1、exist 和 in选择
这里没有考虑索引,只看效率:
如果主查询的数据集大,则使用In , 效率高。
如果子查询的数据集大,则使用exist, 效率高。
select ..from table where exist (子查询);-- 括号内是子查询
select ..from table where 字段 in (子查询);
exist语法: 将主查询的结果,放到子查询结果中进行条件校验(看子查询是否有数据,如果有数据 则校验成功)
如果 复合校验,则保留数据;
-- 等价于select tname from teacher
select tname from teacher where exists (select * from teacher) ;
select tname from teacher where exists (select * from teacher where tid =9999) ;
in语法:
select …from table where tid in (1,3,5) ;
select * from A where id in(select id form B);
2、order by 优化
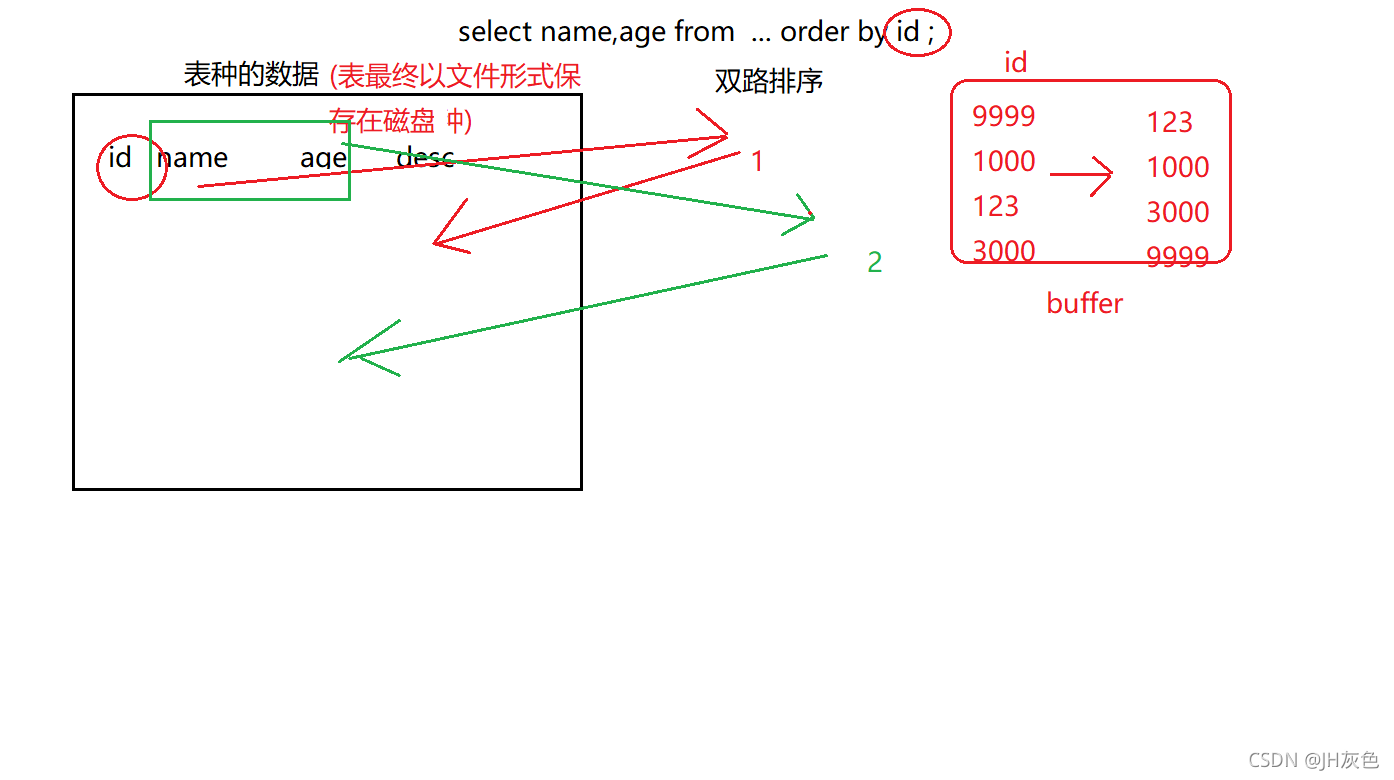
using filesort 有两种算法:双路排序、单路排序 (根据IO的次数)
MySQL4.1之前默认使用双路排序;
双路:扫描2次磁盘(IO):select name,age from ..order by id Mysql数据库是存储在磁盘(永久存储)
1:从磁盘读取排序字段 ,对排序字段进行排序(扫描排序字段后,对其进行排序,在buffer中进行的排序):id是排序字段
2:扫描其他字段 : name,age
MySQL4.1之后 默认使用 单路排序 :(双路排序IO较消耗性能)
只读取一次(全部字段),在buffer中进行排序。
但种单路排序 会有一定的隐患 (不一定真的是“单路|1次IO”,有可能多次IO)。
原因:如果数据量特别大,则无法 将所有字段的数据 一次性读取完毕,因此 会进行“分片读取、多次读取”。
注意:单路排序 比双路排序 会占用更多的buffer。
单路排序在使用时,如果数据大,可以考虑调大buffer的容量大小:设置buffer容量
set max_length_for_sort_data = 1024 单位byte
如果max_length_for_sort_data值太低,则mysql会自动从 单路->双路
(太低:需要排序的列的总大小超过了max_length_for_sort_data定义的字节数)
**提高order by查询的策略:**优化
a.选择使用单路、双路 ;调整buffer的容量大小;
b.避免select * … ,因为*不会索引覆盖,性能就会降低
c.复合索引 不要跨列使用 ,避免using filesort
d.保证全部的排序字段 排序的一致性(都是升序 或 降序)
版权声明:本文为JH39456194原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。