每天给你送来NLP技术干货!
来自:AI有温度
大家好,我是泰哥。本篇文章从什么是命名实体讲到为什么要做命名实体,然后讲到了NER数据处理及建模经验,对于做NER的同学,不论你是新手还是老手都非常值得一看!
1 什么是NER
1.1 什么是实体
根据百度百科定义,实体是指客观存在、并可相互区别的事物。实体可以是具体的人、事、物,也可以是概念。
1.2 什么是命名实体
命名实体就是以名称为标识的实体。简单来说,若我们听到一个名字,就能知道这个东西是哪一个具体的事物,那么这个事物就是命名实体。比如我有一只蟋蟀,名叫「小强」,那么「小强」就是一个命名实体。
命名实体有其实体类型,而实体类型是根据需求,人为定义的一种概念。常见的实体类型有人名、地名(有时又分为:地理地名和政治地名两部分)、组织名、时间、产品名等等。
在生活和生产中,到处有实体。下表中的示例是我们在生产和生活中经常遇到的命名实体和其实体类型。
| 序号 | 实体类型 | 实体 |
|---|---|---|
| 1 | 时间 | 1949年10月1日 |
| 2 | 地名 | 中国 |
| 3 | 地名 | 北京 |
| 4 | 节日 | 国庆节 |
| 5 | 人名 | 毛泽东 |
| 6 | 组织机构 | 中国共产党 |
| 7 | 数字 | 百分之百 |
1.3 为什么要识别命名实体
命名实体是现实世界里的事物,它们和现实世界相互作用、相互影响,因此命名实体在一些一些场景里特别重要。
比如,我想知道《红楼梦》里所有的人物在各回的出场情况,进而为每个人物做一个生平简介。这时候,我们就需要某种手段,把文本中的命名实体给识别出来,如下表:
| 回序号 | 文本内容 | 人名实体 |
|---|---|---|
| 5 | 宝玉还欲看时,那仙姑知他天分高明,「性」情颖慧,恐把天际泄漏,遂掩了卷册,笑向宝玉道:“且随我去游顽奇景,何必在此打折闷葫芦。“宝玉恍恍惚惚,不觉弃了卷册,又碎了警幻来至后 | 宝玉、警幻 |
1.4 海量文本数据中的命名实体
给我一周的时间,我能把《红楼梦》里面的人名全都标记出来。咬咬牙,把地名、组织名、职位名都标记出来,也是可以的。
什么?还有明代四大奇书以及《四库全书》?我需要亲切问候一下提需求的人。
1.5 什么是命名实体标注
壮士且慢,有没有听过命名实体识别,也就是NER呢?NER指的是一类技术,可以自动地从文本数据中识别出特定类型的命名实体。我们可用计算机来完成这个任务,用不了一周。
下图是命名实体标注任务的流程图。我们将原始文本输入到NER工具里,该工具会输出带有命名实体标记的文本或者命名实体列表。
 那么,具体是怎么做的呢?
那么,具体是怎么做的呢?
1.6 标签体系的种类与NER的输出
