虚拟机基础概念
- jvm:java虚拟机,一台虚拟的计算机,具有语言独立性和平台独立性,各种语言编写的程序,只要编译成java字节码,都可以运行在java虚拟机上,不用关心底层平台是window还是linux
- class文件:java字节码文件,程序编译之后生成的文件,jvm只认该文件
- 从编码到执行过程

- jvm规范:jvm由jvm规范描述,具体的实现由各个厂商(开发者)定义

- jvm、jre、jdk关系

class文件结构
由于class文件属于jvm的核心基础,涉及到很多方面,这里只是梳理class文件的关键骨架
概览
| 类型 | 项目 | 说明 |
|---|---|---|
| u4 | magic | 文件格式标志,固定为0xCAFEBABE |
| u2 | minor_version | 字节码文件次版本号 |
| u2 | major_version | 字节码文件主版本号 |
| u2 | constant_pool_count | 常量池的大小 |
| cp_info | constant_pool_count | 常量池 |
| u2 | access_flags | 访问修饰符,如public、private等 |
| u2 | this_class | class文件定义的类或接口,这里是对应常量池的索引 |
| u2 | super_class | 父类,对应常量池的索引 |
| u2 | interfaces_count | 接口数量 |
| u2 | interfaces[interfaces_count] | 接口数组,此处是常量池的索引 |
| u2 | fields_count | 字段数量 |
| field_info | fields[fields_count] | field_info类型数组 |
| u2 | methods_count | 方法数量 |
| method_info | methods[methods_count] | method_info类型数组 |
| u2 | attributes_count | 属性数量 |
| attribute_info | attributes[attributes_count] | attribute_info类型数组 |
- u1——无符号数1个字节
- u2——无符号数2个字节
- u4——无符号数4个字节
常量信息(cp_info)
| 类型 | 项目 | 说明 |
|---|---|---|
| u1 | tag | 常量类型,截止java se 16,常量类型有17类 |
| u1 | info[] | 该项的内容依据tag变化 |
字段信息(field_info)
| 类型 | 项目 | 说明 |
|---|---|---|
| u2 | access_flags | 访问修饰符 |
| u2 | name_index | 方法名,常量池索引 |
| u2 | descriptor_index | 方法描述,常量池索引 |
| u2 | attributes_count | 属性数量 |
| attribute_info | attributes[attributes_count] | 属性信息数组 |
方法信息(methods_info)
| 类型 | 项目 | 说明 |
|---|---|---|
| u2 | access_flags | 访问修饰符 |
| u2 | name_index | 方法名,常量池索引 |
| u2 | descriptor_index | 方法描述,常量池索引 |
| u2 | attributes_count | 属性数量 |
| attribute_info | attributes[attributes_count] | 属性信息数组 |
