# df.GroupBy(“某列”)的作用:
排序后返回的是:将一个表分为很多个tuple(其数量等于原来的行数),tuple列按照从小到大的顺序排列,tuple[0]表示该行中索引列(GroupBy列)对应的值,tuple[1]表示原来DF中的某一行,且性质还是为DataFrame,这边意味着还可以继续对它做DF相关操作(比如继续GroupBy)。
先看看大佬的详细解释:(讲解得很仔细的)
https://zhuanlan.zhihu.com/p/101284491
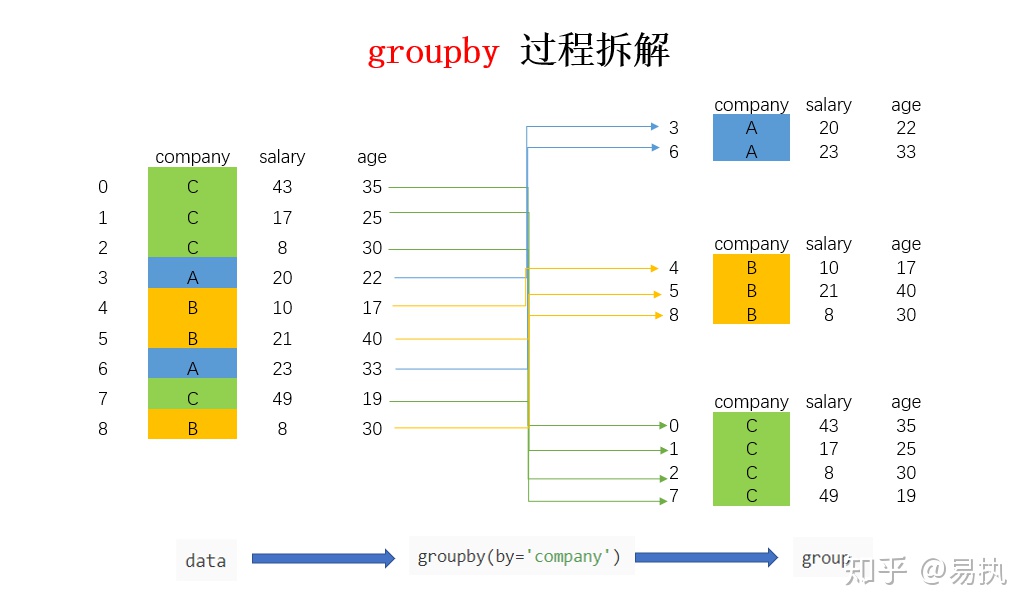
我补充一点东西,就是GroupBy()函数的具体使用:
import numpy as np
from pandas import DataFrame
import pandas as pd
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df)Result:

建议体验一下下面的操作:
for dfGroupBy in df.groupby("C"):
print(dfGroupBy)
print(dfGroupBy[0])
print(type(dfGroupBy))
print(dfGroupBy[1])
print(type(dfGroupBy[1]))
# print(dfGroupBy)
break
#建议自己改改里面的参数,看看输出,然后仔细读读第一段的话Result:

建议自己多试试,看不如做
版权声明:本文为weixin_44585583原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。