2.Docker守护进程会在Docker镜像的最上层之上,再添加一个可读写层,容器所有的写操作都会作用到这一层中。而如果Docker容器需要写底层Docker镜像中的文件,那么此时就会涉及一个叫Copy-on-Write的机制,即aufs等联合文件系统保证:首先将此文件从Docker镜像层中拷贝至最上层的可读写层,然后容器进程再对读写层中的副本进行写操纵。对于容器进程来讲,它只能看到最上层的文件。
3.Docker容器中不存在Docker镜像中的内容主要有以下几点:
1./proc以及/sys等虚拟文件系统的内容
2.容器的hosts文件,hostname文件以及resolv.conf文件,这些事具体环境的信息,原则上的确不应该被打入镜像。
3.容器的Volume路径,这部分的视角来源于从宿主机上挂载到容器内部的路径
4.部分的设备文件
4.https://blog.csdn.net/zjin_hua/article/details/52041757
5.有了以上 6 种 namespace 从进程、网络、IPC、文件系统、UTS 和用户角度的隔离,一个 container 就可以对
外展现出一个独立计算机的能力,并且不同 container 从 OS 层面实现了隔离。 然而不同 namespace 之间资源>还是相互竞争的,仍然需要类似 ulimit 来管理每个 container 所能使用的资源 – cgroup。
6.cgroups 实现了对资源的配额和度量。 cgroups 的使用非常简单,提供类似文件的接口,在 /cgroup 目录下新
建一个文件夹即可新建一个 group,在此文件夹中新建 task 文件,并将 pid 写入该文件,即可实现对该进程的>资源控制。
7、Docker 网络配置

图: Docker – container and lightweight virtualization
Dokcer 通过使用 Linux 桥接提供容器之间的通信,docker0 桥接接口的目的就是方便 Docker 管理。当 Docker daemon 启动时需要做以下操作:
- creates the docker0 bridge if not present
- # 如果 docker0 不存在则创建
- searches for an IP address range which doesn’t overlap with an existing route
- # 搜索一个与当前路由不冲突的 ip 段
- picks an IP in the selected range
- # 在确定的范围中选择 ip
- assigns this IP to the docker0 bridge
- # 绑定 ip 到 docker0
6.1 Docker 四种网络模式
四种网络模式摘自 Docker 网络详解及 pipework 源码解读与实践
docker run 创建 Docker 容器时,可以用 –net 选项指定容器的网络模式,Docker 有以下 4 种网络模式:
- host 模式,使用 –net=host 指定。
- container 模式,使用 –net=container:NAMEorID 指定。
- none 模式,使用 –net=none 指定。
- bridge 模式,使用 –net=bridge 指定,默认设置。
host 模式
如果启动容器的时候使用 host 模式,那么这个容器将不会获得一个独立的 Network Namespace,而是和宿主机共用一个 Network Namespace。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。
例如,我们在 10.10.101.105/24 的机器上用 host 模式启动一个含有 web 应用的 Docker 容器,监听 tcp 80 端口。当我们在容器中执行任何类似 ifconfig 命令查看网络环境时,看到的都是宿主机上的信息。而外界访问容器中的应用,则直接使用 10.10.101.105:80 即可,不用任何 NAT 转换,就如直接跑在宿主机中一样。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
container 模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
none模式
这个模式和前两个不同。在这种模式下,Docker 容器拥有自己的 Network Namespace,但是,并不为 Docker容器进行任何网络配置。也就是说,这个 Docker 容器没有网卡、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。
bridge模式

图:The Container World | Part 2 Networking
bridge 模式是 Docker 默认的网络设置,此模式会为每一个容器分配 Network Namespace、设置 IP 等,并将一个主机上的 Docker 容器连接到一个虚拟网桥上。当 Docker server 启动时,会在主机上创建一个名为 docker0 的虚拟网桥,此主机上启动的 Docker 容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。接下来就要为容器分配 IP 了,Docker 会从 RFC1918 所定义的私有 IP 网段中,选择一个和宿主机不同的IP地址和子网分配给 docker0,连接到 docker0 的容器就从这个子网中选择一个未占用的 IP 使用。如一般 Docker 会使用 172.17.0.0/16 这个网段,并将 172.17.42.1/16 分配给 docker0 网桥(在主机上使用 ifconfig 命令是可以看到 docker0 的,可以认为它是网桥的管理接口,在宿主机上作为一块虚拟网卡使用)
6.2 列出当前主机网桥
$ sudo brctl show # brctl 工具依赖 bridge-utils 软件包 bridge name bridge id STP enabled interfaces docker0 8000.000000000000 no
6.3 查看当前 docker0 ip
$ sudo ifconfig docker0 docker0 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx inet addr:172.17.42.1 Bcast:0.0.0.0 Mask:255.255.0.0
在容器运行时,每个容器都会分配一个特定的虚拟机口并桥接到 docker0。每个容器都会配置同 docker0 ip 相同网段的专用 ip 地址,docker0 的 IP 地址被用于所有容器的默认网关。
6.4 运行一个容器
$ sudo docker run -t -i -d ubuntu /bin/bash 52f811c5d3d69edddefc75aff5a4525fc8ba8bcfa1818132f9dc7d4f7c7e78b4 $ sudo brctl show bridge name bridge id STP enabled interfaces docker0 8000.fef213db5a66 no vethQCDY1N
以上, docker0 扮演着 52f811c5d3d6 container 这个容器的虚拟接口 vethQCDY1N interface 桥接的角色。
使用特定范围的 IP
Docker 会尝试寻找没有被主机使用的 ip 段,尽管它适用于大多数情况下,但是它不是万能的,有时候我们还是需要对 ip 进一步规划。Docker 允许你管理 docker0 桥接或者通过-b选项自定义桥接网卡,需要安装bridge-utils软件包。
基本步骤如下:
- ensure Docker is stopped
- # 确保 docker 的进程是停止的
- create your own bridge (bridge0 for example)
- # 创建自定义网桥
- assign a specific IP to this bridge
- # 给网桥分配特定的 ip
- start Docker with the -b=bridge0 parameter
- # 以 -b 的方式指定网桥
# Stopping Docker and removing docker0 $ sudo service docker stop $ sudo ip link set dev docker0 down $ sudo brctl delbr docker0 # Create our own bridge $ sudo brctl addbr bridge0 $ sudo ip addr add 192.168.5.1/24 dev bridge0 $ sudo ip link set dev bridge0 up # Confirming that our bridge is up and running $ ip addr show bridge0
4: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state UP group default
link/ether 66:38:d0:0d:76:18 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.1/24 scope global bridge0
valid_lft forever preferred_lft forever # Tell Docker about it and restart (on Ubuntu) $ echo 'DOCKER_OPTS="-b=bridge0"' >> /etc/default/docker $ sudo service docker start
参考文档: Network Configuration
6.5 不同主机间容器通信
不同容器之间的通信可以借助于 pipework 这个工具:
$ git clone https://github.com/jpetazzo/pipework.git $ sudo cp -rp pipework/pipework /usr/local/bin/
安装相应依赖软件
$ sudo apt-get install iputils-arping bridge-utils -y
桥接网络
桥接网络可以参考 日常问题处理 Tips 关于桥接的配置说明,这里不再赘述。
# brctl show bridge name bridge id STP enabled interfaces br0 8000.000c291412cd no eth0 docker0 8000.56847afe9799 no vetheb48029
可以删除 docker0,直接把 docker 的桥接指定为 br0。也可以保留使用默认的配置,这样单主机容器之间的通信可以通过 docker0,而跨主机不同容器之间通过 pipework 新建 docker 容器的网卡桥接到 br0,这样跨主机容器之间就可以通信了。
- ubuntu
$ sudo service docker stop $ sudo ip link set dev docker0 down $ sudo brctl delbr docker0 $ echo 'DOCKER_OPTS="-b=br0"' >> /etc/default/docker $ sudo service docker start
- CentOS 7/RHEL 7
$ sudo systemctl stop docker $ sudo ip link set dev docker0 down $ sudo brctl delbr docker0 $ cat /etc/sysconfig/docker | grep 'OPTIONS=' OPTIONS=--selinux-enabled -b=br0 -H fd:// $ sudo systemctl start docker
pipework

不同容器之间的通信可以借助于 pipework 这个工具给 docker 容器新建虚拟网卡并绑定 IP 桥接到 br0
$ git clone https://github.com/jpetazzo/pipework.git $ sudo cp -rp pipework/pipework /usr/local/bin/ $ pipework Syntax: pipework <hostinterface> [-i containerinterface] <guest> <ipaddr>/<subnet>[@default_gateway] [macaddr][@vlan] pipework <hostinterface> [-i containerinterface] <guest> dhcp [macaddr][@vlan] pipework --wait [-i containerinterface]
如果删除了默认的 docker0 桥接,把 docker 默认桥接指定到了 br0,则最好在创建容器的时候加上–net=none,防止自动分配的 IP 在局域网中有冲突。
$ sudo docker run --rm -ti --net=none ubuntu:14.04 /bin/bash
root@a46657528059:/#
$ # Ctrl-P + Ctrl-Q 回到宿主机 shell,容器 detach 状态
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a46657528059 ubuntu:14.04 "/bin/bash" 4 minutes ago Up 4 minutes hungry_lalande
$ sudo pipework br0 -i eth0 a46657528059 192.168.115.10/24@192.168.115.2
# 默认不指定网卡设备名,则默认添加为 eth1
# 另外 pipework 不能添加静态路由,如果有需求则可以在 run 的时候加上 --privileged=true 权限在容器中手动添加,
# 但这种安全性有缺陷,可以通过 ip netns 操作
$ sudo docker attach a46657528059
root@a46657528059:/# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 86:b6:6b:e8:2e:4d
inet addr:192.168.115.10 Bcast:0.0.0.0 Mask:255.255.255.0
inet6 addr: fe80::84b6:6bff:fee8:2e4d/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:648 (648.0 B) TX bytes:690 (690.0 B)
root@a46657528059:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.115.2 0.0.0.0 UG 0 0 0 eth0
192.168.115.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
使用ip netns添加静态路由,避免创建容器使用–privileged=true选项造成一些不必要的安全问题:
$ docker inspect --format="{{ .State.Pid }}" a46657528059 # 获取指定容器 pid
6350
$ sudo ln -s /proc/6350/ns/net /var/run/netns/6350
$ sudo ip netns exec 6350 ip route add 192.168.0.0/16 dev eth0 via 192.168.115.2
$ sudo ip netns exec 6350 ip route # 添加成功
192.168.0.0/16 via 192.168.115.2 dev eth0
... ...