属性信息(attribute_info)
| 类型 | 项目 | 说明 |
|---|---|---|
| u2 | attribute_name_index | 属性名,常量池索引 |
| u4 | attribute_length | info数组长度 |
| u1 | info[attribute_length] | 属性信息数组 |
其中属性分为三大类:
- jvm虚拟机解释class文件类(6个)
- JAVA SE类库或工具解释class文件类(10个)
- class文件的元数据(metadata)(30个)
jvm指令
JVM指令(SE 16)目前分为9大类,具体每个指令的详细说明请参考JVM规范。
- Load And Store
- 算术运算指令
- 类型转换指令
- 对象创建和操作
- Operand Stack Management
- 控制转移(Control Transfer)
- 方法调用和返回
- 异常
- 同步
运行时内存结构

共享内存
- Heap——如果堆内存超出设置大小,将抛出OutOfMemoryError错误
- Method Area——逻辑上属于堆内存,具体位置由JVM实现确定,如果超出设置大小,将会抛出OutOfMemoryError错误
- Run-Time Constant Pool——如果超过设置大小,将抛出OutOfMemoryError错误
线程内存
- PC寄存器——正在执行的指令地址
- JVM Stacks大小是否可以设定或动态调整,依据JVM的具体实现,如果超出栈设置的大小,将会抛出StackOverflowError错误,如果可扩展,如无足够内存,将抛出OutOfMemoryError错误
- Frame——每个方法调用线程都会创建一个Frame,方法调用完成则销毁
- Dynamic Linking——运行时常量池的引用
- Frame——每个方法调用线程都会创建一个Frame,方法调用完成则销毁
- Native Method Stacks —— 每个线程创建一个本地方法栈,大小是否可以设定或动态调整,依据JVM的具体实现,如果超出栈设置的大小,将会抛出StackOverflowError错误,如果可扩展,如无足够的内存,将抛出OutOfMemoryError错误
总体来说,JVM运行时内存可分为静态信息和动态信息两部分,静态信息即为类(接口)的结构信息,动态信息即为类的实例数据和代码执行信息
对象的内存结构
对于对象的结构,jvm规范没有要求,这里主要介绍hotspot的对象内存结构
概览
普通对象

普通对象包括mark word,以及实例的类型信息class word和实例字段,mark word 和class word 称为对象头
数组对象

对于数组对象,除了mark word和class word外,还包括数组的长度以及数组元素
Mark Word
mark word在32位环境下位4个字节,64位环境下为8字节,32位环境下mark word不同状态下的结构信息如下:

64位环境下的mark word不同状态下的结构信息如下:

mark word主要包括三方面的信息:
- GC相关的信息
除了age记录对象经历了多少次GC外,还会把对象移动的信息编码进mark word - identity hash code
在使用系统的hashCode时,将会把hash code的值存在mark work中,对象的整个生命周期内都不会改变,同时**由于mark word中存储了hashcode,占用了在偏向锁状态下需要存储偏向的线程指针,因此,在进入同步临界区时,就不会使用偏向锁 ** - 锁信息
锁的状态迁移可以参考jdk关于Synchronization的wiki,下面的状态迁移图来自该博客

Class Word
