随机变量
设随机试验的样本空间为S={e}. X=X(e) 是定义在样本空间S上的实值单值函数。称X=X(e)为随机变量。
离散型随机变量
定义: 全部可能取到的值为有限个或可列无限多个,这种随机变量称为离散型随机变量。
投骰子的点数,打靶环数,某城市120急救电话一昼夜收到的呼叫次数,都是离散型随机变量。
设离散型随机变量X所有可能取的值为(k=1,2,⋯) ,X取各个可能值的概率,即事件X=
的概率,为
称该式为离散型随机变量的分布律
性质:
-
, k = 1,2,3 …
-
连续型随机变量
连续型随机变量是指如果随机变量X的所有可能取值不可以逐个列举出来,而是取数轴上某一区间内的任一点的随机变量。
比如,一次掷20个硬币,k个硬币正面朝上,
k是随机变量,
k的取值只能是自然数0,1,2,…,20,而不能取小数3.5、无理数√20……
因而k是离散型随机变量。
如果变量可以在某个区间内取任一实数,即变量的取值可以是连续的,这随机变量就称为连续型随机变量。
比如,公共汽车每15分钟一班,某人在站台等车时间x是个随机变量,
x的取值范围是[0,15),它是一个区间,从理论上说在这个区间内可取任一实数3分钟、5分钟7毫秒、7√2分钟,在这十五分钟的时间轴上任取一点,都可能是等车的时间,因而称这随机变量是连续型随机变量。
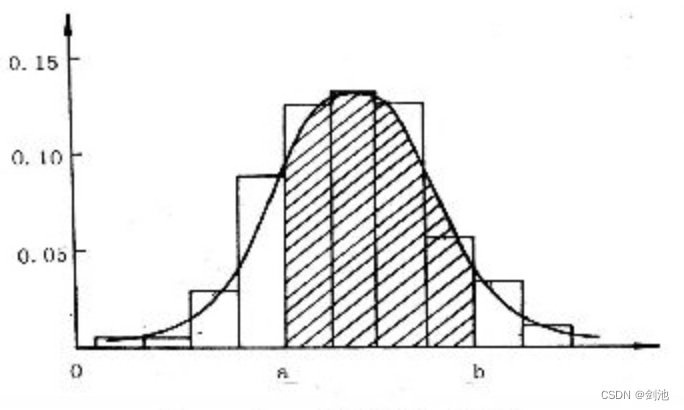
概率密度函数
如果对于随机变量X的分布函数F(x),存在非负函数f(x),使得对于任意实数有,
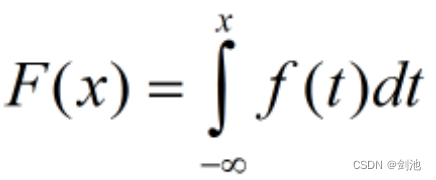
则称X为连续型随机变量,其中F(x)称为X的概率密度函数,简称概率密度。(f(x)>=0,若f(x)在点x处连续则F(x)求导可得)f(x)并没有很特殊的意义,但是通过其值得相对大小得知,若f(x)越大,对于同样长度的区间,X落在这个区间的概率越大。
如果在[0,1]上随机取点,求取在某一点处的概率,点的长度无限小,此概率一定为0。这时情况和上面所述类似,我们需要引入概率密度p,其中
这样我们就可以求所取点落在某一段(a,b)上的概率了。概率
概率密度和物理上密度的定义本质上是一样的。做题的时候一般就两种。一是知道概率密度函数,求分布函数,积分就好了。二是知道了分布函数,求概率密度函数,求导就好了。
只有连续型函数才有概率密度!
某一点的值是没有概率的P(X=1) = 0;
某一段的概率:设F(x)是概率分布函数,如果f(x)在[-无穷,x]的积分就是F(x),f(x)>=0,则乘f(x)为x的概率密度函数。
概率分布求导数就是概率分布函数!
简单随机抽样
是指从总体N个单位中任意抽取n个单位作为样本,使每个可能的样本被抽中的概率相等的一种抽样方式。
简单随机抽样的特点:
简单随机抽样的特点是:每个样本单位被抽中的概率相等,样本的每个单位完全独立,彼此间无一定的关联性和排斥性。
似然函数
似然函数是一种关于统计模型参数的函数。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:L(θ|x)=P(X=x|θ)。
离散型概率分布
假定一个关于参数θ、具有离散型概率分布P的随机变量X,则在给定X的输出x时,参数θ的似然函数可表示为 ![]()
其中, 表示X取x时的概率。上式常常写为 ![]() 。需要注意的是,此处并非条件概率,因为θ不(总)是随机变量。
。需要注意的是,此处并非条件概率,因为θ不(总)是随机变量。
连续型概率分布
假定一个关于参数θ、具有连续概率密度函数f的随机变量X,则在给定X的输出x时,参数θ的似然函数可表示为![]()
上式常常写为 ,同样需要注意的是,此处并非条件概率密度函数。
常说的概率是指给定参数后,预测即将发生的事件的可能性。拿硬币这个例子来说,我们已知一枚均匀硬币的正反面概率分别是0.5,要预测抛两次硬币,硬币都朝上的概率:
H代表Head,表示头朝上
p(HH | pH = 0.5) = 0.5*0.5 = 0.25.