在其它宿主机进行相应的配置,新建容器并使用 pipework 添加虚拟网卡桥接到 br0,测试通信情况即可。
————————————————-
docker client
————————————————–
Docker Server的启动,命令为docker -d或docker –daemon=true;而Docker Client的启动则体现为docker –daemon=false ps、docker pull NAME等。
以一个具体的docker命令为例,docker –daemon=false –version=false pull Name。通过以上的分析,可以总结出以下操作流程:
(1) 解析flag参数之后,将docker请求参数”pull”和“Name”存放于flag.Args();
(2) 创建好的Docker Client为cli,cli执行cli.Cmd(flag.Args()…);
在Cmd函数中,通过args[0]也就是”pull”,执行cli.getMethod(args[0]),获取method的名称;
(3) 在getMothod方法中,通过处理最终返回method的值为”CmdPull”;
(4) 最终执行method(args[1:]…)也就是CmdPull(args[1:]…)。
总之,请求执行过程中,大多都是将命令行中关于请求的参数进行初步处理,并添加相应的辅助信息,最终通过指定的协议给Docker Server发送Docker Client和Docker Server约定好的API请求。
————————————————-
docker Daemon
————————————————–
Docker Daemon是Docker架构中运行在后台的守护进程,大致可以分为Docker Server、Engine和Job三部分.
Docker Daemon可以认为是通过Docker Server模块接受Docker Client的请求,并在Engine中处理请求,然后根据请求类型,创建出指定的Job并运行,运行过程的作用有以下几种可能:向Docker Registry获取镜像,通过graphdriver执行容器镜像的本地化操作,通过networkdriver执行容器网络环境的配置,通过execdriver执行容器内部运行的执行工作等。
以下为Docker Daemon的架构示意图:

3 Docker Daemon源码分析内容安排
本文从源码的角度,主要分析Docker Daemon的启动流程。由于Docker Daemon和Docker Client的启动流程有很大的相似之处,故在介绍启动流程之后,本文着重分析启动流程中最为重要的环节:创建daemon过程中mainDaemon()的实现。
4 Docker Daemon的启动流程
由于Docker Daemon和Docker Client的启动都是通过可执行文件docker来完成的,因此两者的启动流程非常相似。Docker可执行文件运行时,运行代码通过不同的命令行flag参数,区分两者,并最终运行两者各自相应的部分。
启动Docker Daemon时,一般可以使用以下命令:docker –daemon=true; docker –d; docker –d=true等。接着由docker的main()函数来解析以上命令的相应flag参数,并最终完成Docker Daemon的启动。
5 mainDaemon( )的具体实现
通过Docker Daemon的流程图,可以得出一个这样的结论:有关Docker Daemon的所有的工作,都被包含在mainDaemon()方法的实现中。
宏观来讲,mainDaemon()完成创建一个daemon进程,并使其正常运行。
从功能的角度来说,mainDaemon()实现了两部分内容:第一,创建Docker运行环境;第二,服务于Docker Client,接收并处理相应请求。
从实现细节来讲,mainDaemon()的实现过程主要包含以下步骤:
- daemon的配置初始化(这部分在init()函数中实现,即在mainDaemon()运行前就执行,但由于这部分内容和mainDaemon()的运行息息相关,故可认为是mainDaemon()运行的先决条件);
- 命令行flag参数检查;
- 创建engine对象;
- 设置engine的信号捕获及处理方法;
- 加载builtins;
- 使用goroutine加载daemon对象并运行;
- 打印Docker版本及驱动信息;
- Job之”serveapi”的创建与运行
在代码实现部分,第一个工作即为创建一个Engine结构体实例eng;第二个工作是向eng对象注册名为commands的Handler,其中Handler为临时定义的函数func(job *Job) Status{ } , 该函数的作用是通过job来打印所有已经注册完毕的command名称,最终返回状态StatusOK;第三个工作是:将已定义的变量globalHandlers中的所有的Handler,都复制到eng对象的handlers属性中。最后成功返回eng对象。
加载builtins的主要工作是为:为engine注册多个Handler,以便后续在执行相应任务时,运行指定的Handler。这些Handler包括:网络初始化、web API服务、事件查询、版本查看、Docker Registry验证与搜索。
5.4.1 注册初始化网络驱动的Handler
daemon(eng)的实现过程,主要为eng对象注册了一个key为”init_networkdriver”的Handler,该Handler的值为bridge.InitDriver函数,代码如下:
func daemon(eng *engine.Engine) error {
return eng.Register("init_networkdriver", bridge.InitDriver)
}
需要注意的是,向eng对象注册Handler,并不代表Handler的值函数会被直接运行,如bridge.InitDriver,并不会直接运行,而是将bridge.InitDriver的函数入口,写入eng的handlers属性中。
Bridge.InitDriver的具体实现位于./docker/daemon/networkdriver/bridge/driver.go ,主要作用为:
- 获取为Docker服务的网络设备的地址;
- 创建指定IP地址的网桥;
- 配置网络iptables规则;
- 另外还为eng对象注册了多个Handler,如 ”allocate_interface”, ”release_interface”, ”allocate_port”,”link”。
5.4.2 注册API服务的Handler
remote(eng)的实现过程,主要为eng对象注册了两个Handler,分别为”serveapi”与”acceptconnections”。代码实现如下:
func remote(eng *engine.Engine) error {
if err := eng.Register("serveapi", apiserver.ServeApi); err != nil {
return err
}
return eng.Register("acceptconnections", apiserver.AcceptConnections)
}
注册的两个Handler名称分别为”serveapi”与”acceptconnections”,相应的执行方法分别为apiserver.ServeApi与apiserver.AcceptConnections,具体实现位于./docker/api/server/server.go。其中,ServeApi执行时,通过循环多种协议,创建出goroutine来配置指定的http.Server,最终为不同的协议请求服务;而AcceptConnections的实现主要是为了通知init守护进程,Docker Daemon已经启动完毕,可以让Docker Daemon进程接受请求。
5.4.3 注册events事件的Handler
events.New().Install(eng)的实现过程,为Docker注册了多个event事件,功能是给Docker用户提供API,使得用户可以通过这些API查看Docker内部的events信息,log信息以及subscribers_count信息。具体的代码位于./docker/events/events.go,如下:
func (e *Events) Install(eng *engine.Engine) error {
jobs := map[string]engine.Handler{
"events": e.Get,
"log": e.Log,
"subscribers_count": e.SubscribersCount,
}
for name, job := range jobs {
if err := eng.Register(name, job); err != nil {
return err
}
}
return nil
}
5.4.4 注册版本的Handler
eng.Register(“version”,dockerVersion)的实现过程,向eng对象注册key为”version”,value为”dockerVersion”执行方法的Handler,dockerVersion的执行过程中,会向名为version的job的标准输出中写入Docker的版本,Docker API的版本,git版本,Go语言运行时版本以及操作系统等版本信息。dockerVersion的具体实现如下:
func dockerVersion(job *engine.Job) engine.Status {
v := &engine.Env{}
v.SetJson("Version", dockerversion.VERSION)
v.SetJson("ApiVersion", api.APIVERSION)
v.Set("GitCommit", dockerversion.GITCOMMIT)
v.Set("GoVersion", runtime.Version())
v.Set("Os", runtime.GOOS)
v.Set("Arch", runtime.GOARCH)
if kernelVersion, err := kernel.GetKernelVersion(); err == nil {
v.Set("KernelVersion", kernelVersion.String())
}
if _, err := v.WriteTo(job.Stdout); err != nil {
return job.Error(err)
}
return engine.StatusOK
}
5.4.5 注册registry的Handler
registry.NewService().Install(eng)的实现过程位于./docker/registry/service.go,在eng对象对外暴露的API信息中添加docker registry的信息。当registry.NewService()成功被Install安装完毕的话,则有两个调用能够被eng使用:”auth”,向公有registry进行认证;”search”,在公有registry上搜索指定的镜像。
Install的具体实现如下:
func (s *Service) Install(eng *engine.Engine) error {
eng.Register("auth", s.Auth)
eng.Register("search", s.Search)
return nil
}
至此,所有builtins的加载全部完成,实现了向eng对象注册特定的Handler。
————————————————-
Docker Daemon之NewDaemon实现
————————————————–
Docker Daemon中NewDaemon的执行流程主要包含12个独立的步骤:处理配置信息、检测系统支持及用户权限、配置工作路径、加载并配置graphdriver、创建Docker Daemon网络环境、创建并初始化graphdb、创建execdriver、创建daemon实例、检测DNS配置、加载已有container、设置shutdown处理方法、以及返回daemon实例。
将大篇幅分析NewDaemonFromDirectory的实现细节。
4.1. 应用配置信息
在NewDaemonFromDirectory的实现过程中,第一个工作是:如何应用传入的配置信息。这部分配置信息服务于Docker Daemon的运行,并在Docker Daemon启动初期就初始化完毕。配置信息的主要功能是:供用户自由配置Docker的可选功能,使得Docker的运行更贴近用户期待的运行场景。
配置信息的处理包含4部分:
- 配置Docker容器的MTU;
- 检测网桥配置信息;
- 查验容器通信配置;
- 处理PID文件配置。
4.1.1. 配置Docker容器的MTU
config信息中的Mtu应用于容器网络的最大传输单元(MTU)特性。有关MTU的源码如下:
if config.Mtu == 0 {
config.Mtu = GetDefaultNetworkMtu()
可见,若config信息中Mtu的值为0的话,则通过GetDefaultNetworkMtu函数将Mtu设定为默认的值;否则,采用config中的Mtu值。由于在默认的配置文件./docker/daemon/config.go(下文简称为默认配置文件)中,初始化时Mtu属性值为0,故执行GetDefaultNetworkMtu。
GetDefaultNetworkMtu函数的具体实现位于./docker/daemon/config.go:
func GetDefaultNetworkMtu() int {
if iface, err := networkdriver.GetDefaultRouteIface(); err == nil {
return iface.MTU
}
return defaultNetworkMtu
}
GetDefaultNetworkMtu的实现中,通过networkdriver包的GetDefaultRouteIface方法获取具体的网络设备,若该网络设备存在,则返回该网络设备的MTU属性值;否则的话,返回默认的MTU值defaultNetworkMtu,值为1500。
4.1.2. 检测网桥配置信息
处理完config中的Mtu属性之后,马上检测config中BridgeIface和BridgeIP这两个信息。BridgeIface和BridgeIP的作用是为创建网桥的任务”init_networkdriver”提供参数。代码如下:
if config.BridgeIface != "" && config.BridgeIP != "" {
return nil, fmt.Errorf("You specified -b & --bip, mutually exclusive options.