class word主要指向实例的类信息,主要作用包括运行时类型检查、对象大小计算以及接口或虚拟方法调用
对象对齐(Object Alignment)
当对象大小不是8的倍数,jvm会采取填充的方式使对象的大小刚好为8的倍数,这样做是为了保持数据的一致,便于快速的数据存取,为了清楚的了解对象的结构,这里我们使用JOL工具,具体使用参见JOL项目主页
对齐规则
- 字段的定义顺序!=内存顺序—— 为了节约内存,类的字段排列是以字段的类型标准,而不是以定义的顺序,double/long、int/float、short/char、bool/byte、references
- 如果对象存在对齐填充,可以把合适的字段放在填充位,而不增加对象总的大小
下面通过jol工具查看Object和Integer在64位环境下的内存结构java -jar jol-cli.jar internals java.lang.Object # Running 64-bit HotSpot VM. # Using compressed oop with 3-bit shift. # Using compressed klass with 3-bit shift. # Objects are 8 bytes aligned. java.lang.Object object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 01 00 00 00 4 4 (object header) 00 00 00 00 8 4 (object header) a8 0e 00 00 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
由于Object没有字段,所以在对象头后面有4字节的填充,下面我们看下Integer:
java -jar jol-cli.jar internals java.lang.Integer
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
Instantiated the sample instance via public java.lang.Integer(int)
java.lang.Integer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) f0 0e 01 00
12 4 int Integer.value 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看见,对象头后面的4个字节被value字段占用。
public class ObjectAlignment{
public Long l;
public int i;
public int i2;
public boolean b;
}
ObjectAlignment object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) N/A
8 4 (object header: class) N/A
12 4 int ObjectAlignment.i N/A
16 4 int ObjectAlignment.i2 N/A
20 1 boolean ObjectAlignment.b N/A
21 3 (alignment/padding gap)
24 4 java.lang.Long ObjectAlignment.l N/A
28 4 (object alignment gap)
Instance size: 32 bytes
Space losses: 3 bytes internal + 4 bytes external = 7 bytes total