NER工具会给文本序列中的每一个字(或词)打上一个标签,用来表示这个字(或词)是否为命名实体的一部分。
下表是常见的NER标签体系:
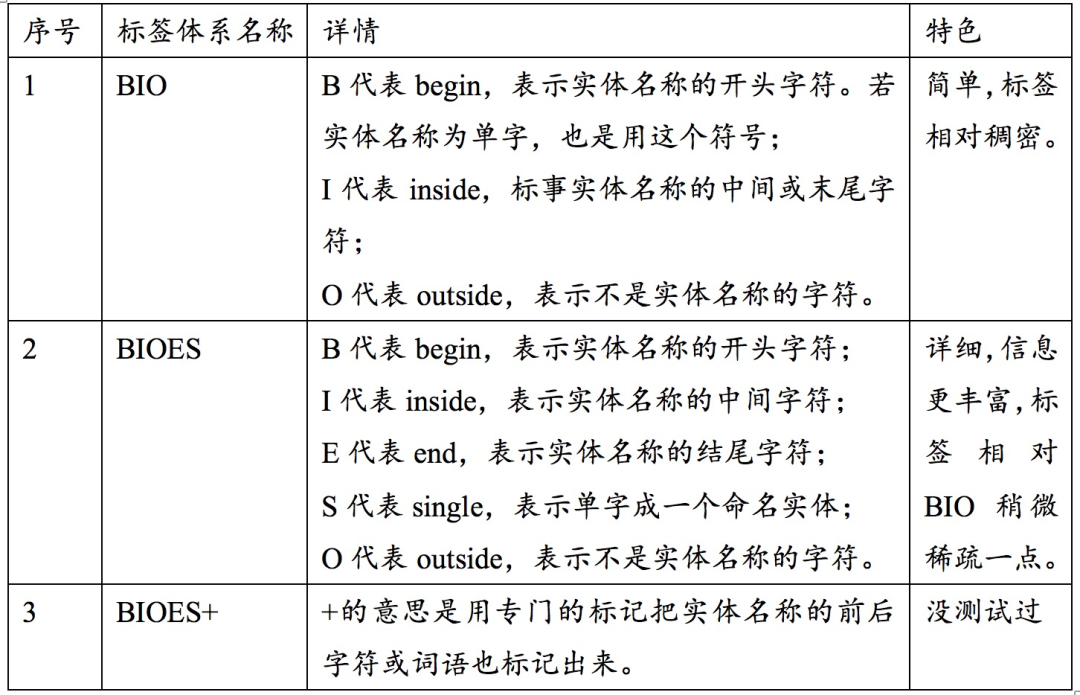 下表则展示了NER工具的输出结果。以前人们在做NER的时候,通常是先分词,然后基于词语序列来计算标签;最近几年大家发现不分词、直接基于字符序列的效果甚至更好。后者逐渐占据了比较大的话语权,因此这里默认是基于字序列来做NER。
下表则展示了NER工具的输出结果。以前人们在做NER的时候,通常是先分词,然后基于词语序列来计算标签;最近几年大家发现不分词、直接基于字符序列的效果甚至更好。后者逐渐占据了比较大的话语权,因此这里默认是基于字序列来做NER。

那么NER工具是如何计算出这些标签的呢?
2 如何识别命名实体
2.1 人工标注
命名实体是人定义的,人当然可以胜任这个工作。但是,如同前面所说,有几个限制因素导致不能依靠人工来做NER:
-
做事情需要人、财、物,而人力资源是其中最金贵的,耗费比较大;
-
我们在标注数据的时候,会面临体力下降、情绪波动等等生理和心理状况的考验,导致不能长时间、高质量地进行数据标注;
-
我们处理数据的速度太慢了,这是最要命的。举个例子,我标注微博文本的情感极性时,一天上千条就烦的不行——生产力太弱。
如果数据量比较小,使用真正的“人工智能”是可以的;但是,当数据量比较大的时候,我们需要机器的帮助。我们一般用人工标注一个足够大的高质量训练数据,然后基于这个训练数据训练好模型,再利用训练好的模型来做大规模的NER。
2.2 使用规则
规则是最符合我们直觉的一种算法,任何需要自动化的地方,我们都会尝试用规则来解决问题,NER也不例外。在人工智能发展的初期,人们认为语言规律是可以用规则来描述的,比如“xxx公司”是一个公司名。
一般来说,我们在做命名实体的时候,可以首先考虑可否使用正则。如果命名实体的名称规律比较简单,我们可以找出模式,然后设计相应的正则表达式或者规则,然后把符合模式的字符串匹配出来,作为命名实体识别的结果。
比如我需要识别下图所示文本里的政府机构。这里的机构名称规律比较简单,是“[地名][职能][行政级别]”这样的三元组(然后去掉地名,就是我们要的部门名称了)。符合这个模式的,“基本上”就是一个政府机构。为什么说是“基本上”,因为我只看了很少的数据,总结的模式还很少。
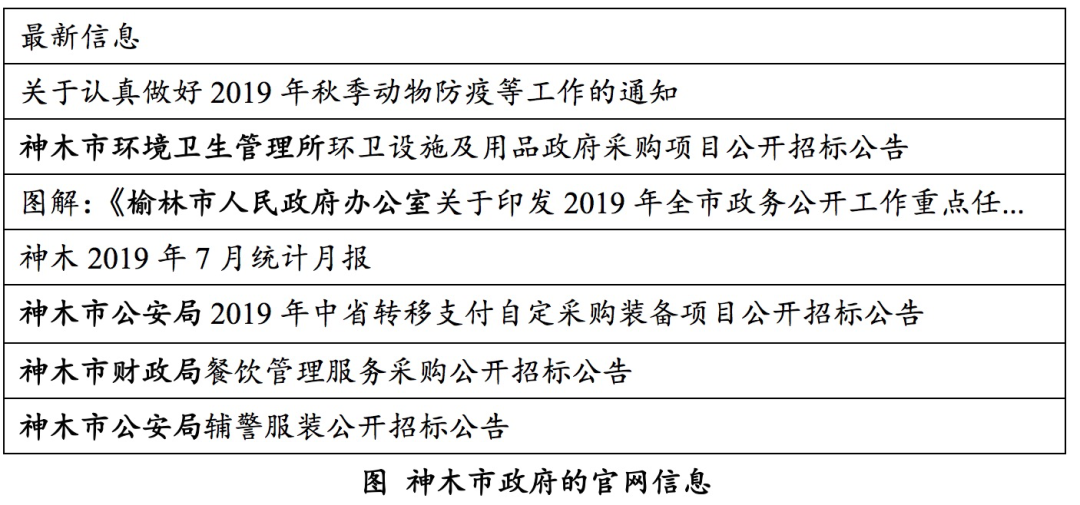
2.3 基于词典
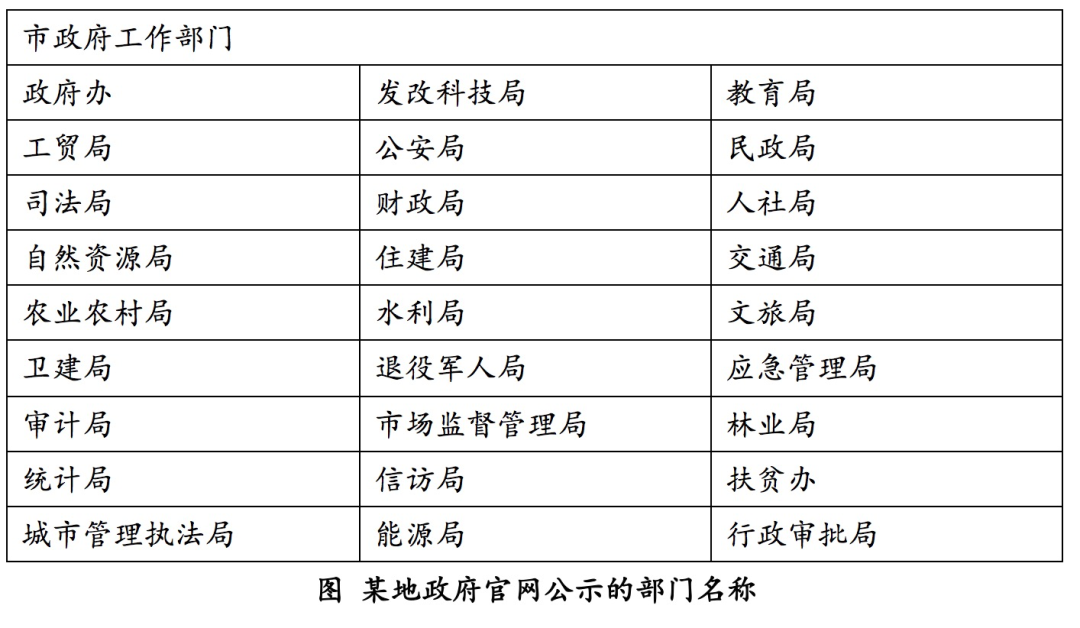
在仔细查看这个官网的时候,我发现相关部门还是比较负责的,把组织机构框架也公示了出来。这样,我就可以获得一个部门名称词典。
