
一、数组、链表
Java中,ArrayList、LinkedList就是分别用数组和链表做内部实现的。
数组将元素在内存中连续存放,由于每个元素占用内存大小相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想删除一个元素,同样需要移动大量元素去填掉被移动的元素。如果应用需要快速访问数据,很少或不插入和删除元素,就应该用数组。
链表恰好相反,链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。比如:上一个元素有个指针(地址)指到下一个元素,以此类推,直到最后一个元素。如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素为止。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表数据结构了。
二、Java中的hashCode和equals
1、关于hashCode
- hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的
- 如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同
- 如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点
- 两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们“存放在同一个篮子里“
再归纳一下就是hashCode是用于查找使用的,而equals是用于比较两个对象的是否相等的。
以下对hashCode的解读摘自其他博客:
1.hashcode是用来查找的,如果你学过数据结构就应该知道,在查找和排序这一章有
例如内存中有这样的位置
0 1 2 3 4 5 6 7
而我有个类,这个类有个字段叫ID,我要把这个类存放在以上8个位置之一,如果不用hashcode而任意存放,那么当查找时就需要到这八个位置里挨个去找,或者用二分法一类的算法。
但如果用hashcode那就会使效率提高很多。
我们这个类中有个字段叫ID,那么我们就定义我们的hashcode为ID%8,然后把我们的类存放在取得得余数那个位置。比如我们的ID为9,9除8的余数为1,那么我们就把该类存在1这个位置,如果ID是13,求得的余数是5,那么我们就把该类放在5这个位置。这样,以后在查找该类时就可以通过ID除 8求余数直接找到存放的位置了。
2.但是如果两个类有相同的hashcode怎么办那(我们假设上面的类的ID不是唯一的),例如9除以8和17除以8的余数都是1,那么这是不是合法的,回答是:可以这样。那么如何判断呢?在这个时候就需要定义 equals了。
也就是说,我们先通过 hashcode来判断两个类是否存放某个桶里,但这个桶里可能有很多类,那么我们就需要再通过 equals 来在这个桶里找到我们要的类。
那么。重写了equals(),为什么还要重写hashCode()呢?
想想,你要在一个桶里找东西,你必须先要找到这个桶啊,你不通过重写hashcode()来找到桶,光重写equals()有什么用啊
2、关于equals
1.equals和==
==用于比较引用和比较基本数据类型时具有不同的功能:
比较基本数据类型,如果两个值相同,则结果为true
而在比较引用时,如果引用指向内存中的同一对象,结果为true;
equals()作为方法,实现对象的比较。由于==运算符不允许我们进行覆盖,也就是说它限制了我们的表达。因此我们复写equals()方法,达到比较对象内容是否相同的目的。而这些通过==运算符是做不到的。
2.object类的equals()方法的比较规则为:如果两个对象的类型一致,并且内容一致,则返回true,这些类有:
java.io.file,java.util.Date,java.lang.string,包装类(Integer,Double等)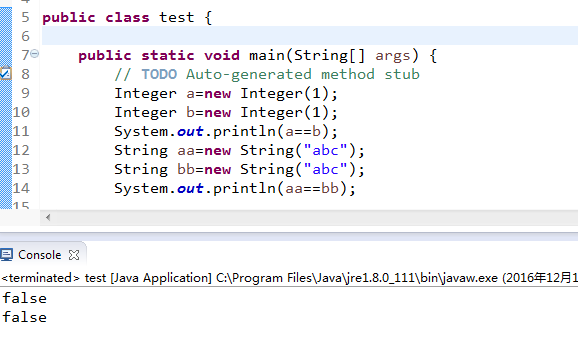
三、HashMap的实现原理
1. HashMap概述
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
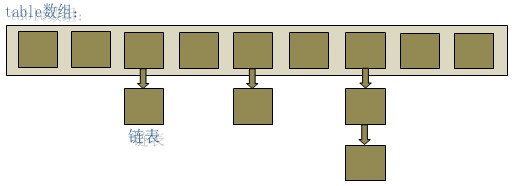
从上图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。
其中Java源码如下:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}
可以看出,Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。
2、HashMap实现存储和读取
1)存储
1 public V put(K key, V value) {
2 // HashMap允许存放null键和null值。
3 // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
4 if (key == null)
5 return putForNullKey(value);
6 // 根据key的keyCode重新计算hash值。
7 int hash = hash(key.hashCode());
8 // 搜索指定hash值在对应table中的索引。
9 int i = indexFor(hash, table.length);
10 // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
11 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
12 Object k;
13 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
14 // 如果发现已有该键值,则存储新的值,并返回原始值
15 V oldValue = e.value;
16 e.value = value;