- 对于继承关系,将按继承的顺序排列其字段,不同类的字段不会混合排列
public static class A{
long a;
}
public static class B extends A{
int b;
}
public static class C extends B{
int c;
}
ObjectAlignment$C object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x2000c1c0
12 4 (alignment/padding gap)
16 8 long A.a 0
24 4 int B.b 0
28 4 int C.c 0
Instance size: 32 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
- 继承关系中,对齐填充只针对当前类的字段,如果父类或超类存在对齐,子类的字段是不能进行填充的
public static class A{
long a;
}
public static class B extends A{
int b;
boolean b2;
}
public static class C extends B{
boolean c2;
}
ObjectAlignment$C object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x2000c1c0
12 4 (alignment/padding gap)
16 8 long A.a 0
24 4 int B.b 0
28 1 boolean B.b2 false
29 3 (alignment/padding gap)
32 1 boolean C.c2 false
33 7 (object alignment gap)
Instance size: 40 bytes
Space losses: 7 bytes internal + 7 bytes external = 14 bytes total
以上规则实验环境为jdk8,不同的jdk版本实现细节有所差异
类加载过程
概览

Loading
- 普通类由类加载器负责加载,而数组类则由jvm负责加载
- 类加载器分为boostrap加载器和用户定义加载器,bootstrap加载器由jvm提供,用户定义加载器由应用提供
- 在运行时,类通过类加载器和类名来共同确定,所以,同一个类由不同的类加载器分别加载,则是不同的类
hotspot类加载器
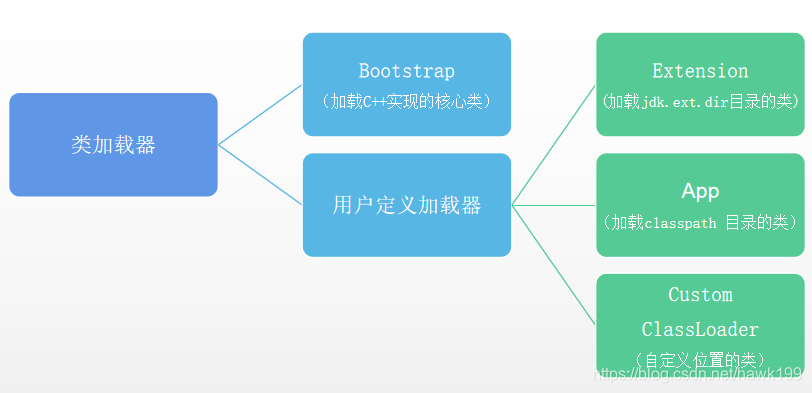
所有的用户定义加载器从类的继承关系上来说,都是ClassLoader的子类
hotspot类加载流程——双亲委派
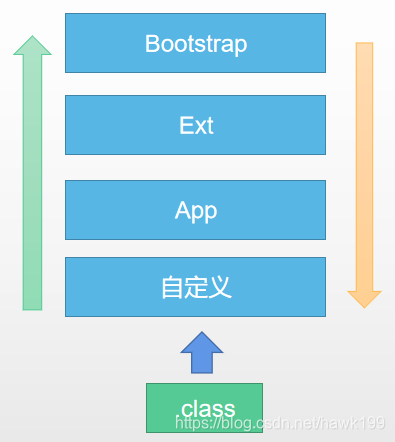
当加载一个类时,首先定义该类的类加载器查找是否已经加载,如果未被加载,则委托其父加载器(类加载器parent字段指定的加载器,而不是继承关系的父加载器),直到bootstrap,如果bootstrap中未找到,bootstrap则委托给其子加载器,直到定义该类的加载器
Linking
Linking阶段分为Verification、Preparation、Resolution三个阶段
Verification
Verification主要验证文件的结构正确
Preparation
Preparation主要是创建类或结构的静态字段,并初始化默认值,不涉及任何jvm代码执行
Resolution
Resolution解析符号引用为对运行时常量池的直接引用
Initializing
执行类或接口的初始化方法(clinit),即静态初始化方法