词典是一种非常有价值的数据。在命名实体识别任务中,我们可以把部门名称当做一个模式,直接去文本里匹配——如果一个部门名称出现在文本里,说明文本包含了这个名称。
这样做会遇到比较严重的问题:歧义。比如「我国的自然资源局部集中现象很普遍」这句话里的「自然资源局」是一个部门名称吗?显然不是。
我们可以用分词的方法来减少歧义带来的困扰。比如,可以先将句子切分为「我/国/的/自然/资源/局部/集中/现象/很/普遍」,然后再逐词匹配。当然,这要求分词算法比较给力。
那要是遇到「我是自然资源局的」,分词结果是「我/是/自然/资源/局/的」,这可怎么办呢?「自然资源局」被切分成若干个词语了。这时候可以使用最大匹配法,检查分词结果中是否在这样的一些子串,可以组成部门名称。
实际上现在比较流行的分词工具(HanLP、Jieba、IK等),默认用的都是最短路径分词这类算法,支持用户添加自定义词典、使特定字符串优先成词。这样,我们把部门名称添加的词典里,「自然资源局」就不会被切分开了。
2.4 模型
后来,由于无法解决语言相关的问题,基于规则的“人工智能”系统退出了C位,取而代之的是统计和机器学习。
2.4.1 分类器
在一些人的眼中,万物皆可分类。NER也可以看做一种分类任务,就是判断一个词语是不是命名实体、是哪一种命名实体。常见的做法就是,基于一个词语或者字的上下文构造特征,来判断这个词语或者字是否为命名实体。
这个方法需要比较好的特征工程,也就是要求我们对文本和业务内容有很深的理解,门槛还是比较高的。
2.4.2 HMM和CRF
NER 也可以用序列标注的方式来做。命名实体存在于自然语言中,而自然语言是“人”这个模型在接收外界信号后生成的一种序列,因此有人认为语言符合某种模型。
常见的一种假设是,序列元素具有一种隐藏(不可见)的状态——模型以一种概率分布随机生成隐藏状态,然后基于隐藏状态的取值选择一种概率分布去生成序列。在NER中,词语的标签就是不可见(因此需要推测)的状态。
我们可以罗列出所有可能的文字序列或者词语序列的NER标签序列,然后用HMM和CRF评估各个标签序列的质量、择优录取(实际不需要这么暴力,人们为这两个模型提供了缩小搜索空间的算法)。
这两个模型的优点是,使用了文本序列的整体信息,可以找到“最合适的”标注方案。因此,即使深度学习来势汹汹,CRF也没有被淘汰。
2.4.3 深度学习
深度学习领域的模型结构种类比较多,最适合做自然语言处理任务的是RNN类和tansformer类。这些神经网络也把语言看做是序列数据,然后用自身极强的拟合能力,把这种序列转换为标签序列。
如果只使用神经网络,我们会用softmax来作为输出层,本质上是对序列元素的分类。这种做法比较自然,不过有一个不足:它认为序列元素之间的相互独立的,损失了不少信息。