Please specify only one.")
}
以上代码的含义为:若config中BridgeIface和BridgeIP两个属性均不为空,则返回nil对象,并返回错误信息,错误信息内容为:用户同时指定了BridgeIface和BridgeIP,这两个属性属于互斥类型,只能至多指定其中之一。而在默认配置文件中,BridgeIface和BridgeIP均为空。
4.1.3. 查验容器通信配置
检测容器的通信配置,主要是针对config中的EnableIptables和InterContainerCommunication这两个属性。EnableIptables属性的作用是启用Docker对iptables规则的添加功能;InterContainerCommunication的作用是启用Docker container之间互相通信的功能。代码如下:
if !config.EnableIptables && !config.InterContainerCommunication {
return nil, fmt.Errorf("You specified --iptables=false with --icc=
false. ICC uses iptables to function. Please set --icc or --iptables to true.")
}
代码含义为:若EnableIptables和InterContainerCommunication两个属性的值均为false,则返回nil对象以及错误信息。其中错误信息为:用户将以上两属性均置为false,container间通信需要iptables的支持,需设置至少其中之一为true。而在默认配置文件中,这两个属性的值均为true。
4.1.4. 处理网络功能配置
接着,处理config中的DisableNetwork属性,以备后续在创建并执行创建Docker Daemon网络环境时使用,即在名为”init_networkdriver”的job创建并运行中体现。
config.DisableNetwork = config.BridgeIface == DisableNetworkBridge
由于config中的BridgeIface属性值为空,另外DisableNetworkBridge的值为字符串”none”,因此最终config中DisableNetwork的值为false。后续名为”init_networkdriver”的job在执行过程中需要使用该属性。
4.1.5. 处理PID文件配置
处理PID文件配置,主要工作是:为Docker Daemon进程运行时的PID号创建一个PID文件,文件的路径即为config中的Pidfile属性。并且为Docker Daemon的shutdown操作添加一个删除该Pidfile的函数,以便在Docker Daemon退出的时候,可以在第一时间删除该Pidfile。处理PID文件配置信息的代码实现如下:
if config.Pidfile != "" {
if err := utils.CreatePidFile(config.Pidfile); err != nil {
return nil, err
}
eng.OnShutdown(func() {
utils.RemovePidFile(config.Pidfile)
})
}
代码执行过程中,首先检测config中的Pidfile属性是否为空,若为空,则跳过代码块继续执行;若不为空,则首先在文件系统中创建具体的Pidfile,然后向eng的onShutdown属性添加一个处理函数,函数具体完成的工作为utils.RemovePidFile(config.Pidfile),即在Docker Daemon进行shutdown操作的时候,删除Pidfile文件。在默认配置文件中,Pidfile文件的初始值为” /var/run/docker.pid”。
以上便是关于配置信息处理的分析。
4.2. 检测系统支持及用户权限
初步处理完Docker的配置信息之后,Docker对自身运行的环境进行了一系列的检测,主要包括三个方面:
- 操作系统类型对Docker Daemon的支持;
- 用户权限的级别;
- 内核版本与处理器的支持。
系统支持与用户权限检测的实现较为简单,实现代码如下:
if runtime.GOOS != "linux" {
log.Fatalf("The Docker daemon is only supported on linux")
}
if os.Geteuid() != 0 {
log.Fatalf("The Docker daemon needs to be run as root")
}
if err := checkKernelAndArch(); err != nil {
log.Fatalf(err.Error())
}
首先,通过runtime.GOOS,检测操作系统的类型。runtime.GOOS返回运行程序所在操作系统的类型,可以是Linux,Darwin,FreeBSD等。结合具体代码,可以发现,若操作系统不为Linux的话,将报出Fatal错误日志,内容为“Docker Daemon只能支持Linux操作系统”。
接着,通过os.Geteuid(),检测程序用户是否拥有足够权限。os.Geteuid()返回调用者所在组的group id。结合具体代码,也就是说,若返回不为0,则说明不是以root用户的身份运行,报出Fatal日志。
最后,通过checkKernelAndArch(),检测内核的版本以及主机处理器类型。checkKernelAndArch()的实现同样位于./docker/daemon/daemon.go。实现过程中,第一个工作是:检测程序运行所在的处理器架构是否为“amd64”,而目前Docker运行时只能支持amd64的处理器架构。第二个工作是:检测Linux内核版本是否满足要求,而目前Docker Daemon运行所需的内核版本若过低,则必须升级至3.8.0。
4.3. 配置工作路径
配置Docker Daemon的工作路径,主要是创建Docker Daemon运行中所在的工作目录。实现过程中,通过config中的Root属性来完成。在默认配置文件中,Root属性的值为”/var/lib/docker”。
在配置工作路径的代码实现中,步骤如下:
(1) 使用规范路径创建一个TempDir,路径名为tmp;
(2) 通过tmp,创建一个指向tmp的文件符号连接realTmp;
(3) 使用realTemp的值,创建并赋值给环境变量TMPDIR;
(4) 处理config的属性EnableSelinuxSupport;
(5) 将realRoot重新赋值于config.Root,并创建Docker Daemon的工作根目录。
4.4. 加载并配置graphdriver
加载并配置存储驱动graphdriver,目的在于:使得Docker Daemon创建Docker镜像管理所需的驱动环境。Graphdriver用于完成Docker容器镜像的管理,包括存储与获取。
4.4.1. 创建graphdriver
这部分内容的源码位于./docker/daemon/daemon.go#L743-L790,具体细节分析如下:
graphdriver.DefaultDriver = config.GraphDriver driver, err := graphdriver.New(config.Root, config.GraphOptions)
首先,为graphdriver包中的DefaultDriver对象赋值,值为config中的GraphDriver属性,在默认配置文件中,GraphDriver属性的值为空;同样的,属性GraphOptions也为空。然后通过graphDriver中的new函数实现加载graph的存储驱动。
创建具体的graphdriver是相当重要的一个环节,实现细节由graphdriver包中的New函数来完成。进入./docker/daemon/graphdriver/driver.go中,实现步骤如下:
第一,遍历数组选择graphdriver,数组内容为os.Getenv(“DOCKER_DRIVER”)和DefaultDriver。若不为空,则通过GetDriver函数直接返回相应的Driver对象实例,若均为空,则继续往下执行。这部分内容的作用是:让graphdriver的加载,首先满足用户的自定义选择,然后满足默认值。代码如下:
for _, name := range []string{os.Getenv("DOCKER_DRIVER"), DefaultDriver} {
if name != "" {
return GetDriver(name, root, options)
}
}
第二,遍历优先级数组选择graphdriver,优先级数组的内容为依次为”aufs”,”brtfs”,”devicemapper”和”vfs”。若依次验证时,GetDriver成功,则直接返回相应的Driver对象实例,若均不成功,则继续往下执行。这部分内容的作用是:在没有指定以及默认的Driver时,从优先级数组中选择Driver,目前优先级最高的为“aufs”。代码如下:
for _, name := range priority {
driver, err = GetDriver(name, root, options)
if err != nil {
if err == ErrNotSupported || err == ErrPrerequisites || err == ErrIncompatibleFS {
continue
}
return nil, err
}
return driver, nil
}
第三,从已经注册的drivers数组中选择graphdriver。在”aufs”,”btrfs”,”devicemapper”和”vfs”四个不同类型driver的init函数中,它们均向graphdriver的drivers数组注册了相应的初始化方法。分别位于./docker/daemon/graphdriver/aufs/aufs.go,以及其他三类driver的相应位置。这部分内容的作用是:在没有优先级drivers数组的时候,同样可以通过注册的driver来选择具体的graphdriver。
4.4.2. 验证btrfs与SELinux的兼容性
由于目前在btrfs文件系统上运行的Docker不兼容SELinux,因此当config中配置信息需要启用SELinux的支持并且driver的类型为btrfs时,返回nil对象,并报出Fatal日志。代码实现如下:
// As Docker on btrfs and SELinux are incompatible at present, error on both being enabled
if config.EnableSelinuxSupport && driver.String() == "btrfs" {
return nil, fmt.Errorf("SELinux is not supported with the BTRFS graph driver!")