JMM
为了提高效率,优化程序,编译器、处理器、运行时系统以及多层次存储系统会对程序执行的指令顺序、数据的读写顺序及时间进行重排序,导致与预想的结果不一致,内存模型在不使用同步语句的情况下,为原子性、可见性和有序性提供了最小保证
原子性、可见性、有序性硬件层保障
- 存储的多层次结构
为了提高读取效率,采用缓存行技术,同时有会导致缓存不一致,于是采用缓存锁(缓存一致性协议)、总线锁来保证一致性、可见性、有序性 - 有序性硬件层面保证
- CPU内存屏障(lfence、sfence、mfence)
- LOCK指令
- 原子性
原子性、可见性、有序性jvm层保障
原子性
存取非long/double字段都是原子操作,由于long/double字段涉及高低位,所以需要加上volatile,原子性能保证并发情况下字段的数据位不出现混乱,但是不能保证获得最新的值
可见性
一个线程对字段值做了修改,只有在以下情况下才能被其他线程所见:
- 写线程释放同步锁,读线程随后获取同一同步锁
- 被volatile修饰的字段,写线程每次写入都会立即刷新到内存,读线程每次访问时都会重新加载
- 线程第一次访问对象字段,要么是该字段的初始值,要么是其他线程更新后的值
- 线程终止后,所有有更新的变量都会被刷回内存
有序性
- 从线程内部的角度看,指令以as-if-serial 方式执行
- 从线程间的角度看,始终保持同步块的相对顺序和使用volatile字段
Volatile
- 使用volatile 字段与使用synchronized的get/set方法除了不涉及锁外,几乎是等效的
- volatile 字段对于读写复合操作(比如++、–)不是原子的
- volatile只涉及字段本身的值的存取,不存在传播特性,不保证通过volatile修饰的引用字段访问非volatile字段的可见性
- 如果在方法内部存在对volatile字段的频繁访问,建议还是使用synchronized
happens-before原则
- 程序顺序规则——线程内as-if-serial
- 锁规则——unlock先于同一锁的后续的lock
- 线程启动——start先于线程上的其他操作
- 线程中止——interrupt方法调用先于中止检查
- 线程终止——线程上的所有操作先于终止检查
- 对象规则——对象的初始化完成先行于它的finalize()方法的开始
- 传递性——A先于B,B先于C,则A先于C
- volatile变量规则——写入先于读取
GC
垃圾定位
- 引用计数(reference count)——不能解决循环引用问题
- 根可达(root search)
线程栈、静态引用、本地方法栈、运行时常量池、方法区都是根
垃圾回收算法
- 标记清除(mark sweep)
位置不连续,产生碎片,两遍扫描,效率偏低 - 拷贝算法 (copying)
没有碎片,浪费空间 - 标记压缩(mark compact)
没有碎片,效率偏低(两遍扫描,指针需要调整)
分代模型

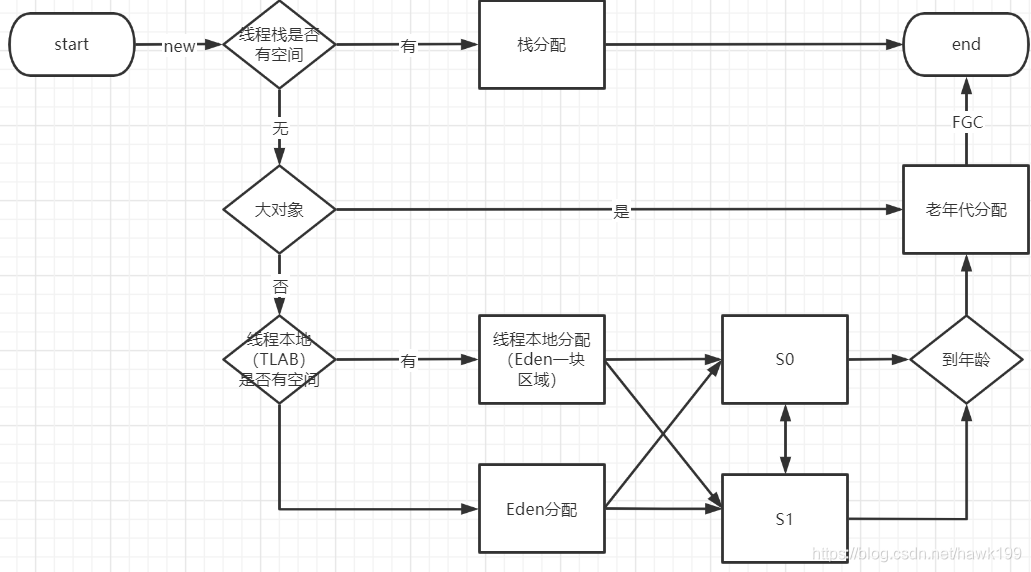
新生代
- 对象多,存活时间短,采用copy算法,效率高
- 新生代分为Eden和2个suvivor区(s0,s1)
- YGC活着的进入s0
- 再次YGC Eden活着的+s0 进入s1
- 再次YGC Eden活着的+s1 进入s0
- 年龄到达进入老年代(大对象直接进入老年代)
老年代
- 对象存活时间长,采用mark compact算法
- 老年代满了会产生full gc(FGC)
永久代
- 1.8之前为Perm Generation,1.8开始为元数据区
- 存放class信息,字符串常量1.8之前放永久代,1.8后放堆
- 永久代必须指定大小,元数据大小设置可选,如没有设置,将受限于物理内存大小