还有一种做法,就是以CRF作为输出层,把任务变成序列标注,这样就可以使用上序列元素之间的关系信息了。这个方案结合了神经网络的拟合能力和CRF的全局视野,是非常经典、有效的一种NER模型结构。
当然了,去年开始大家开始关注的transformer做NER更是一把好手。我们可以把transformmer和CRF结合起来。是的,特征提取器总是在变,而CRF一直在顶端。
3 关于积累语料
3.1 为什么要积累语料
作为一个合格的算法工程师,平时要有积累的习惯。不光积累算法,还要积累数据。
为什么呢?再牛叉的模型,没有数据也是白瞎。大部分模型需要质量较好、规模较大的数据作为饲料,一点点训练成型。没有数据,模型就是”人工智障”。因此,数据科学相关的任务里,数据尤其是有标签数据经常是最重要的资源。
通常来说,我们做产品或者项目的时候,会采集、购买或者自己标注一定量的数据用来建模。比如我们要从文本里抽取饭店的名字,就需要构造一份给饭店名字打了标记的文本语料——这份数据用完了,可要保存好了啊。
为什么要保存呢?产品需要迭代,项目可能有二期,你和你的徒弟没准需要学习,饭店名称数据还可以用来做词表……你确定十年之内用不到这份数据吗?如果不确定,那就还是把它管理好。
3.2 如何积累语料
3.2.1 寻找开源数据
百度和谷歌直接搜,可以找到很多NER的资源。顺便还能找到问答等任务的数据。
Github里的兄弟姐妹们是共产主义的先锋,经常会把代码和数据一块分享出来,我们需要更多这样的人。
知乎里有很多NLP方面的爱好者,乐于分享自己了解的内容和数据。如果搜索一下,知乎也能提供相关的数据集信息。
3.2.2 买数据
买数据是一种短平快的积累手段,但是贵啊。当然了,公司有实力,有需要就会买。这时候就可以愉快地开始建模了。
3.2.3 自己动手
NER语料标注需要一个趁手的工具才能保证效率。之前调研过一个开源的,叫做rasa-nlu-trainer,无需安装,并且可以同时对数据进行实体标注和文本分类标注。我之前做过分享,感兴趣的同学可以看:
4 数据预处理的一点经验
4.1 标签体系规范化
目前允许开放获取的 NER 语料,使用的标签体系不是统一的,有的是BIO,有的是BIOES,有的采用了类似词性标注的标记方式。因此需要做细致的标签体系规范化工作。
比如《人民日报》的语料,虽然是一个词性标注语料,但是里面的若干词性实际上就是命名实体,我们可以基于词性和实体类型的映射、完成转换。该语料存在大量合成词作为命名实体的情况,以及命名实体嵌套的情况,都需要根据需求做专门的处理。
4.2 去重
我找了一堆开放获取的数据,而大家也通常是从其他渠道找到的这些数据,里面不可避免的有一些重复的情况。如果你的数据里存在重复,意味着测试集里很有可能混杂了训练集里的样本——测试得到的各项指标会虚高。这会导致模型上线的时候,实际效果比预想的差很多,而我们还很难找出原因、只能挠头。