}
4.4.3. 创建容器仓库目录
Docker Daemon在创建Docker容器之后,需要将容器放置于某个仓库目录下,统一管理。而这个目录即为daemonRepo,值为:/var/lib/docker/containers,并通过daemonRepo创建相应的目录。代码实现如下:
daemonRepo := path.Join(config.Root, "containers")
if err := os.MkdirAll(daemonRepo, 0700); err != nil && !os.IsExist(err) {
return nil, err
}
4.4.4. 迁移容器至aufs类型
当graphdriver的类型为aufs时,需要将现有graph的所有内容都迁移至aufs类型;若不为aufs,则继续往下执行。实现代码如下:
if err = migrateIfAufs(driver, config.Root); err != nil {
return nil, err
}
这部分的迁移内容主要包括Repositories,Images以及Containers,具体实现位于./docker/daemon/graphdriver/aufs/migrate.go。
func (a *Driver) Migrate(pth string, setupInit func(p string) error) error {
if pathExists(path.Join(pth, "graph")) {
if err := a.migrateRepositories(pth); err != nil {
return err
}
if err := a.migrateImages(path.Join(pth, "graph")); err != nil {
return err
}
return a.migrateContainers(path.Join(pth, "containers"), setupInit)
}
return nil
}
migrate repositories的功能是:在Docker Daemon的root工作目录下创建repositories-aufs的文件,存储所有与images相关的基本信息。
migrate images的主要功能是:将原有的image镜像都迁移至aufs driver能识别并使用的类型,包括aufs所规定的layers,diff与mnt目录内容。
migrate container的主要功能是:将container内部的环境使用aufs driver来进行配置,包括,创建container内部的初始层(init layer),以及创建原先container内部的其他layers。
4.4.5. 创建镜像graph
创建镜像graph的主要工作是:在文件系统中指定的root目录下,实例化一个全新的graph对象,作用为:存储所有标记的文件系统镜像,并记录镜像之间的关系。实现代码如下:
g, err := graph.NewGraph(path.Join(config.Root, "graph"), driver)
NewGraph的具体实现位于./docker/graph/graph.go,实现过程中返回的对象为Graph类型,定义如下:
type Graph struct {
Root string
idIndex *truncindex.TruncIndex
driver graphdriver.Driver
}
其中Root表示graph的工作根目录,一般为”/var/lib/docker/graph”;idIndex使得检索字符串标识符时,允许使用任意一个该字符串唯一的前缀,在这里idIndex用于通过简短有效的字符串前缀检索镜像与容器的ID;最后driver表示具体的graphdriver类型。
4.4.6. 创建volumesdriver以及volumes graph
在Docker中volume的概念是:可以从Docker宿主机上挂载到Docker容器内部的特定目录。一个volume可以被多个Docker容器挂载,从而Docker容器可以实现互相共享数据等。在实现volumes时,Docker需要使用driver来管理它,又由于volumes的管理不会像容器文件系统管理那么复杂,故Docker采用vfs驱动实现volumes的管理。代码实现如下:
volumesDriver, err := graphdriver.GetDriver("vfs", config.Root, config.GraphOptions)
volumes, err := graph.NewGraph(path.Join(config.Root, "volumes"), volumesDriver)
主要完成工作为:使用vfs创建volumesDriver;创建相应的volumes目录,并返回volumes graph对象。
4.4.7. 创建TagStore
TagStore主要是用于存储镜像的仓库列表(repository list)。代码如下:
repositories, err := graph.NewTagStore(path.Join(config.Root, "repositories-"+driver.String()), g)
NewTagStore位于./docker/graph/tags.go,TagStore的定义如下:
type TagStore struct {
path string
graph *Graph
Repositories map[string]Repository
sync.Mutex
pullingPool map[string]chan struct{}
pushingPool map[string]chan struct{}
}
需要阐述的是TagStore类型中的多个属性的含义:
- path:TagStore中记录镜像仓库的文件所在路径;
- graph:相应的Graph实例对象;
- Repositories:记录具体的镜像仓库的map数据结构;
- sync.Mutex:TagStore的互斥锁
- pullingPool :记录池,记录有哪些镜像正在被下载,若某一个镜像正在被下载,则驳回其他Docker Client发起下载该镜像的请求;
- pushingPool:记录池,记录有哪些镜像正在被上传,若某一个镜像正在被上传,则驳回其他Docker Client发起上传该镜像的请求;
4.5. 创建Docker Daemon网络环境
创建Docker Daemon运行环境的时候,创建网络环境是极为重要的一个部分,这不仅关系着容器对外的通信,同样也关系着容器间的通信。
在创建网络时,Docker Daemon是通过运行名为”init_networkdriver”的job来完成的。代码如下:
if !config.DisableNetwork {
job := eng.Job("init_networkdriver")
job.SetenvBool("EnableIptables", config.EnableIptables)
job.SetenvBool("InterContainerCommunication", config.InterContainerCommunication)
job.SetenvBool("EnableIpForward", config.EnableIpForward)
job.Setenv("BridgeIface", config.BridgeIface)
job.Setenv("BridgeIP", config.BridgeIP)
job.Setenv("DefaultBindingIP", config.DefaultIp.String())
if err := job.Run(); err != nil {
return nil, err
}
}
分析以上源码可知,通过config中的DisableNetwork属性来判断,在默认配置文件中,该属性有过定义,却没有初始值。但是在应用配置信息中处理网络功能配置的时候,将DisableNetwork属性赋值为false,故判断语句结果为真,执行相应的代码块。
首先创建名为”init_networkdriver”的job,随后为该job设置环境变量,环境变量的值如下:
- 环境变量EnableIptables,使用config.EnableIptables来赋值,为true;
- 环境变量InterContainerCommunication,使用config.InterContainerCommunication来赋值,为true;
- 环境变量EnableIpForward,使用config.EnableIpForward来赋值,值为true;
- 环境变量BridgeIface,使用config.BridgeIface来赋值,为空字符串””;
- 环境变量BridgeIP,使用config.BridgeIP来赋值,为空字符串””;
- 环境变量DefaultBindingIP,使用config.DefaultIp.String()来赋值,为”0.0.0.0”。
设置完环境变量之后,随即运行该job,由于在eng中key为”init_networkdriver”的handler,value为bridge.InitDriver函数,故执行bridge.InitDriver函数,具体的实现位于./docker/daemon/networkdriver/bridge/dirver.go,作用为:
- 获取为Docker服务的网络设备的地址;
- 创建指定IP地址的网桥;
- 启用Iptables功能并配置;
- 另外还为eng实例注册了4个Handler,如 ”allocate_interface”, ”release_interface”, ”allocate_port”,”link”。
4.5.1. 创建Docker网络设备
创建Docker网络设备,属于Docker Daemon创建网络环境的第一步,实际工作是创建名为“docker0”的网桥设备。
在InitDriver函数运行过程中,首先使用job的环境变量初始化内部变量;然后根据目前网络环境,判断是否创建docker0网桥,若Docker专属网桥已存在,则继续往下执行;否则的话,创建docker0网桥。具体实现为createBridge(bridgeIP),以及createBridgeIface(bridgeIface)。
createBridge的功能是:在host主机上启动创建指定名称网桥设备的任务,并为该网桥设备配置一个与其他设备不冲突的网络地址。而createBridgeIface通过系统调用负责创建具体实际的网桥设备,并设置MAC地址,通过libcontainer中netlink包的CreateBridge来实现。
4.5.2. 启用iptables功能
创建完网桥之后,Docker Daemon为容器以及host主机配置iptables,包括为container之间所需要的link操作提供支持,为host主机上所有的对外对内流量制定传输规则等。代码位于./docker/daemon/networkdriver/bridge/driver/driver.go#L133-L137,如下:
// Configure iptables for link support
if enableIPTables {
if err := setupIPTables(addr, icc); err != nil {
return job.Error(err)
}
}
其中setupIPtables的调用过程中,addr地址为Docker网桥的网络地址,icc为true,即为允许Docker容器间互相访问。假设网桥设备名为docker0,网桥网络地址为docker0_ip,设置iptables规则,操作步骤如下:
