文章目录
一,栈的定义
栈是限定仅在表尾进行插入和删除操作的线性表
允许插入和删除的一端称为栈顶,另一端称为栈底。不含任何数据元素的栈称为空栈。栈又称为后进先出的线性表,简称LIFO结构。
注意:
- 栈元素具有线性关系,即前驱后继关系
- 可在线性表的表尾进行插入和删除操作,这里的表尾指的是栈顶
- 栈底是固定的,最先进栈的只能在栈底
- 栈的插入操作,叫做进栈,也称压栈,入栈
- 栈的删除操作,叫做出栈,有的也叫弹栈
二,顺序栈
栈的顺序存储结构
栈是线性表的特例,栈的顺序存储是线性表顺序存储的简化,简称顺序栈
注意:
- 线性表是用数组来实现的
- 下标为
0的一端作为栈底比较好 - 定义一个
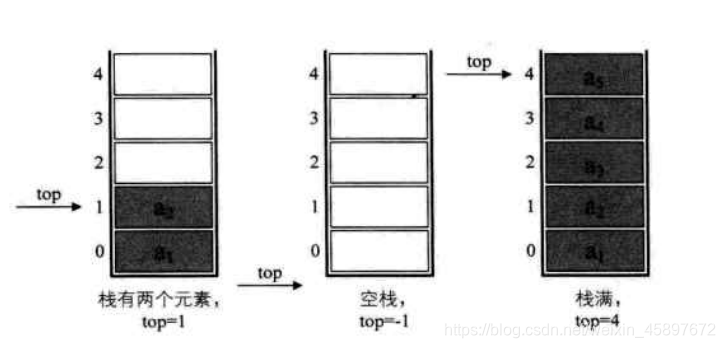
top变量来指示栈顶元素在数组中的位置,当栈存在一个元素时,top等于0, 空栈的判定条件为top = -1 - 若一个栈的长度为 5,则栈的普通情况,空栈和栈满的情况如下图所示:
顺序栈的结构定义
//顺序栈的定义
typedef struct{
Selem *base; //栈底指针
Selem *top; //栈顶指针
int Size; //栈的长度 ,栈可用的最大容量
}Haha;
new的用法
new的作用是从自由存储为类的对象或对象数组分配内存,并将已适当分类的非零指针返回到对象。
比如:char * pchar= new char[10];
delete pchar;
例子中动态分配了10个char类型的内存给了pchar,来构成一个数组。需要注意的是,分配数组采用[ ],如果只是单个的只要new char就可以了。
- 注意事项:
(1)使用delete运算符可解除分配使用new运算符分配的内存。而且new和delete是成对出现的。只出现一个是错误的或不规范的写法,即使能编译通过,也会有安全隐患,可能会造成内存泄露;
(2)使用的new与delete要相同。也就是说如果你在new表达式中使用了 [ ],你必须在对应的delete表达式中使用 [ ]。
(3)使用new为C++类对象分配内存时,将在分配内存后调用对象的构造函数。所以如果是自己写的类的话,最好自己写个构造函数,这样会比较好。
指针
指针是一种特殊类型的变量,用于存储值的地址
- 指针是一个变量,其存储的是值的地址,而不是值本身
- 如果
home是一个变量,则&home是它的地址 - 假设 m 是一个指针,则 m 表示的是一个地址,
*m表示存储在该地址的值 &运算符来获得地址*运算符来获得值
进栈操作
(建议结合下面代码理解)
//顺序栈的进栈,插入元素 e作为新的栈顶元素
int Push(Haha &S,Selem e){
if(S.top - S.base == S.Size) //栈满
return 0; //不可再添加新的数据元素
*(S.top ++) = e; //将元素 e 压入栈顶,栈顶指针加一
return 1; //进栈成功
}
出栈操作
时间复杂度为O(1)
//顺序栈的出栈,删除栈顶元素,返回其值
char Pop(Haha &S){
char e;
if(S.base == S.top) //栈空
return 0;
e = *(--S.top); //栈顶指针减一,同时将栈顶元素赋值给e
return e;
}
整体代码如下:
#include <iostream>
using namespace std;
#define MAX 10 //顺序栈存储空间的初始分配量
typedef int Sta; //typedef意思相当于 type define
typedef char Selem;
//顺序栈的定义
typedef struct{
Selem *base; //栈底指针
Selem *top; //栈顶指针
int Size; //栈的长度 ,栈可用的最大容量
}Haha;
//顺序栈的初始化,构造一个空栈 S
int Init(Haha &S){
S.base = new Selem[MAX]; //为顺序栈动态分配一个最大容量为 MAX的数组空间
//基地址指针
if(!S.base) //存储分配失败
exit(-2); //直接结束进程
S.top = S.base; //栈顶指针初始为 base
//栈顶指针与栈底指针指向同一个位置(因为是空栈)
S.Size = MAX; //栈的最大容量
return 1; //初始化成功
}
//顺序栈的进栈,插入元素 e作为新的栈顶元素
int Push(Haha &S,Selem e){
if(S.top - S.base == S.Size) //栈满
return 0; //不可再添加新的数据元素
*(S.top ++) = e; //将元素 e 压入栈顶,栈顶指针加一
return 1; //进栈成功
}
//顺序栈的出栈,删除栈顶元素,返回其值
char Pop(Haha &S){
char e;
if(S.base == S.top) //栈空
return 0;
e = *(--S.top); //栈顶指针减一,同时将栈顶元素赋值给e
return e;
}
//返回栈顶元素的值,不修改栈顶指针
char Get(Haha &S){
if(S.top != S.base) //栈非空
return *(S.top - 1); //返回栈顶元素的值,栈顶指针不变
}
int main(){
Haha s; //定义一个栈
int choose, flag = 0, q = 0;
Selem j;
choose = -1;
while(choose != 0){ //本代码可以实现 4 个数据元素的进栈,出栈操作
//遇到实际问题更改一下for循环中的值即可
cin >> choose;
switch(choose){
case 1:{ //顺序栈的初始化
if(Init(s)){