一定要做好去重工作,以句为单位对语料进行排重。我们可以将句子切分成ngram,然后用余弦相似度或者杰卡德相似度,判断两个句子是否相似。由于句子数量较多,可以使用一个以ngram为key、句子列表为value的 倒排索引来辅助减少计算量。
4.3 数据扩增
4.3.1 文本数据扩增的困难
做 CV 的同志们真是幸福。我们可以用规则、基于几十张图片,生成上万张图片,让模型好好学习。我能理解的原因主要有2个:
-
图像是对真实世界的一种比较直接的描述方式,信息的损失量比较小的同时,人可以基于自己的视觉经验对图像做各种各样的变换
-
图像数据具有比较强的空间相关性,我们施加的变换不会完全破坏这种相关性,比如“大黄”变成“大蓝”,它还是一条狗。
做 NLP 的同志们就稍微惨一些:
-
语言是人类用人造的离散符号,对世界的一种描述,信息量损失很大
-
一般来说,语言只有一个维度上存在相关性,而这种相关性比较纠结、是语法上的相关(破坏句子结构的变换一般人接受不了)。这导致我们可以对文本数据施加的变换,比较少。常见的方法有几个: 同义词替换、回译、随机增删词语。
4.3.2 同义词替换
语言学家对同义词的定义是:用A词语替换句子中的B词语,句子的语义和句法结构不发生改变,那么A和B就是同义词。因此,我们可以收集一个命名实体之间的同义关系数据,然后做各种替换,就可以得到一些新的数据。
另外,通常来说,相同类型的实体名称在句子结构中的作用是一样的。比如「我今天要去天安门看升国旗」,改为「我今天要去黄山看升国旗」,句子仍然是合法的,只是语义有所变化(有时候还会出现不合常理的句子)。用这种方式,我们也可以得到一些新数据。
4.3.3 回译
最近几年机器翻译做的越来越好了,有人想到另一种扩增语料的办法:先把中文翻译成英文,然后再把英文翻译回中文,这样也可以得到新的语料。比如说「我要去北京,吃那里的烤鸭」,会被翻译成「I’m going to Beijing to eat roast duck」,然后回译为「我要去北京吃烤鸭」。
4.3.4 随机增删字词
我们说话或者写作的时候,经常会出错。比如我打字的时候会打出错别字而没有检查出来,写了一句「我腰去北京,吃那里的烤鸭」。我们需要NER模型对这些错误有一定的鲁棒性,可以在文本有噪声的情况下,可以正确判断句子里的实体。
这时候,我们可以从训练集中,随机抽取出来一些句子,对里面的字词进行随机增删改,然后把这样的错误样本添加到训练集中。是的,就是加一点噪声。
5 建模的一点经验
5.1 如何选择算法或者模型