(1) 使用iptables工具开启新建网桥的NAT功能,使用命令如下:
iptables -I POSTROUTING -t nat -s docker0_ip ! -o docker0 -j MASQUERADE
(2) 通过icc参数,决定是否允许container间通信,并制定相应iptables的Forward链。Container之间通信,说明数据包从container内发出后,经过docker0,并且还需要在docker0处发往docker0,最终转向指定的container。换言之,从docker0出来的数据包,如果需要继续发往docker0,则说明是container的通信数据包。命令使用如下:
iptables -I FORWARD -i docker0 -o docker0 -j ACCEPT
(3) 允许接受从container发出,且不是发往其他container数据包。换言之,允许所有从docker0发出且不是继续发向docker0的数据包,使用命令如下:
iptables -I FORWARD -i docker0 ! -o docker0 -j ACCEPT
(4) 对于发往docker0,并且属于已经建立的连接的数据包,Docker无条件接受这些数据包,使用命令如下:
iptables -I FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
4.5.3. 启用系统数据包转发功能
在Linux系统上,数据包转发功能是被默认禁止的。数据包转发,就是当host主机存在多块网卡的时,如果其中一块网卡接收到数据包,并需要将其转发给另外的网卡。通过修改/proc/sys/net/ipv4/ip_forward的值,将其置为1,则可以保证系统内数据包可以实现转发功能,代码如下:
if ipForward {
// Enable IPv4 forwarding
if err := ioutil.WriteFile("/proc/sys/net/ipv4/ip_forward", []byte{'1', '\n'}, 0644); err != nil {
job.Logf("WARNING: unable to enable IPv4 forwarding: %s\n", err)
}
}
4.5.4. 创建DOCKER链
在网桥设备上创建一条名为DOCKER的链,该链的作用是在创建Docker container并设置端口映射时使用。实现代码位于./docker/daemon/networkdriver/bridge/driver/driver.go,如下:
if err := iptables.RemoveExistingChain("DOCKER"); err != nil {
return job.Error(err)
}
if enableIPTables {
chain, err := iptables.NewChain("DOCKER", bridgeIface)
if err != nil {
return job.Error(err)
}
portmapper.SetIptablesChain(chain)
}
4.5.5. 注册Handler至Engine
在创建完网桥,并配置完基本的iptables规则之后,Docker Daemon在网络方面还在Engine中注册了4个Handler,这些Handler的名称与作用如下:
- allocate_interface:为Docker container分配一个专属网卡;
- realease_interface:释放网络设备资源;
- allocate_port:为Docker container分配一个端口;
- link:实现Docker container间的link操作。
由于在Docker架构中,网络是极其重要的一部分,因此Docker网络篇会安排在《Docker源码分析》系列的第六篇。
4.6. 创建graphdb并初始化
Graphdb是一个构建在SQLite之上的图形数据库,通常用来记录节点命名以及节点之间的关联。Docker Daemon使用graphdb来记录镜像之间的关联。创建graphdb的代码如下:
graphdbPath := path.Join(config.Root, "linkgraph.db")
graph, err := graphdb.NewSqliteConn(graphdbPath)
if err != nil {
return nil, err
}
以上代码首先确定graphdb的目录为/var/lib/docker/linkgraph.db;随后通过graphdb包内的NewSqliteConn打开graphdb,使用的驱动为”sqlite3”,数据源的名称为” /var/lib/docker/linkgraph.db”;最后通过NewDatabase函数初始化整个graphdb,为graphdb创建entity表,edge表,并在这两个表中初始化部分数据。NewSqliteConn函数的实现位于./docker/pkg/graphdb/conn_sqlite3.go,代码实现如下:
func NewSqliteConn(root string) (*Database, error) {
……
conn, err := sql.Open("sqlite3", root)
……
return NewDatabase(conn, initDatabase)
}
4.7. 创建execdriver
Execdriver是Docker中用来执行Docker container任务的驱动。创建并初始化graphdb之后,Docker Daemon随即创建了execdriver,具体代码如下:
ed, err := execdrivers.NewDriver(config.ExecDriver, config.Root, sysInitPath, sysInfo)
可见,在创建execdriver的时候,需要4部分的信息,以下简要介绍这4部分信息:
- config.ExecDriver:Docker运行时中指定使用的exec驱动类别,在默认配置文件中默认使用”native”,也可以将这个值改为”lxc”,则使用lxc接口执行Docker container内部的操作;
- config.Root:Docker运行时的root路径,默认配置文件中为”/var/lib/docker”;
- sysInitPath:系统上存放dockerinit二进制文件的路径,一般为”/var/lib/docker/init/dockerinit-1.2.0”;
- sysInfo:系统功能信息,包括:容器的内存限制功能,交换区内存限制功能,数据转发功能,以及AppArmor安全功能等。
在执行execdrivers.NewDriver之前,首先通过以下代码,获取期望的目标dockerinit文件的路径localPath,以及系统中dockerinit文件实际所在的路径sysInitPath:
localCopy := path.Join(config.Root, "init", fmt.Sprintf("
dockerinit-%s", dockerversion.VERSION))
sysInitPath := utils.DockerInitPath(localCopy)
通过执行以上代码,localCopy为”/var/lib/docker/init/dockerinit-1.2.0”,而sysyInitPath为当前Docker运行时中dockerinit-1.2.0实际所处的路径,utils.DockerInitPath的实现位于 ./docker/utils/util.go。若localCopy与sysyInitPath不相等,则说明当前系统中的dockerinit二进制文件,不在localCopy路径下,需要将其拷贝至localCopy下,并对该文件设定权限。
设定完dockerinit二进制文件的位置之后,Docker Daemon创建sysinfo对象,记录系统的功能属性。SysInfo的定义,位于./docker/pkg/sysinfo/sysinfo.go,如下:
type SysInfo struct {
MemoryLimit bool
SwapLimit bool
IPv4ForwardingDisabled bool
AppArmor bool
}
其中MemoryLimit通过判断cgroups文件系统挂载路径下是否均存在memory.limit_in_bytes和memory.soft_limit_in_bytes文件来赋值,若均存在,则置为true,否则置为false。SwapLimit通过判断memory.memsw.limit_in_bytes文件来赋值,若该文件存在,则置为true,否则置为false。AppArmor通过host主机是否存在/sys/kernel/security/apparmor来判断,若存在,则置为true,否则置为false。
执行execdrivers.NewDriver时,返回execdriver.Driver对象实例,具体代码实现位于 ./docker/daemon/execdriver/execdrivers/execdrivers.go,由于选择使用native作为exec驱动,故执行以下的代码,返回最终的execdriver,其中native.NewDriver实现位于./docker/daemon/execdriver/native/driver.go:
return native.NewDriver(path.Join(root, “execdriver”, “native”), initPath)
至此,已经创建完毕一个execdriver的实例ed。
—————————
Docker Daemon网络
————————–
创建网络环境的步骤为:
(1) 创建名为”init_networkdriver”的job;
(2) 为该job配置环境变量,设置的环境变量有EnableIptables、InterContainerCommunication、EnableIpForward、BridgeIface、BridgeIP以及DefaultBindingIP;
(3) 运行job。
运行”init_network”即为创建Docker网桥,这部分内容将会在下一节详细分析。
若DisableNetwork为true。则说明不需要创建网络环境,网络模式属于none模式。
createBridge函数实现过程的主要步骤为:
(1) 确定网桥设备docker0的IP地址;
(2) 通过createBridgeIface函数创建docker0网桥设备,并为网桥设备分配随机的MAC地址;
(3) 将第一步中已经确定的IP地址,添加给新创建的docker0网桥设备;
(4) 启动docker0网桥设备。
namespace主要负责命名空间的隔离,而cgroup主要负责资源使用的限制。其实,正是这两个神奇的内核特性联合使用,才保证了Docker Container的“隔离”。那么,namespace和cgroup又和进程有什么关系呢?问题的答案可以用以下的次序来说明:
(1) 父进程通过fork创建子进程时,使用namespace技术,实现子进程与其他进程(包含父进程)的命名空间隔离;
(2) 子进程创建完毕之后,使用cgroup技术来处理子进程,实现进程的资源使用限制;
(3) 系统在子进程所处namespace内部,创建需要的隔离环境,如隔离的网络栈等;
(4) namespace和cgroup两种技术都用上之后,进程所处的“隔离”环境才真正建立,这时“容器”才真正诞生!