这种写法其实有点误导,后面的这个p其实是作为参数存在的,而不是一个随机变量,因此不能算作是条件概率,更靠谱的写法应该是 p(HH;p=0.5)。
而似然概率正好与这个过程相反,我们关注的量不再是事件的发生概率,而是已知发生了某些事件,我们希望知道参数应该是多少。
现在我们已经抛了两次硬币,并且知道了结果是两次头朝上,这时候,我希望知道这枚硬币抛出去正面朝上的概率为0.5的概率是多少?正面朝上的概率为0.8的概率是多少?
如果我们希望知道正面朝上概率为0.5的概率,这个东西就叫做似然函数,可以说成是对某一个参数的猜想(p=0.5)的概率,这样表示成(条件)概率就是
L(pH=0.5|HH) = P(HH|pH=0.5) = (另一种写法)P(HH;pH=0.5).
为什么可以写成这样?我觉得可以这样来想:
似然函数本身也是一种概率,我们可以把L(pH=0.5|HH)写成P(pH=0.5|HH); 而根据贝叶斯公式,P(pH=0.5|HH) = P(pH=0.5,HH)/P(HH);既然HH是已经发生的事件,理所当然P(HH) = 1,所以:
P(pH=0.5|HH) = P(pH=0.5,HH) = P(HH;pH=0.5).
右边的这个计算我们很熟悉了,就是已知头朝上概率为0.5,求抛两次都是H的概率,即0.5*0.5=0.25。
所以,我们可以safely得到:
L(pH=0.5|HH) = P(HH|pH=0.5) = 0.25.
这个0.25的意思是,在已知抛出两个正面的情况下,pH = 0.5的概率等于0.25。
再算一下
L(pH=0.6|HH) = P(HH|pH=0.6) = 0.36.
把pH从0~1的取值所得到的似然函数的曲线画出来得到这样一张图:
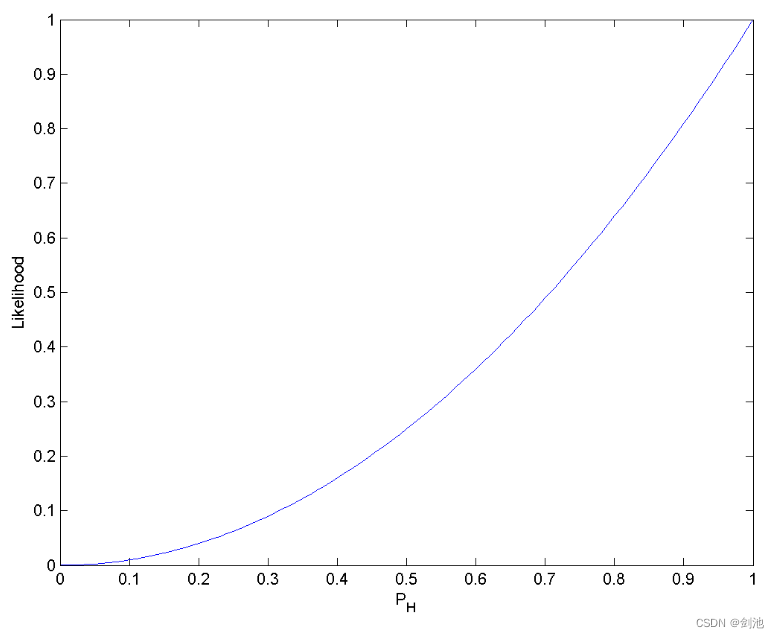
可以发现,pH = 1的概率是最大的。
即L(pH = 1|HH) = 1。
那么最大似然概率的问题也就好理解了。
最大似然概率,就是在已知观测的数据的前提下,找到使得似然概率最大的参数值。
这就不难理解,在数据挖掘领域,许多求参数的方法最终都归结为最大化似然概率的问题。
回到这个硬币的例子上来,在观测到HH的情况下,pH = 1是最合理的(却未必符合真实情况,因为数据量太少的缘故)。