17 e.recordAccess(this);
18 return oldValue;
19 }
20 }
21 // 如果i索引处的Entry为null,表明此处还没有Entry。
22 modCount++;
23 // 将key、value添加到i索引处。
24 addEntry(hash, key, value, i);
25 return null;
26 }

根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
hash(int h)方法根据key的hashCode重新计算一次散列。此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。
1 static int hash(int h) {
2 h ^= (h >>> 20) ^ (h >>> 12);
3 return h ^ (h >>> 7) ^ (h >>> 4);
4 }
我们可以看到在HashMap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表,这样就大大优化了查询的效率。
根据上面 put 方法的源代码可以看出,当程序试图将一个key-value对放入HashMap中时,程序首先根据该 key的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。
通过这种方式就可以高效的解决HashMap的冲突问题。
2)读取
1 public V get(Object key) {
2 if (key == null)
3 return getForNullKey();
4 int hash = hash(key.hashCode());
5 for (Entry<K,V> e = table[indexFor(hash, table.length)];
6 e != null;
7 e = e.next) {
8 Object k;
9 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
10 return e.value;
11 }
12 return null;
13 }
从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
3)归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
3、HashMap的resize(扩容)
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
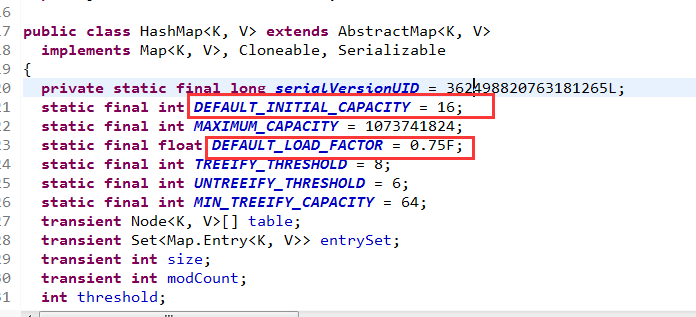
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
四、hashMap线程安全
1.HashMap线程不安全
public static final HashMap<String, String> map = new HashMap<String, String>();
public static void main(String[] args) throws InterruptedException {
//线程1
Thread t1 = new Thread(){
public void run() {
for(int i=0; i<25; i++){
map.put(String.valueOf(i), String.valueOf(i));
}
}
};
//线程2
Thread t2 = new Thread(){
public void run() {
for(int i=25; i<50; i++){
map.put(String.valueOf(i), String.valueOf(i));
}
}
};
t1.start();
t2.start();
Thread.currentThread().sleep(1000);
for(int i=0; i<50; i++){
//如果key和value不同,说明在两个线程put的过程中出现异常。
if(!String.valueOf(i).equals(map.get(String.valueOf(i)))){
System.err.println(String.valueOf(i) + ":" + map.get(String.valueOf(i)));
}
}
}HashMap源码
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
} 在hashmap做put操作的时候会调用到以上的方法。现在假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,
然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失。
2.synchronizedMap线程安全
Map m = Collections.synchronizedMap(new HashMap(…));
更好的选择:ConcurrentHashMap
java5中新增了ConcurrentMap接口和它的一个实现类ConcurrentHashMap。
ConcurrentHashMap提供了和Hashtable以及SynchronizedMap中所不同的锁机制。
Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;
而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get,put,remove等常用操作只锁当前需要用到的桶。
这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
上面说到的16个线程指的是写线程,而读操作大部分时候都不需要用到锁。只有在size等操作时才需要锁住整个hash表。
转载于:https://my.oschina.net/xiaoluobutou/blog/803687