Docker Container网络分析内容安排
Docker Container网络篇将从源码的角度,分析Docker Container从无到有的过程中,Docker Container网络创建的来龙去脉。Docker Container网络创建流程可以简化如下图:

图2.1 Docker Container网络创建流程图
Docker Container网络篇分析的主要内容有以下5部分:
(1) Docker Container的网络模式;
(2) Docker Client配置容器网络;
(3) Docker Daemon创建容器网络流程;
(4) execdriver网络执行流程;
(5) libcontainer实现内核态网络配置。
Docker Container网络创建过程中,networkdriver模块使用并非是重点,故分析内容中不涉及networkdriver。这里不少读者肯定会有疑惑。需要强调的是,networkdriver在Docker中的作用:第一,为Docker Daemon创建网络环境的时候,初始化Docker Daemon的网络环境(详情可以查看《Docker源码分析》系列第六篇),比如创建docker0网桥等;第二,为Docker Container分配IP地址,为Docker Container做端口映射等。而与Docker Container网络创建有关的内容极少,只有在桥接模式下,为Docker Container的网络接口设备分配一个可用IP地址。
本文为《Docker源码分析》系列第七篇——Docker Container网络(上)。
3.Docker Container网络模式
正如在上文提到的,Docker可以为Docker Container创建隔离的网络环境,在隔离的网络环境下,Docker Container独立使用私有网络。相信很多的Docker开发者也是体验过Docker这方面的网络特性。
其实,Docker除了可以为Docker Container创建隔离的网络环境之外,同样有能力为Docker Container创建共享的网络环境。换言之,当开发者需要Docker Container与宿主机或者其他容器网络隔离时,Docker可以满足这样的需求;而当开发者需要Docker Container与宿主机或者其他容器共享网络时,Docker同样可以满足这样的需求。另外,Docker还可以不为Docker Container创建网络环境。
总结Docker Container的网络,可以得出4种不同的模式:bridge桥接模式、host模式、other container模式和none模式。
bridge
外界访问Docker Container内部服务的流程为:
(1) 外界访问宿主机的IP以及宿主机的端口port_1;
(2) 当宿主机接收到这样的请求之后,由于DNAT规则的存在,会将该请求的目的IP(宿主机eth0的IP)和目的端口port_1进行转换,转换为容器IP和容器的端口port_0;
(3) 由于宿主机认识容器IP,故可以将请求发送给veth pair;
(4) veth pair的veth0将请求发送至容器内部的eth0,最终交给内部服务进行处理。
使用DNAT方法,可以使得Docker宿主机以外的世界主动访问Docker Container内部服务。那么Docker Container如何访问宿主机以外的世界呢。以下简要分析Docker Container访问宿主机以外世界的流程:
(1) Docker Container内部进程获悉宿主机以外服务的IP地址和端口port_2,于是Docker Container发起请求。容器的独立网络环境保证了请求中报文的源IP地址为容器IP(即容器内部eth0),另外Linux内核会自动为进程分配一个可用源端口(假设为port_3);
(2) 请求通过容器内部eth0发送至veth pair的另一端,到达veth0,也就是到达了网桥(docker0)处;
(3) docker0网桥开启了数据报转发功能(/proc/sys/net/ipv4/ip_forward),故将请求发送至宿主机的eth0处;
(4) 宿主机处理请求时,使用SNAT对请求进行源地址IP转换,即将请求中源地址IP(容器IP地址)转换为宿主机eth0的IP地址;
(5) 宿主机将经过SNAT转换后的报文通过请求的目的IP地址(宿主机以外世界的IP地址)发送至外界
在这里,很多人肯定会问:对于Docker Container内部主动发起对外的网络请求,当请求到达宿主机进行SNAT处理后发给外界,当外界响应请求时,响应报文中的目的IP地址肯定是Docker宿主机的IP地址,那响应报文回到宿主机的时候,宿主机又是如何转给Docker Container的呢?关于这样的响应,由于port_3端口并没有在宿主机上做相应的DNAT转换,原则上不会被发送至容器内部。为什么说对于这样的响应,不会做DNAT转换呢。原因很简单,DNAT转换是针对容器内部服务监听的特定端口做的,该端口是供服务监听使用,而容器内部发起的请求报文中,源端口号肯定不会占用服务监听的端口,故容器内部发起请求的响应不会在宿主机上经过DNAT处理。
其实,这一环节的内容是由iptables规则来完成,具体的iptables规则如下:
iptables -I FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
这条规则的意思是,在宿主机上发往docker0网桥的网络数据报文,如果是该数据报文所处的连接已经建立的话,则无条件接受,并由Linux内核将其发送到原来的连接上,即回到Docker Container内部。
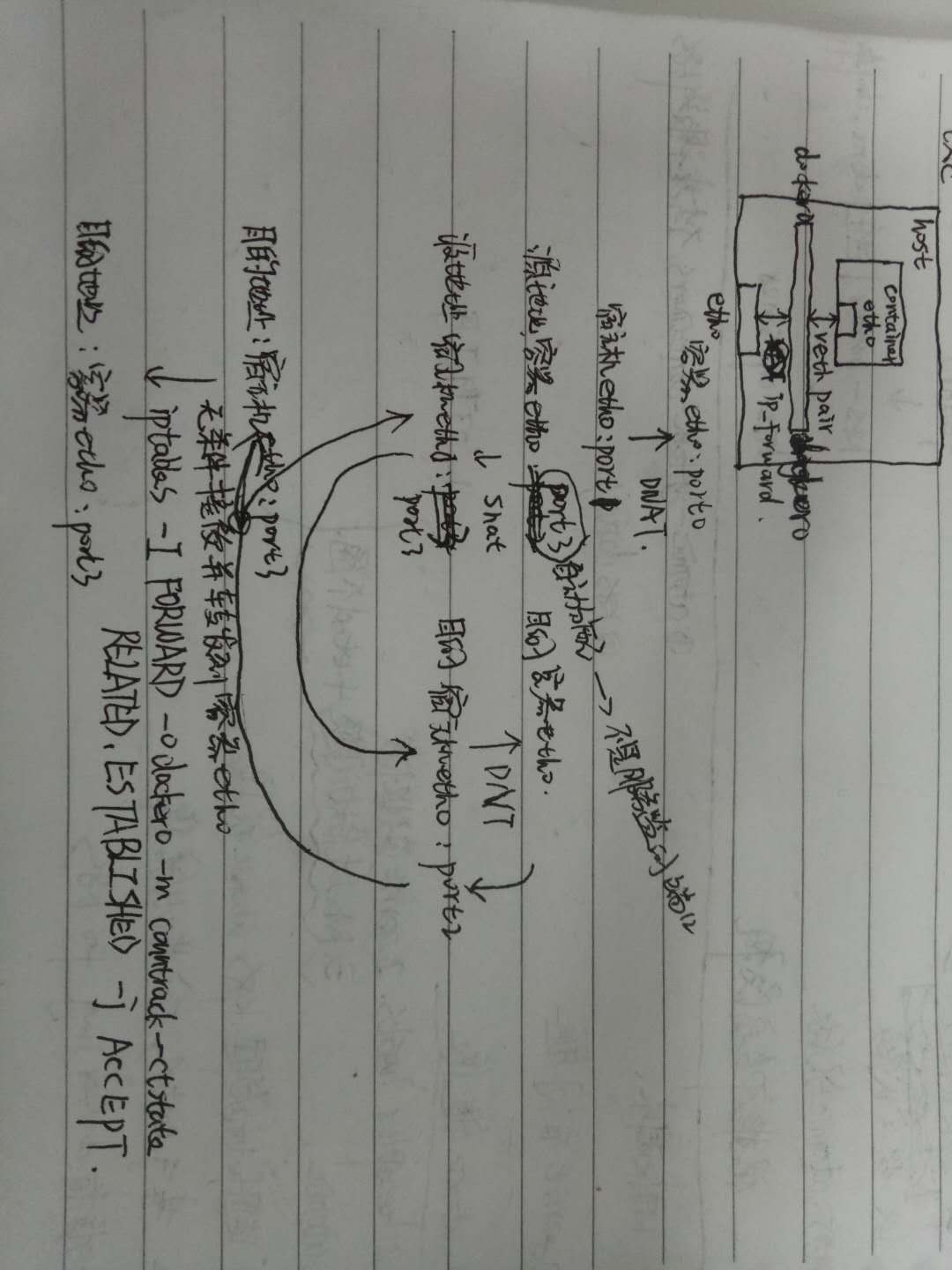
以上便是Docker Container中bridge桥接模式的简要介绍。可以说,bridger桥接模式从功能的角度实现了两个方面:第一,让容器拥有独立、隔离的网络栈;第二,让容器和宿主机以外的世界通过NAT建立通信。
然而,bridge桥接模式下的Docker Container在使用时,并非为开发者包办了一切。最明显的是,该模式下Docker Container不具有一个公有IP,即和宿主机的eth0不处于同一个网段。导致的结果是宿主机以外的世界不能直接和容器进行通信。虽然NAT模式经过中间处理实现了这一点,但是NAT模式仍然存在问题与不便,如:容器均需要在宿主机上竞争端口,容器内部服务的访问者需要使用服务发现获知服务的外部端口等。另外NAT模式由于是在三层网络上的实现手段,故肯定会影响网络的传输效率。
使用host模式的Docker Container虽然可以让容器内部的服务和传统情况无差别、无改造的使用,但是由于网络隔离性的弱化,该容器会与宿主机共享竞争网络栈的使用;另外,容器内部将不再拥有所有的端口资源,原因是部分端口资源已经被宿主机本身的服务占用,还有部分端口已经用以bridge网络模式容器的端口映射。
Docker Container的other container网络模式在实现过程中,不涉及网桥,同样也不需要创建虚拟网卡veth pair。完成other container网络模式的创建只需要两个步骤:
(1) 查找other container(即需要被共享网络环境的容器)的网络namespace;
(2) 将新创建的Docker Container(也是需要共享其他网络的容器)的namespace,使用other container的namespace。
Docker Container的other container网络模式,可以用来更好的服务于容器间的通信。
在这种模式下的Docker Container可以通过localhost来访问namespace下的其他容器,传输效率较高。虽然多个容器共享网络环境,但是多个容器形成的整体依然与宿主机以及其他容器形成网络隔离。另外,这种模式还节约了一定数量的网络资源。但是需要注意的是,它并没有改善容器与宿主机以外世界通信的情况。
Docker目前支持4种网络模式,分别是bridge、host、container、none,Docker开发者可以根据自己的需求来确定最适合自己应用场景的网络模式。
2.1创建容器并配置网络参数
Docker Daemon首先接收并处理create container请求。需要注意的是:create container并非创建了一个运行的容器,而是完成了以下三个主要的工作:
- 通过runconfig包解析出create container请求中与Docker Container息息相关的config对象;
- 在Docker Daemon内部创建了与Docker Container对应的container对象;
- 完成Docker Container启动前的准备化工作,如准备所需镜像、创建rootfs等。
Start函数执行过程中,与Docker Container网络模式相关的部分主要有三部分:
- initializeNetwork(),初始化container对象中与网络相关的属性;
- populateCommand,填充Docker Container内部需要执行的命令,Command中含有进程启动命令,还含有容器环境的配置信息,也包括网络配置;
- container.waitForStart(),实现Docker Container内部进程的启动,进程启动之后,为进程创建网络环境等。
execdriver网络执行流程
Docker架构中execdriver的作用是启动容器内部进程,最终启动容器。目前,在Docker中execdriver作为执行驱动,可以有两种选项:lxc与native。其中,lxc驱动会调用lxc工具实现容器的启动,而native驱动会使用Docker官方发布的libcontainer来启动容器。
Docker Daemon启动过程中,execdriver的类型默认为native,故本文主要分析native驱动在执行启动容器时,如何处理网络部分。
在Docker Daemon启动容器的最后一步,即调用了execdriver的Run函数来执行。通过分析Run函数的具体实现,关于Docker Container的网络执行流程主要包括两个环节:
(1) 创建libcontainer的Config对象
(2) 通过libcontainer中的namespaces包执行启动容器
将execdriver.Run函数的运行流程具体展开,与Docker Container网络相关的流程,可以得到以下示意图:

图3.1 execdriver.Run执行流程图
1.前言
回首过去的2014年,大家可以看到Docker在全球刮起了一阵又一阵的“容器风”,工业界对Docker的探索与实践更是一波高过一波。在如今的2015年以及未来,Docker似乎并不会像其他昙花一现的技术一样,在历史的舞台上热潮褪去,反而在工业界实践与评估之后,显现了前所未有的发展潜力。
究其本质,“Docker提供容器服务”这句话,相信很少有人会有异议。那么,既然Docker提供的服务属于“容器”技术,那么反观“容器”技术的本质与历史,我们又可以发现什么呢?正如前文所提到的,Docker使用的“容器”技术,主要是以Linux的cgroup、namespace等内核特性为基础,保障进程或者进程组处于一个隔离、安全的环境。Docker发行第一个版本是在2013年的3月,而cgroup的正式亮相可以追溯到2007年下半年,当时cgroup被合并至Linux内核2.6.24版本。期间6年时间,并不是“容器”技术发展的真空期,2008年LXC(Linux Container)诞生,其简化了容器的创建与管理;之后业界一些PaaS平台也初步尝试采用容器技术作为其云应用的运行环境;而与Docker发布同年,Google也发布了开源容器管理工具lmctfy。除此之外,若抛开Linux操作系统,其他操作系统如FreeBSD、Solaris等,同样诞生了作用相类似的“容器”技术,其发展历史更是需要追溯至千禧年初期。
