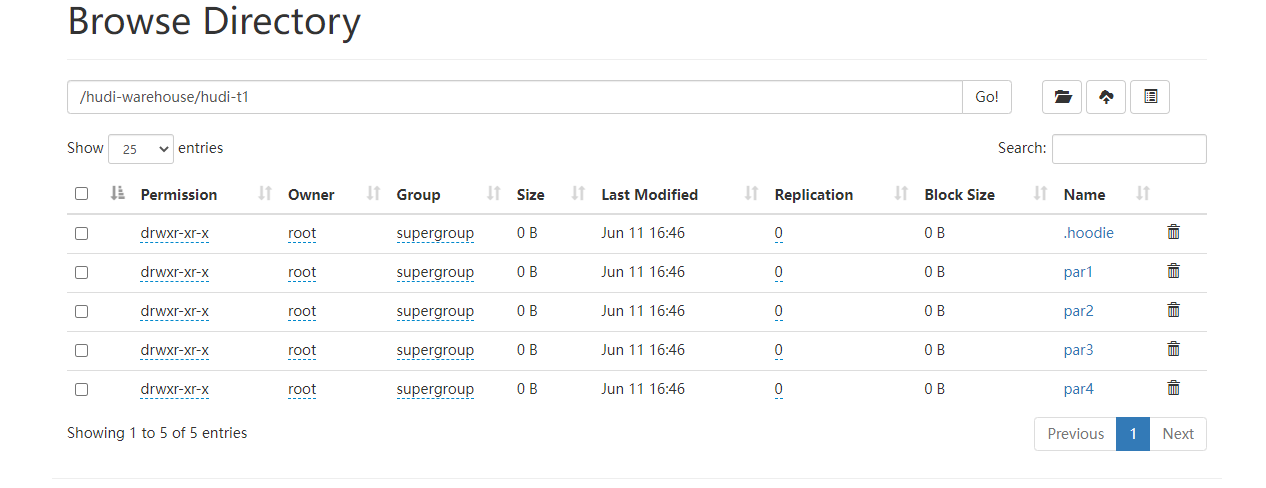
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f1Gpe36i-1654954849747)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139257.png)]](https://img-blog.csdnimg.cn/35b0d0fdf61547e08ca9ad1fc0e7ed39.png)
基于FlinkSQL-HIVE集成Hudi手动创建HIVE表
# 一定要设置checkpointing的时间,要么命令行,要么配置文件中
set execution.checkpointing.interval=3sec;
创建输出表,MERGE_ON_READ类型的会生成log文件,不会生成parquet文件。COPY ON WRITE类型的会生成parquet文件,不会生成log文件。
CREATE TABLE flink_hudi_sink (
uuid STRING PRIMARY KEY NOT ENFORCED,
name STRING,
age INT,
ts STRING,
`partition` STRING
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://bigdata:8020/hudi-warehouse/flink_hudi_sink',
'table.type' = 'COPY_ON_WRITE',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field'= 'uuid',
'write.precombine.field' = 'ts',
'write.tasks'= '1',
'compaction.tasks' = '1',
'compaction.async.enabled' = 'true',
'compaction.trigger.strategy' = 'num_commits',
'compaction.delta_commits' = '1'
);
INSERT INTO flink_hudi_sink VALUES
('id2','Stephen',33,'1970-01-01 00:00:02','par1'),
('id3','Julian',53,'1970-01-01 00:00:03','par2'),
('id4','Fabian',31,'1970-01-01 00:00:04','par2'),
('id5','Sophia',18,'1970-01-01 00:00:05','par3'),
('id6','Emma',20,'1970-01-01 00:00:06','par3'),
('id7','Bob',44,'1970-01-01 00:00:07','par4'),
('id8','Han',56,'1970-01-01 00:00:08','par4');
由于Hive的读取,需要有生成的parquet文件,因此 'table.type' = 'COPY ON WRITE'是必须的。如果看到Hadoop中生成了parquet文件说明成功,则只需要手动创建Hive外部表和指定分区关联Hudi表即可。
# 创建hive外部表
CREATE EXTERNAL TABLE `flink_hudi_sink`(
`uuid` string,
`name` string,
`age` int,
`ts` string,
`partition` string
)
PARTITIONED BY (part string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'/hudi-warehouse/flink_hudi_sink';
# 分配分区
alter table tbl_hudi_trips add if not exists partition(`part`='pat1') location '/hudi-warehouse/flink_hudi_sink/par1';
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v2aaYh6j-1654954849748)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139206.png)]](https://img-blog.csdnimg.cn/596f3068944c40008cbe366ebf7f0bf6.png)
基于FlinkSQL集成Hudi-自动创建Hive表
Hudi集成Flink和Hive编译依赖版本配置,查看源码包hudi-0.11.0/packaging/hudi-flink-bundle下的pom.xml文件,Hive2的打包和Hive3的打包不一样,根据自身的HIVE类型选择,打包命令如下,具体的版本根据官网模仿
mvn clean install -DskipTests -Drat.skip=true -Dflink1.13 -Dscala-2.11 -Pflink-bundle-shade-hive3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QQIFoPBp-1654954849748)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112139046.png)]](https://img-blog.csdnimg.cn/40488d68d66849058f7d10f8838417bd.png)