对象分配过程
常见垃圾回收器
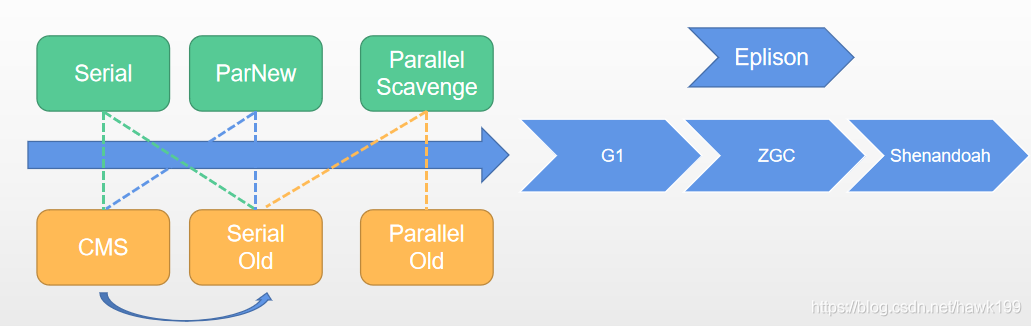
- Serial、PN、PS逻辑物理分代,G1只逻辑分代,Epsilon、ZGC、Shenandoah不分代
- Serial随JDK而诞生,为提高效率,诞生了PS,为配合CMS诞生了PN
- ParNew 和ParallelScavenge都使用并行复制算法,ParNew以减少停顿(STW)时间为目标,而ParallelScavenge以提高吞吐量(运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间))为目标
- 年轻代与老年代回收器组合:Serial+SerialOld、Serial+CMS、ParNew+CMS、ParNew+SerialOld、 ParallelScavenge+SerialOld、ParallelScavenge+ParallelOld
Serial
单GC线程,采用copy算法的年轻代收集器,应用要停顿STW(stop the world)
ParNew
多GC线程并发、采用copy算法的年轻代收集器,应用要停顿STW(stop the world),可以与CMS配合使用,以减少停顿为目标
Parallel Scavenge
多GC线程并发、采用copy算法的年轻代收集器,应用要停顿STW(stop the world),以提高吞吐量为目标
Serial Old
单GC线程,采用标记压缩算法的老年代收集器,应用要停顿STW(stop the world)
Parallel Old
多GC线程,采用标记压缩算法的老年代收集器,应用要停顿STW(stop the world)
CMS
-
CMS(ConcurrentMarkSweep)里程牌式的老年代并发回收器,诞生1.4之后,开启了并发回收时代,垃圾回收和应用运行同时进行,降低了停顿时间(STW),由于采用MarkSweep算法,必然产生碎片,如果空间不足,将使用Serial Old进行垃圾回收,STW时间与老年代大小成正比,由于CMS问题多,所以所有的JDK版本默认GC都不是CMS
-
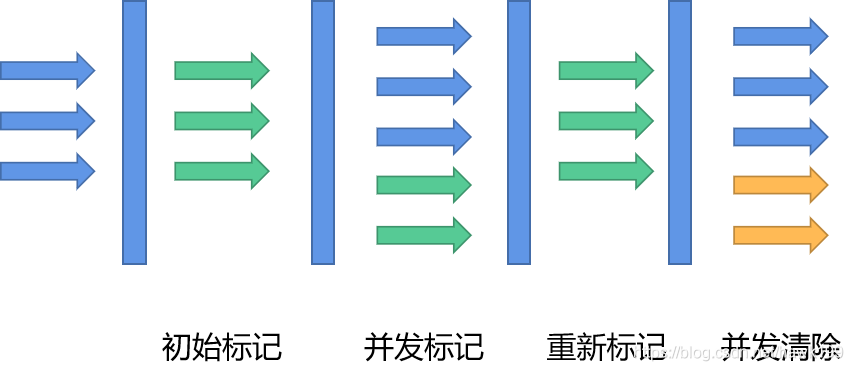
并发标记清除,主要分为4个阶段:
- 初始标记
- 并发标记
- 重新标记
- 并发清除
G1
简介
- G1是一种大内存,多核的服务端垃圾回收器
- G1的目标是在尽量满足指定停顿时间的同时,实现高吞吐量
- 逻辑上分为年轻代和老年代
- 优先回收垃圾最多的区域
- G1采用三色标记和Snapshot-At-The-Beginning (SATB) 算法
堆布局
G1把堆划分为大小相同的多个区域,每个区域要么为空,要么被分配为年轻代或老年代,内存分配时,内存管理分发一个空闲区域,然后指定一个代,有应用程序在空闲空间内自己分配

- 红色区域为年轻代(s为suvivor区)
- 蓝色区域为老年代
- 大对象直接进入老年代
垃圾回收阶段
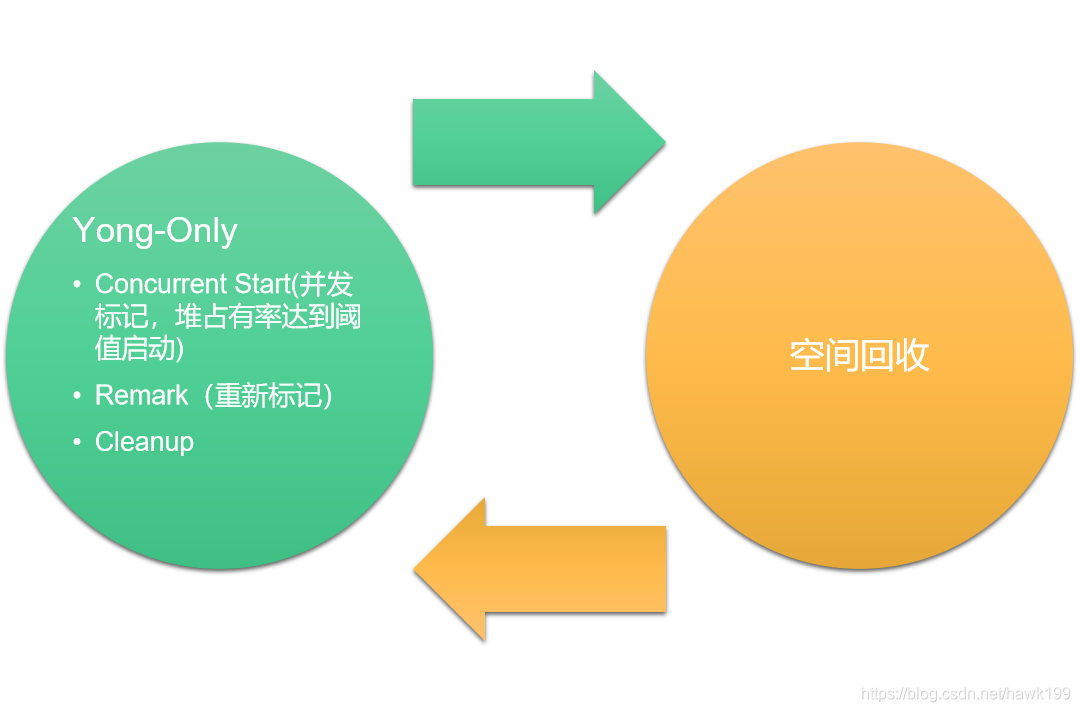
- Yong-Only阶段收集年轻对象提升到老年代
- 堆占有率达到阈值,启动并发标记(Concurrent Start),当remark和clearup暂停时结束标记
- remark 应用暂停,结束标记自身,处理全局引用、卸载类、回收空区域、清除内部数据结构,计 算信息供后续选择老一代进行空间回收
- clearup 应用暂停,决定是否进入空间回收阶段
- 空间回收阶段——包括多个混合收集,不仅处理老年代,也包括年轻代,当没有更多的空间供回收即停止
Collection Set、Remembered Set
