目录
一、体验正则表达式威力
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 体验正则表达式的威力,给我们文本处理带来哪些遍历
*/
public class Regexp_ {
public static void main(String[] args) {
// String content = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来," +
// "急需一种软件技术来开发一种程序,这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为" +
// "此纷纷投入了大量的人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了" +
// "那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常小,特别适用" +
// "于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以" +
// "嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的" +
// "技术),并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列名字之后," +
// "最终,使用了提议者在喝一杯Java咖啡时无意提到的Java词语)。5月23日,Sun公司在Sun world" +
// "会议上正式发布Java和HotJava浏览器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape" +
// "和微软等各大公司都纷纷停止了自己的相关开发项目,竞相购买了Java使用许可证,并为自己的产品开" +
// "发了相应的Java平台。";
String content = "私有地址(Private address)属于非注册地址,专门为组织机构内部使用。\n" +
"以下列出留用的内部私有地址\n" +
"A类 10.0.0.0--10.255.255.255\n" +
"B类 172.16.0.0--172.31.255.255\n" +
"C类 192.168.0.0--192.168.255.255";
//(1)传统方法是使用遍历,代码量大,而且效率不高
//(2)正则表达式技术
//1.先创建Pattern对象, 模式对象,可以理解成就是一个正则表达式对象
//提取文章中所有的英文
// Pattern pattern = Pattern.compile("[a-zA-z]+");
//提取文章中所有的数字
// Pattern pattern = Pattern.compile("[0-9]+");
//提取文章中所有的数字和英文
// Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-z]+)");
//提取id地址
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");
//2.创建一个匹配器对象
// 理解:就是matcher匹配器按照pattern(模式/样式),到content文本中去匹配
// 找到就返回true,否则就返回false
Matcher matcher = pattern.matcher(content);
//3.开始匹配循环
while (matcher.find()){
//匹配到的文本会放到 m.group(0)
System.out.println("找到:" + matcher.group(0));
}
}
}
二、正则表达式基本介绍
- 一个正则表达式,就是用某种模式去匹配字符串的一个公式。
- 正则表达式不是只有java才有,实际上很多编程语言都支持正则表达式进行字符串操作
三、正则表达式底层实现
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
*/
public class RegTheory_ {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月," +
"Sun公司发布了第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro " +
"Edition,Java2平台的微型版),应用于移动、无线及有限资源的环境;J2SE(Java 2 " +
"Standard Edition,Java 2平台的标准版),应用于桌面环境;J2EE(Java 2Enterprise " +
"Edition,Java 2平台的企业版),应用于基于Java的应用服务器。Java 2平台的发布," +
"是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及。";
//目标:匹配所有四个数字
//说明
//1. \\d 表示一个任意的数字
String regStr = "(\\d\\d)(\\d\\d)";
//2. 创建模式对象
Pattern pattern = Pattern.compile(regStr);
//3. 创建匹配器
//说明: 创建匹配器matcher,按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
/**
*
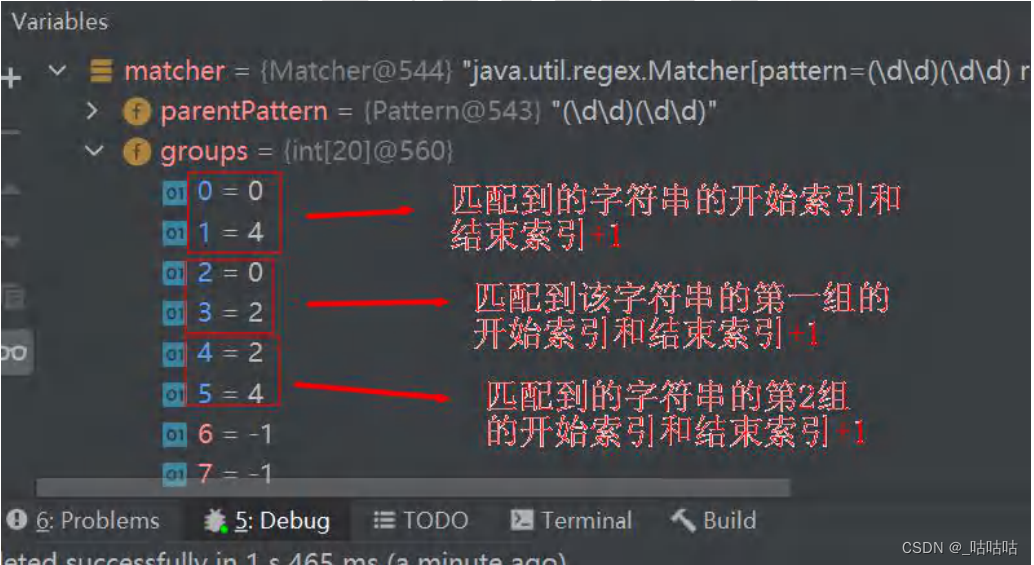
* matcher.find() 完成的任务 (考虑分组)
* 什么是分组,比如 (\d\d)(\d\d) ,正则表达式中有() 表示分组,
* 第 1 个()表示第 1 组,第 2 个()表示第 2 组...
