概述
不管是学习什么编程语言,一般入门的实战程序一般都是从Hello World开始的。这一节,我们就用Hello World程序进行Cuda实战,程序的内容主要是让CPU和GPU分别打印Hello World,在CPU中打印内容为Hello World From CPU!,在GPU中打印内容为Hello World From GPU!,具体实现请参考程序案例。
程序
//C语言标准库
#include <stdio.h>
//Cuda运行库
#include <cuda_runtime.h>
//核函数,GPU中运行:在GPU中打印Hello World
__global__ void mykernel(void) {
//GPU打印Hello World
printf("Hello World From GPU!\n");
}
//主函数,CPU中运行,修饰符__host__可以省略不写
int main(void) {
//CPU打印Hello World
printf("Hello World From CPU!\n");
//调用核函数,启用GPU执行打印任务
mykernel << <2, 2 >> > ();
//同步函数,作用为:强制CPU等待GPU执行完才执行
cudaDeviceSynchronize();
return 0;
}
补充
mykernel << <2, 2 >> > ();
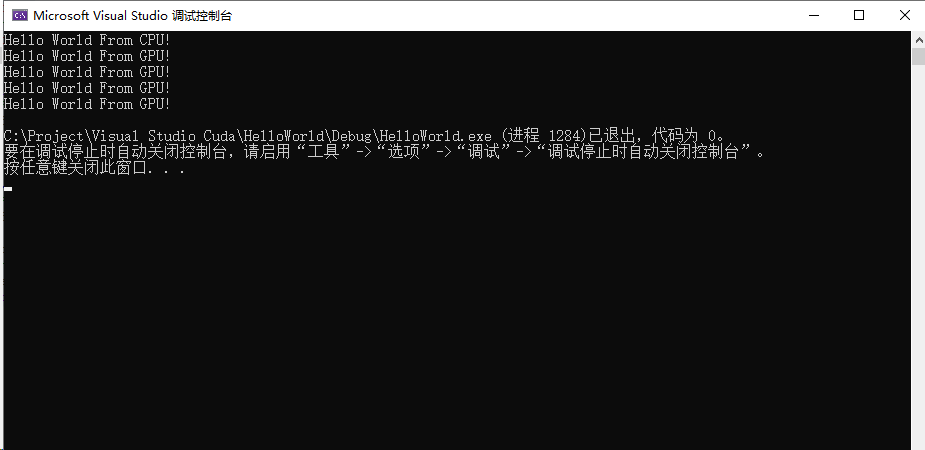
原型为mykernel << <block, thread>> > (),第一个参数为格中块结构,第二个参数为块中线结构。在这里代表启动了一个网格,网格里面有2个线程块,每个线程块有2个线程,整个网格有4个线程,所以结果应该打印出4个Hello World。
cudaDeviceSynchronize();
一般情况下CPU调用核函数kernel后,就不会管GPU是否执行完毕,立即执行下一条语句。当调用这个同步语句后,它会阻塞CPU执行,直到GPU执行完毕后才会执行下一条语句。如果把这一条语句注释掉,那么控制台输出里面就看不到GPU部分打印的Hello World了。
输出
版权声明:本文为weixin_45792450原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。