可见,“容器”技术的发展不可谓短暂,然而论同时代的影响力,却鲜有Docker的媲美者。不论是云计算大潮催生了Docker技术,抑或是Docker技术赶上了云计算的大时代,毋庸置疑的是,Docker作为领域内的新宠儿,必然会继续受到业界的广泛青睐。云计算时代,分布式应用逐渐流行,并对其自身的构建、交付与运行有着与传统不一样的要求。借助Linux内核的cgroup与namespace特性,自然可以做到应用运行环境的资源隔离与应用部署的快速等;然而,cgroup和namespace等内核特性却无法为容器的运行环境做全盘打包。而Docker的设计则很好得考虑到了这一点,除cgroup和namespace之外,另外采用了神奇的“镜像”技术作为Docker管理文件系统以及运行环境的强有力补充。Docker灵活的“镜像”技术,在笔者看来,也是其大红大紫最重要的因素之一。
2.Docker镜像介绍
大家看到这,第一个问题肯定是“什么是Docker镜像”?
据Docker官网的技术文档描述,Image(镜像)是Docker术语的一种,代表一个只读的layer。而layer则具体代表Docker Container文件系统中可叠加的一部分。
笔者如此介绍Docker镜像,相信众多Docker爱好者理解起来依旧是云里雾里。那么理解之前,先让我们来认识一下与Docker镜像相关的4个概念:rootfs、Union mount、image以及layer。
2.1 rootfs
相关赞助商

Rootfs:代表一个Docker Container在启动时(而非运行后)其内部进程可见的文件系统视角,或者是Docker Container的根目录。当然,该目录下含有Docker Container所需要的系统文件、工具、容器文件等。
传统来说,Linux操作系统内核启动时,内核首先会挂载一个只读(read-only)的rootfs,当系统检测其完整性之后,决定是否将其切换为读写(read-write)模式,或者最后在rootfs之上另行挂载一种文件系统并忽略rootfs。Docker架构下,依然沿用Linux中rootfs的思想。当Docker Daemon为Docker Container挂载rootfs的时候,与传统Linux内核类似,将其设定为只读(read-only)模式。在rootfs挂载完毕之后,和Linux内核不一样的是,Docker Daemon没有将Docker Container的文件系统设为读写(read-write)模式,而是利用Union mount的技术,在这个只读的rootfs之上再挂载一个读写(read-write)的文件系统,挂载时该读写(read-write)文件系统内空无一物。
举一个Ubuntu容器启动的例子。假设用户已经通过Docker Registry下拉了Ubuntu:14.04的镜像,并通过命令docker run –it ubuntu:14.04 /bin/bash将其启动运行。则Docker Daemon为其创建的rootfs以及容器可读写的文件系统可参见图2.1:

图2.1 Ubuntu 14.04容器rootfs示意图
正如read-only和read-write的含义那样,该容器中的进程对rootfs中的内容只拥有读权限,对于read-write读写文件系统中的内容既拥有读权限也拥有写权限。通过观察图2.1可以发现:容器虽然只有一个文件系统,但该文件系统由“两层”组成,分别为读写文件系统和只读文件系统。这样的理解已然有些层级(layer)的意味。
简单来讲,可以将Docker Container的文件系统分为两部分,而上文提到是Docker Daemon利用Union Mount的技术,将两者挂载。那么Union mount又是一种怎样的技术?
2.2 Union mount
Union mount:代表一种文件系统挂载的方式,允许同一时刻多种文件系统挂载在一起,并以一种文件系统的形式,呈现多种文件系统内容合并后的目录。
一般情况下,通过某种文件系统挂载内容至挂载点的话,挂载点目录中原先的内容将会被隐藏。而Union mount则不会将挂载点目录中的内容隐藏,反而是将挂载点目录中的内容和被挂载的内容合并,并为合并后的内容提供一个统一独立的文件系统视角。通常来讲,被合并的文件系统中只有一个会以读写(read-write)模式挂载,而其他的文件系统的挂载模式均为只读(read-only)。实现这种Union mount技术的文件系统一般被称为Union Filesystem,较为常见的有UnionFS、AUFS、OverlayFS等。
Docker Daemon对于镜像下载job的执行,涉及的内容较多:首先解析job参数,获取Docker镜像的repository、tag、Docker Registry信息等;随后与Docker Registry建立session;然后通过session下载Docker镜像;接着将Docker镜像下载至本地并存储于graph;最后在TagStore标记该镜像。
pullRepository函数包含了镜像下载整个流程的林林总总,该流程可以参见图6.1:

图6.1 pullRepository流程图
关于上图的各个环节,下表给出简要的功能介绍:
表6.2 pullRepository各环节功能介绍表
|
函数名称 |
功能介绍 |
|
r.GetRepositoryData() |
获取指定repository中所有image的id信息 |
|
r.GetRemoteTags() |
获取指定repository中所有的tag信息 |
|
r.pullImage() |
从Docker Registry下载Docker镜像 |
|
r.GetRemoteHistory() |
获取指定image所有祖先image id信息 |
|
r.GetRemoteImageJSON() |
获取指定image的json信息 |
|
r.GetRemoteImageLayer() |
获取指定image的layer信息 |
|
s.graph.Register() |
将下载的镜像在TagStore的graph中注册 |
|
s.Set() |
在TagStore中添加新下载的镜像信息 |
分析pullRepository的整个流程之前,很有必要了解下pullRepository函数调用者的类型TagStore。TagStore是Docker镜像方面涵盖内容最多的数据结构:一方面TagStore管理Docker的Graph,另一方面TagStore还管理Docker的repository记录。除此之外,TagStore还管理着上文提到的对象pullingPool以及pushingPool,保证Docker Daemon在同一时刻,只为一个Docker Client执行同一镜像的下载或上传。TagStore结构体的定义位于./docker/graph/tags.go#L20-L29,如下:
type TagStore struct {
path string
graph *Graph
Repositories map[string]Repository
sync.Mutex
// FIXME: move push/pull-related fields
// to a helper type
pullingPool map[string]chan struct{}
pushingPool map[string]chan struct{}
}
以下将重点分析pullRepository的整个流程。
6.3.1 GetRepositoryData
使用Docker下载镜像时,用户往往指定的是Docker镜像的名称,如:请求docker pull ubuntu:14.04中镜像名称为ubuntu。GetRepositoryData的作用则是获取镜像名称所在repository中所有image的 id信息。
GetRepositoryData的源码实现位于./docker/registry/session.go#L255-L324。获取repository中image的ID信息的目标URL地址如以下源码:
repositoryTarget := fmt.Sprintf("%srepositories/%s/images", indexEp, remote)
因此,docker pull ubuntu:14.04请求被执行时,repository的目标URL地址为https://index.docker.io/v1/repositories/ubuntu/images,访问该URL可以获得有关ubuntu这个repository中所有image的 id信息,部分image的id信息如下:
[{"checksum": "", "id": "
2427658c75a1e3d0af0e7272317a8abfaee4c15729b6840e3c2fca342fe47bf1"},
{"checksum": "", "id":
"81fbd8fa918a14f4ebad9728df6785c537218279081c7a120d72399d3a5c94a5"
}, {"checksum": "", "id":
"ec69e8fd6b0236b67227869b6d6d119f033221dd0f01e0f569518edabef3b72c"
}, {"checksum": "", "id":
"9e8dc15b6d327eaac00e37de743865f45bee3e0ae763791a34b61e206dd5222e"
}, {"checksum": "", "id":
"78949b1e1cfdcd5db413c300023b178fc4b59c0e417221c0eb2ffbbd1a4725cc"
},……]
获取以上信息之后,Docker Daemon通过RepositoryData和ImgData类型对象来存储ubuntu这个repository中所有image的信息,RepositoryData和ImgData的数据结构关系如图6.2:

图6.2 RepositoryData和ImgData的数据结构关系图
GetRepositoryData执行过程中,会为指定repository中的每一个image创建一个ImgData对象,并最终将所有ImgData存放在RepositoryData的ImgList属性中,ImgList的类型为map,key为image的ID,value指向ImgData对象。此时ImgData对象中只有属性ID与Checksum有内容。
6.3.2 GetRemoteTags
使用Docker下载镜像时,用户除了指定Docker镜像的名称之外,一般还需要指定Docker镜像的tag,如:请求docker pull ubuntu:14.04中镜像名称为ubuntu,镜像tag为14.04,假设用户不显性指定tag,则默认tag为latest。GetRemoteTags的作用则是获取镜像名称所在repository中所有tag的信息。
GetRemoteTags的源码实现位于./docker/registry/session.go#L195-234。获取repository中所有tag信息的目标URL地址如以下源码:
endpoint := fmt.Sprintf("%srepositories/%s/tags", host, repository)