- Collection Set:可被回收的区域集合,可以包括年轻代、老年代(含大对象区域)
- Remembered Set:记录其他区域的对象到本区域的引用
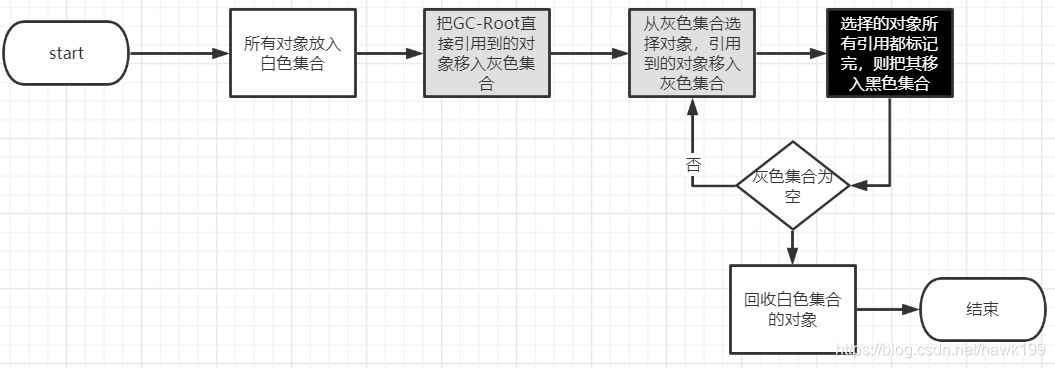
三色标记算法
基本算法
白色:尚未被标记
灰色:对象本身已被标记,但是引用到的对象未被标记
黑色:对象本身和引用到的对象都已被标记
存在问题
由于在标记过程中,应用也在运行,因此可能产生多标和漏标
- 多标(浮动垃圾)
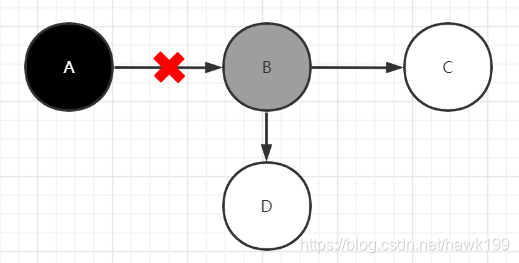
A已经被标记完,此刻,切断A对B的引用,导致A不会被重新标记,而B被认为是存活的,仍然 被遍历,此时BCD应该被回收,但仍然存活,只能下次被回收,但不影响程序的正确性
- 漏标
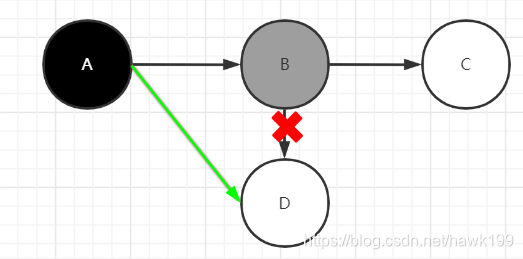
此时,断开B对D的引用,添加A对D的引用,由于A已经被标记,不会被重新标记,导致D被回收,这将影响程序运行的正确性,同时可以看出,漏标需要同时满足以下2个条件:- 删除灰色到白色的引用
- 添加黑色到白的的引用
只要打破以上两个条件之一,就可以解决漏标问题
漏标解决办法
上面的漏标转换成代码即如下:
D d = b.d;
b.d = null;
a.d = d;
我们只要对这三步中的任一步进行拦截,把变化记录下来进行重标就可以,其主要有两种方式:
- 关注引用增加
增量更新(incremental update),把黑色A标记为灰色,重新扫描,CMS采用该方法 - 关注引用删除
SATB(snapshot at the beginning)记录初始对象图,当引用发生变化时,记录下来推送给GC栈,保证变化引用能被扫描到,G1采用该方法
ZGC
待更新
Shenandoah
待更新
垃圾收集器跟内存大小的关系
- Serial <100M
- PS >100M <10G
- CMS 20G
- G1 >100G
- ZGC 4T-16T
GC调优
基础概念
- 吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾回收时间)
- 响应时间:STW时间越短,响应时间越好
调优内容
- 根据需求进行JVM规划和初步设定JVM运行环境
- 根据压测和运行监控优化JVM运行环境(慢、卡顿)
- 解决运行过程中出现的问题(比如OOM)
调优基本步骤
-
确定目标:根据业务场景确定目标,响应时间优先还是吞吐量优先,比如数据挖掘、科学计算吐出量优先,网站响应时间优先
-
选定回收器组合
-
确定内存大小及CPU
-
设定分代(区)大小和升级老年代年龄
-
设置日志参数
-Xloggc:/xxx/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause -
观察分析日志做进一步优化
JVM调优参数
- HotSpot参数分类
-开头标准参数,所有版本都支持
-X开头非标准参数,个别版本支持
-XX开头非稳定参数,后续版本可能被取消
GC常用参数
- -Xmn -Xms -Xmx -Xss
年轻代 最小堆 最大堆 栈空间 - -XX:+UseTLAB
使用TLAB,默认打开 - -XX:+PrintTLAB
打印TLAB的使用情况 - -XX:TLABSize
设置TLAB大小 - -XX:+DisableExplictGC
禁用System.gc()调用,System.gc()调用可能引起FGC - -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintHeapAtGC
- -XX:+PrintGCTimeStamps
- -XX:+PrintGCApplicationConcurrentTime