flag = 1;
cout << "初始化栈成功\n";
}
else
cout << "初始化栈失败\n";
break;
}
case 2:{ //进栈
for(int i = 0; i < 4; i++){
cin >> j;
Push(s,j);
q ++;
}
if(q == 4) cout << "进栈成功" << endl;
break;
}
case 3:{ //输出栈顶元素
if(flag != -1 && flag != 0)
cout << Get(s) << endl;
else
cout << "栈中无元素" << endl;
break;
}
case 4:{ //出栈
for(int i = 0; i < 4; i ++){
flag = -1;
cout << Pop(s) << " ";
}
cout << endl;
break;
}
}
}
return 0;
}
运行结果:

三,链栈
栈的链式存储结构
栈的链式存储结构,简称为链栈
- 栈顶放在单链表的头部较好
- 链栈不需要头结点
- 链栈的空为
top = NULL - 对于链栈来说,基本不存在栈满的情况
链栈的结构定义
//链栈结构定义
typedef struct Haha{
char data;
struct Haha *next;
}Haha, *linkst;
进栈操作
//链栈的进栈
int Push(linkst &S, char e){ //在栈顶插入元素 e
linkst p; //定义一个新的结点
p = new Haha; //生成一个新结点
p->data = e; //将新结点的数据域置为 e
p->next = S; //将新结点插入栈顶
S = p; //将栈顶指针改为 p
return 1;
}
出栈操作
//链栈的出栈
char Pop(linkst &S){ //删除 S的栈顶元素,用 e返回其值
char e;
linkst p; //定义一个结点
if(S == NULL) //如果栈空
return 0;
e = S->data; //将栈顶元素赋值给 e
p = S; //用 p 临时保存栈顶元素空间,以便释放
S = S->next; //修改栈顶指针
delete p; //释放原栈顶元素的空间
return e; //返回出栈的数据元素值
}
整体代码如下:
#include <iostream>
using namespace std;
//链栈结构定义
typedef struct Haha{
char data;
struct Haha *next;
}Haha, *linkst;
//链栈的初始化
int Init(linkst &S){ //构造一个空栈 S,栈顶指针指向空
S = NULL; //动态栈,不需要定义长度
return 1;
}
//链栈的进栈
int Push(linkst &S, char e){ //在栈顶插入元素 e
linkst p; //定义一个新的结点
p = new Haha; //生成一个新结点
p->data = e; //将新结点的数据域置为 e
p->next = S; //将新结点插入栈顶
S = p; //将栈顶指针改为 p
return 1;
}
//链栈的出栈
char Pop(linkst &S){ //删除 S的栈顶元素,用 e返回其值
char e;
linkst p; //定义一个结点
if(S == NULL) //如果栈空
return 0;
e = S->data; //将栈顶元素赋值给 e
p = S; //用 p 临时保存栈顶元素空间,以便释放
S = S->next; //修改栈顶指针
delete p; //释放原栈顶元素的空间
return e; //返回出栈的数据元素值
}
//取链栈的栈顶元素
char Get(linkst S){ //返回 S的栈顶元素,不修改栈顶指针
if(S != NULL)
return S->data;
}
int main(){
linkst s;
int choose, flag = 0, q = 0;
char j, t;
choose = -1;
while(choose != 0){
cin >> choose;
switch(choose){
case 1:{ //链栈的初始化
if(Init(s)){
flag = 1;
cout << "初始化栈成功\n";
}
else
cout << "初始化栈失败\n";
break;
}
case 2:{ // 链栈的进栈
for(int i = 0; i < 4; i++){
cin >> j;
Push(s,j);
q ++;
}
if(q == 4) cout << "进栈成功" << endl;
break;
}
case 3:{ //输出栈顶元素
if(flag != -1 && flag != 0)
cout << Get(s) << endl;
else
cout << "栈中无元素" << endl;
break;
}
case 4:{ //出栈
for(int i = 0; i < 4; i ++){
flag = -1;
cout << Pop(s) << " ";
}
cout << endl;
break;
}
}
}
return 0;
}
运行结果如下:

四,顺序栈与链栈的区别
对于顺序栈
- 需要事先确定一个固定一个长度
- 可能存在内存空间浪费的问题
- 存取时定位很方便
对于链栈
- 每个元素都有指针域
- 同时增加了内存开销
- 对于栈的长度无限制
如果栈的使用过程中元素变化不可预料,最好是用链栈,
如果栈的变化在可控范围内,建议使用顺序栈。
版权声明:本文为weixin_45897672原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。