获取指定repository中所有tag信息之后,Docker Daemon根据tag对应layer的ID,找到ImgData,并对填充ImgData中的Tag属性。此时,RepositoryData的ImgList属性中,有的ImgData对象有Tag内容,有的ImgData对象中没有Tag内容。这也和实际情况相符,如下载一个ubuntu:14.04镜像,该镜像的rootfs中只有最上层的layer才有tag信息,这一层layer的parent Image并不一定存在tag信息。
6.3.3 pullImage
Docker Daemon下载Docker镜像时是通过image id来完成。GetRepositoryData和GetRemoteTags则成功完成了用户传入的repository和tag信息与image id的转换。如请求docker pull ubuntu:14.04中,repository为ubuntu,tag为14.04,则对应的image id为2d24f826。
Docker Daemon获得下载镜像的image id之后,首先查验pullingPool,判断是否有其他Docker Client同样发起了该镜像的下载请求,如果没有的话Docker Daemon才继续下载任务。
执行pullImage函数的源码实现位于./docker/graph/pull.go#L159,如下:
s.pullImage(r, out, img.ID, ep, repoData.Tokens, sf)
而pullImage函数的定义位于./docker/graph/pull.go#L214-L301。图6.1中,可以看到pullImage函数的执行可以分为4个步骤:GetRemoteHistory、GetRemoteImageJson、GetRemoteImageLayer与s.graph.Register()。
GetRemoteHistory的作用很好理解,既然Docker Daemon已经通过GetRepositoryData和GetRemoteTags找出了指定tag的image id,那么Docker Daemon所需完成的工作为下载该image 及其所有的祖先image。GetRemoteHistory正是用于获取指定image及其所有祖先iamge的id。
GetRemoteHistory的源码实现位于./docker/registry/session.go#L72-L101。
获取所有的image id之后,对于每一个image id,Docker Daemon都开始下载该image的全部内容。Docker Image的全部内容包括两个方面:image json信息以及image layer信息。Docker所有image的json信息都由函数GetRemoteImageJSON来完成。分析GetRemoteImageJSON之前,有必要阐述清楚什么是Docker Image的json信息。
Docker Image的json信息是一个非常重要的概念。这部分json唯一的标志了一个image,不仅标志了image的id,同时也标志了image所在layer对应的config配置信息。理解以上内容,可以举一个例子:docker build。命令docker build用以通过指定的Dockerfile来创建一个Docker镜像;对于Dockerfile中所有的命令,Docker Daemon都会为其创建一个新的image,如:RUN apt-get update, ENV path=/bin, WORKDIR /home等。对于命令RUN apt-get update,Docker Daemon需要执行apt-get update操作,对应的rootfs上必定会有内容更新,导致新建的image所代表的layer中有新添加的内容。而如ENV path=/bin, WORKDIR /home这样的命令,仅仅是配置了一些容器运行的参数,并没有镜像内容的更新,对于这种情况,Docker Daemon同样创建一层新的layer,并且这层新的layer中内容为空,而命令内容会在这层image的json信息中做更新。总结而言,可以认为Docker的image包含两部分内容:image的json信息、layer内容。当layer内容为空时,image的json信息被更新。
清楚了Docker image的json信息之后,理解GetRemoteImageJSON函数的作用就变得十分容易。GetRemoteImageJSON的执行代码位于./docker/graph/pull.go#L243,如下:
imgJSON, imgSize, err = r.GetRemoteImageJSON(id, endpoint, token)
GetRemoteImageJSON返回的两个对象imgJSON代表image的json信息,imgSize代表镜像的大小。通过imgJSON对象,Docker Daemon立即创建一个image对象,创建image对象的源码实现位于./docker/graph/pull.go#L251,如下:
img, err = image.NewImgJSON(imgJSON)
而NewImgJSON函数位于包image中,函数返回类型为一个Image对象,而Image类型的定义而下:
type Image struct {
ID string `json:"id"`
Parent string `json:"parent,omitempty"`
Comment string `json:"comment,omitempty"`
Created time.Time `json:"created"`
Container string `json:"container,omitempty"`
ContainerConfig runconfig.Config `json:"container_config,omitempty"`
DockerVersion string `json:"docker_version,omitempty"`
Author string `json:"author,omitempty"`
Config *runconfig.Config `json:"config,omitempty"`
Architecture string `json:"architecture,omitempty"`
OS string `json:"os,omitempty"`
Size int64
graph Graph
}
返回img对象,则说明关于该image的所有元数据已经保存完毕,由于还缺少image的layer中包含的内容,因此下一个步骤即为下载镜像layer的内容,调用函数为GetRemoteImageLayer,函数执行位于./docker/graph/pull.go#L270,如下:
layer, err := r.GetRemoteImageLayer(img.ID, endpoint, token, int64(imgSize))
GetRemoteImageLayer函数返回当前image的layer内容。Image的layer内容指的是:该image在parent image之上做的文件系统内容更新,包括文件的增添、删除、修改等。至此,image的json信息以及layer内容均被Docker Daemon获取,意味着一个完整的image已经下载完毕。下载image完毕之后,并不意味着Docker Daemon关于Docker镜像下载的job就此结束,Docker Daemon仍然需要对下载的image进行存储管理,以便Docker Daemon在执行其他如创建容器等job时,能够方便使用这些image。
Docker Daemon在graph中注册image的源码实现位于./docker/graph/pull.go#L283-L285,如下:
err = s.graph.Register(imgJSON,utils.ProgressReader(layer, imgSize, out, sf, false, utils.TruncateID(id), "Downloading"),img)
Docker Daemon通过graph存储image是一个很重要的环节。Docker在1.2.0版本中可以通过AUFS、DevMapper以及BTRFS来进行image的存储。在Linux 3.18-rc2版本中,OverlayFS已经被内核合并,故从1.4.0版本开始,Docker 的image支持OverlayFS的存储方式。
Docker镜像的存储在Docker中是较为独立且重要的内容,故将在《Docker源码分析》系列的第十一篇专文分析。
6.3.4 配置TagStore
Docker镜像下载完毕之后,Docker Daemon需要在TagStore中指定的repository中添加相应的tag。每当用户查看本地镜像时,都可以从TagStore的repository中查看所有含有tag信息的image。
Docker Daemon配置TagStore的源码实现位于./docker/graph/pull.go#L206,如下:
if err := s.Set(localName, tag, id, true); err != nil {
return err
}
TagStore类型的Set函数定义位于./docker/graph/tags.go#L174-L205。Set函数的指定流程与简要介绍如图6.3:

图6.3 TagStore中Set函数执行流程图
当Docker Daemon将已下载的Docker镜像信息同步到repository之后,Docker下载镜像的job就全部完成,Docker Daemon返回响应至Docker Server,Docker Server返回相应至Docker Client。注:本地的repository文件位于Docker的根目录,根目录一般为/var/lib/docker,如果使用aufs的graphdriver,则repository文件名为repositories-aufs。
Docker Daemon执行镜像下载任务时,从Docker Registry处下载指定镜像之后,仍需要将镜像合理地存储于宿主机的文件系统中。更为具体而言,存储工作分为两个部分:
(1) 存储镜像内容;
(2) 在graph中注册镜像信息。
说到镜像内容,需要强调的是,每一层layer的Docker Image内容都可以认为有两个部分组成:镜像中每一层layer中存储的文件系统内容,这部分内容一般可以认为是未来Docker容器的静态文件内容;另一部分内容指的是容器的json文件,json文件代表的信息除了容器的基本属性信息之外,还包括未来容器运行时的动态信息,包括ENV等信息。
存储镜像内容,意味着Docker Daemon所在宿主机上已经存在镜像的所有内容,除此之外,Docker Daemon仍需要对所存储的镜像进行统计备案,以便用户在后续的镜像管理与使用过程中,可以有据可循。为此,Docker Daemon设计了graph,使用graph来接管这部分的工作。graph负责记录有哪些镜像已经被正确存储,供Docker Daemon调用。
本地存储:
registry:v1
_index_images, json是固有的,而后面四个是因为每提交一个tag的版本便产生两个对应的文件。其中,tag_14.04保存的是id号,tag14.04_json保存的是元数据信息;_index_images是该镜像相关的所有layer层的索引,json保存该镜像的原数据。
registry:v2(distribution)
针对每次push的镜像都有一个单独的目录,比如有ubuntu目录,证明用户上传过ubuntu镜像,再进入ubuntu目录,发现有三个目录