打印应用程序时间 - -XX:+PrintGCApplicationStoppedTime
打印暂停时长 - -XX:+PrintReferenceGC
记录回收了多少种不同引用类型的引用 - -verbose:class
类加载详细过程 - -XX:+PrintVMOptions
大于VM options参数 - -XX:+PrintFlagsFinal -XX:+PrintFlagsInitial
- -Xloggc:gc.log
- -XX:MaxTenuringThreshold
升代年龄,最大值15
Parallel常用参数
- -XX:SurvivorRatio
- -XX:PreTenureSizeThreshold
大对象到底多大 - -XX:MaxTenuringThreshold
- -XX:+ParallelGCThreads
并行收集器的线程数,同样适用于CMS,一般设为和CPU核数相同 - -XX:+UseAdaptiveSizePolicy
自动选择各区大小比例
CMS常用参数
- -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSThreads CMS线程数量
- -XX:CMSInitiatingOccupancyFraction 老年代后内存使用多少比例后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收)
- -XX:+UseCMSCompactAtFullCollection 在FGC时进行压缩
- -XX:CMSFullGCsBeforeCompaction 多少次FGC之后进行压缩
- -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction 达到什么比例时进行Perm回收 GCTimeRatio 设置GC时间占用程序运行时间的百分比
- -XX:MaxGCPauseMillis 停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代
G1常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis
建议值,G1会尝试调整Young区的块数来达到这个值 - -XX:GCPauseIntervalMillis
GC的间隔时间 - -XX:+G1HeapRegionSize
分区大小,建议逐渐增大该值,1、2、4、8、16、32,随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长,ZGC采用动态区块大小 - -XX:+G1NewSizePercent
新生代最小比例,默认为5% - -XX:+G1MaxNewSizePercent
新生代最大比例,默认为60% - -XX:+GCTimeRatio
GC时间建议比例,G1会根据这个值调整堆空间 - -XX:+ConcGCThreads
线程数量 - -XX:+InitiatingHeapOccupancyPercent
启动G1的堆空间占用比例
JVM问题分析常用工具
监控工具
- jps定位java线程
- jstat/jstatd/ jconsole/jvisualVM 性能分析工具
问题诊断工具
- jinfo java线程运行的环境信息
- jmap 打印堆内存详情
- jstack 打印线程堆栈跟踪信息
- jhat 堆dump文件浏览
在线问题分析工具
问题诊断步骤
- 定位问题线程(内存/CPU占比比较高)
- jmap查看内存信息/jstack查看线程堆栈信息/jstat -gc查看gc信息
- 数据分析
也可以使用jmap dump内存,但是对于内存特别大的线上系统,请慎用