如果有业务场景对应的词表,直接上“分词+词典匹配”的方案即可;如果有一定量的标注数据,可以用CRF;如果有钱有人、标注数据量比较大,那就试一下深度学习。
5.2 模型效果的评价
NER任务的目标,通常是“尽量发现所有的命名实体,发现的命名实体要尽量纯净”,也就是要求recall(查全率)和precision(查准率)比较高。当然,场景也有可能要求其中一项要非常高。
需要注意的是,这里统计recall和precision的时候,对象是命名实体,而不是单个标签。
 以上图所示为例,我们把「北京」预测成了“SS”,「北」和「京」是两个命名实体,这是错误的;「天安门」和「毛」的标签是正确的。因此,这句话中,模型的召回率是:
以上图所示为例,我们把「北京」预测成了“SS”,「北」和「京」是两个命名实体,这是错误的;「天安门」和「毛」的标签是正确的。因此,这句话中,模型的召回率是:
天安门、毛北、京、天安门、毛
5.3 如何判定模型结构有效
用全量训练数据之前,一定要先用一份较小的数据(比如测试数据),训练模型,看一下模型会不会过拟合,甚至记住所有的样本。如果模型没有过拟合,说明参数不能收敛,也就是模型无法从数据中学习到东西。这时候我们需要检查一下模型结构和数据,看看到底是哪里出了问题。
开始用全量数据后,我们还会遇到各种各样的问题,这里列几个常见的症状和原因,如下图所示:
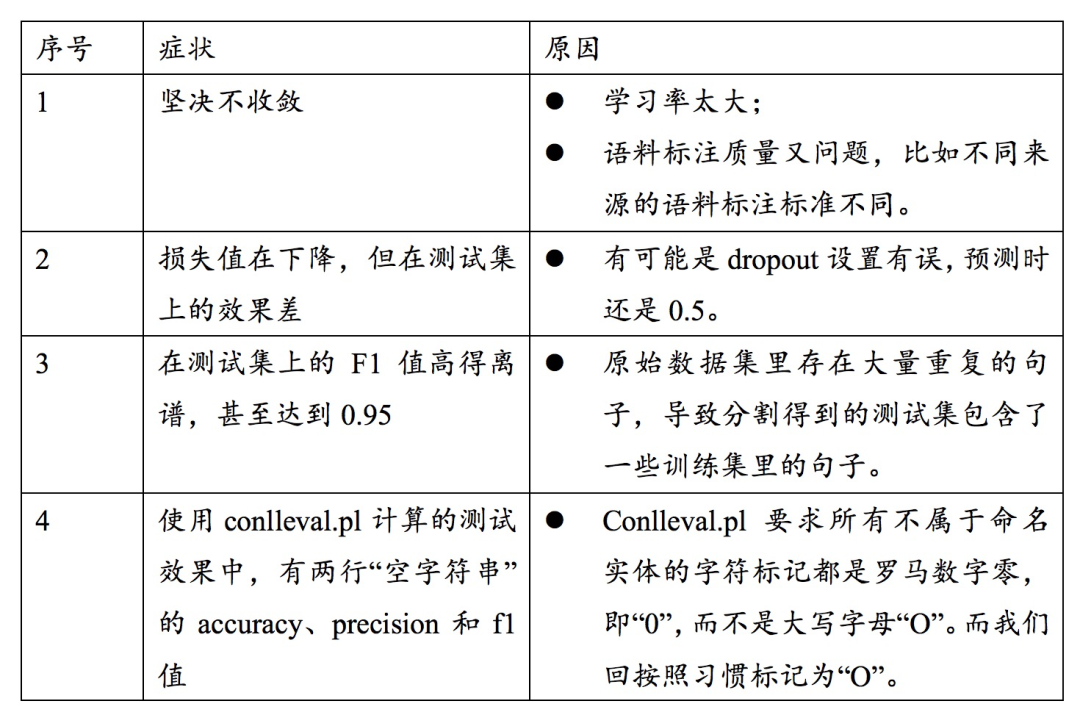
6 结束语
做NER的过程中,比较消耗精力的环节是数据采集和预处理。采集数据需要耐心地持续进行;而数据预处理需要细心,并根据bad case不断纠错。在这个过程中,倒排索引、栈、字符串、递归等数据结构和算法,对工作的帮助很大。
另外,在学习NER相关内容的过程中,我开始看语言学和计算语言学的相关内容,也意识到语言学的理论和方法对工程师来说,是非常有助益的。
比如,许嘉璐和傅永和主编的《中文信息处理:现代汉语词汇研究》,里面的内容比较深、使用的方法比较简单,可以作为科普读物、挑着看。这些学者的工作还是挺扎实的,对NLP的发展推动很大。Frederick Jelinek说的“每当我开除一个语言学家,语音识别系统就更准了”,我觉得是带有偏见的玩笑话,不足为训。
来源:https://zhuanlan.zhihu.com/p/84566617
作者:李鹏宇
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
ACL’22 | 快手+中科院提出一种数据增强方法:Text Smoothing
阿里+中科院提出:将角度margin引入到对比学习目标函数中并建模句子间不同相似程度
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!