编译之后将hudi-flink1.13-bundle_2.11-0.11.0.jar拷贝到FLINK的lib目录下和hudi-hadoop-mr-bundle-0.11.0.jar拷贝到HIVE的lib目录下(具体根据版本而定)
以COPY ON WRITE方式创建表自动同步HIVE分区表
set execution.checkpointing.interval=3sec;
set sql-client.execution.result-mode=tableau;
CREATE TABLE czs_hudi_hive (
uuid STRING PRIMARY KEY NOT ENFORCED,
name STRING,
age INT,
ts STRING,
`partition` STRING
)
PARTITIONED BY (`partition`)
WITH (
'connector'='hudi',
'path'= 'hdfs://bigdata:8020/czs_hudi_hive',
'table.type'= 'COPY_ON_WRITE',
'hoodie.datasource.write.recordkey.field'= 'uuid',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://bigdata:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://bigdata:10000',
'hive_sync.table'= 'czs_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= 'root',
'hive_sync.support_timestamp'= 'true'
);
INSERT INTO czs_hudi_hive VALUES
('id2','Stephen',33,'1970-01-01 00:00:02','par1'),
('id3','Julian',53,'1970-01-01 00:00:03','par2'),
('id4','Fabian',31,'1970-01-01 00:00:04','par2'),
('id5','Sophia',18,'1970-01-01 00:00:05','par3'),
('id6','Emma',20,'1970-01-01 00:00:06','par3'),
('id7','Bob',44,'1970-01-01 00:00:07','par4'),
('id8','Han',56,'1970-01-01 00:00:08','par4');
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LiGot2KY-1654954849749)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112140568.png)]](https://img-blog.csdnimg.cn/5b009130a1dc4e279c82edb0e4bf93e7.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bbd1PvVA-1654954849755)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112140315.png)]](https://img-blog.csdnimg.cn/ab4aeca14318418e974edab88fdfc968.png)
基于FlinkCDC采集MySQL写入Hudi
添加FlinkCDC依赖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ysFnlECs-1654954849756)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112140492.png)]](https://img-blog.csdnimg.cn/3dac1704c13d4916834bdbc0dc4bdd85.png)
添加Hadoop依赖
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
创建MERGE_ON_READ类型的Hudi表
set execution.checkpointing.interval=3sec;
set sql-client.execution.result-mode=tableau;
CREATE TABLE users_source_mysql (
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'bigdata',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'server-time-zone' = 'Asia/Shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'hudi',
'table-name' = 'tbl_users'
);
create view view_users_cdc
AS
SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') as part FROM users_source_mysql;
CREATE TABLE users_sink_hudi_hive(
id bigint ,
name string,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
part VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (part)
with(
'connector'='hudi',
'path'= 'hdfs://bigdata:8020/czs_hudi_hive_test',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://bigdata:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://bigdata:10000',
'hive_sync.table'= 'czs_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= 'root',
'hive_sync.support_timestamp'= 'true'
);
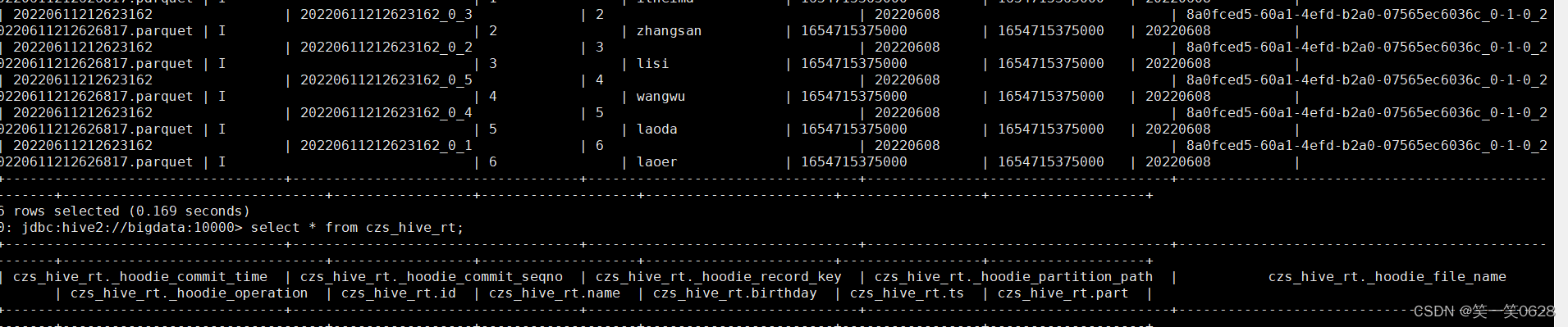
INSERT INTO users_sink_hudi_hive SELECT id, name, birthday, ts, part FROM view_users_cdc ;
自动生成Hudi MOR模式的两张表
xxx _ro:ro表全称为read oprimized table对于MOR表同步的xxx_ro表,只暴露压缩后的parquet。
xxx_rt:rt表示增量视图,主要针对增量查询的rt表,
ro表只能查询parquet文件数据,rt表parquet文件数据和log文件数据都可查
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RTWHd0oj-1654954849757)(https://raw.githubusercontent.com/czshh0628/blogs/master/202206112140612.png)]](https://img-blog.csdnimg.cn/dd19d46eca9246bfbd90350e983249f4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hxysH7rq-1654954849757)(../AppData/Roaming/Typora/typora-user-images/image-20220611213057980.png)]](https://img-blog.csdnimg.cn/4a40b4b1c52b4cc097a46e35a90bd18d.png)
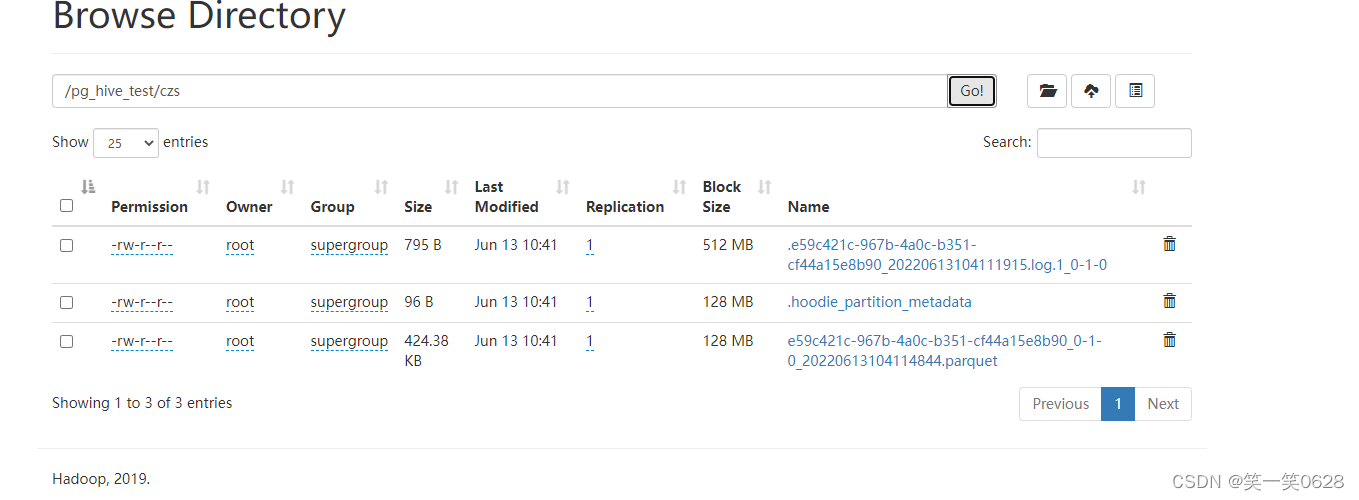
基于FlinkCDC采集PostgreSQL写入Hudi
设置PG的日志级别
修改wal_level = logical,重启数据库,使配置生效
vim /var/lib/pgsql/14/data/postgresql.conf

添加FlinkCDC依赖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZCRhYlPA-1655088688110)(../AppData/Roaming/Typora/typora-user-images/image-20220613104822842.png)]](https://img-blog.csdnimg.cn/e45646502ac6402ca18cf4bd9ef19ba9.png)
添加Hadoop依赖
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
创建MERGE_ON_READ类型的Hudi表
set execution.checkpointing.interval=3sec;
set sql-client.execution.result-mode=tableau;
CREATE TABLE pg_source(
id INT,
username STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'bigdata',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'mydb',
'schema-name' = 'public',
'decoding.plugin.name' = 'pgoutput',
'table-name' = 'test'
);
CREATE TABLE pg_hudi_hive(
id bigint ,
name string,
primary key(id) not enforced
)
PARTITIONED BY (name)
with(
'connector'='hudi',
'path'= 'hdfs://bigdata:8020/pg_hive_test',
'table.type'= 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'name',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://bigdata:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://bigdata:10000',
'hive_sync.table'= 'hudi_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= 'root',
'hive_sync.support_timestamp'= 'true'
);
INSERT INTO pg_hudi_hive SELECT id,username FROM pg_source ;