* 1. 根据指定的规则 ,定位满足规则的子字符串(比如(19)(98))
*
* 2. 找到后,将 子字符串的开始的索引记录到 matcher 对象的属性 int[] groups;
* 2.1 groups[0] = 0 , 把该子字符串的结束的索引+1 的值记录到 groups[1] = 4
* 2.2 记录 1 组()匹配到的字符串 groups[2] = 0 groups[3] = 2
* 2.3 记录 2 组()匹配到的字符串 groups[4] = 2 groups[5] = 4
* 2.4.如果有更多的分组..... * 3. 同时记录 oldLast 的值为 子字符串的结束的 索引+1 的值即 35,
* 即下次执行 find 时,就从 35 开始匹配
*
* matcher.group(0) 分析
*
* 源码:
* public String group(int group) {
* if (first < 0)
* throw new IllegalStateException("No match found");
* if (group < 0 || group > groupCount())
* throw new IndexOutOfBoundsException("No group " + group);
* if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
* return null;
* return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
* }
*
* 1. 根据 groups[0]=31 和 groups[1]=35 的记录的位置,从 content 开始截取子字符串返回
* 就是 [31,35) 包含 31 但是不包含索引为 35 的位置
*
* 如果再次指向 find 方法.仍然安上面分析来执行
*/
while (matcher.find()){
//小结
//1. 如果正则表达式有() 即分组
//2. 取出匹配的字符串规则如下
//3. group(0) 表示匹配到的子字符串
//4. group(1) 表示匹配到的子字符串的第一组字串
//5. group(2) 表示匹配到的子字符串的第 2 组字串
//6. ... 但是分组的数不能越界.
System.out.println("找到: " + matcher.group(0));
System.out.println("第 1 组()匹配到的值=" + matcher.group(1));
System.out.println("第 2 组()匹配到的值=" + matcher.group(2));
}
}
}
四、正则表达式语法
4.1 基本介绍
想灵活运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
- 限定符
- 选择匹配符
- 分组组合和反向引用符
- 特殊字符
- 字符匹配符
- 定位符
4.2 元字符—转移号 \\
\\ 符号说明:在我们使用正则表达式去检索某些特殊字符的时候,需要用到转移符号,佛祖额检索不到结果,甚至会报错
需要用到转义符号的字符有以下: . * + ( ) $ / \ ? [ ] ^ { }
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 演示转义字符的使用
*/
public class Regexp02 {
public static void main(String[] args) {
String content = "abc$(abc.(123(";
// 匹配( ——> \\(
// 匹配. ——> \\.
// String regStr = "\\(";
String regStr = "\\.";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
//循环匹配
while (matcher.find()){
System.out.println("找到 " + matcher.group(0));
}
}
}
4.3 元字符—字符匹配符
| 符号 | 含义 | 示例 | 说明 |
| [ ] | 可接受的字符列表 | [efgh] | e、f、g、h中任意一个字符 |
| [^] | 不可接受的字符列表 | [^abc] | 除a、b、c之外任意一个字符,包括数字和特殊符号 |
| – | 连字符 | A-Z | 任意单个大写字母 |
| 符号 | 含义 | 示例 | 说明 |
| . | 匹配除\n以外的任何字符 | a..b | 以a开头b结尾,中间包括两个任意字符的长度为4的字符串 |
| \\d | 匹配单个数字字符,相当于[0-9] | \\d{3}(\\d)? | 包含3个或4个数字的字符串 |
| \\D | 匹配单个非数字字符,相当于[^0-9] | \\D(\\d)* | 以单个非数字字符开头,后接任意个数字字符串 |
| \\w | 匹配单个数字、大小写字母字符,相当于[0-9a-zA-Z] | \\d{3}\\w{4} | 以3个数字字符开头的长度为7的数字字母字符串 |
| \\W | 匹配单个非数字、大小写字母字符,相当于[^0-9a-zA-Z] | \\W+\\d{2} | 以至少1个非数字字母字符开头,2个数字字符结尾的字符串 |
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 演示字符匹配符的使用
*/
public class Regexp03 {
public static void main(String[] args) {
String content = "a11c8abc_ ABCy @";
// String regStr = "[a-z]"; //匹配 a-z之间任意一个字符
// String regStr = "[A-Z]"; //匹配 A-Z之间任意一个字符
// String regStr = "abc"; //匹配 abc字符串。默认区分大小写
// String regStr = "(?i)abc"; //匹配 abc字符串不区分大小写
// String regStr = "a(?i)bc"; //匹配 abc字符串,bc不区分大小写
// String regStr = "a((?i)b)c"; //匹配 abc字符串,只有b不区分大小写
// String regStr = "[0-9]"; //匹配 0-9之间的任意一个字符
// String regStr = "[^a-z]"; //匹配不在 a-z之间的任意一个字符
// String regStr = "[^0-9]"; //匹配不在 0-9之间的任意一个字符
// String regStr = "[abcd]"; //匹配 abcd中的任意一个字符
// String regStr = "\\D"; //匹配 不在0-9之间的任意一个字符
// String regStr = "\\w"; //匹配 任意大小写英文字母、数字、和下划线
// String regStr = "\\W"; //匹配 除了任意大小写英文字母、数字、和下划线的字符
// String regStr = "\\s"; //匹配 任何空白字符(空格、制表符等)
// String regStr = "\\S"; //匹配 任何非空白字符
String regStr = "."; //匹配除\n之外的所有字符,如果要匹配 .本身,则需要使用\\.
//说明
//当创建Pattern对象时,指定 Pattern.CASE_INSENSITIVE,表示匹配不区分字母大小写
Pattern pattern = Pattern.compile(regStr /*,Pattern.CASE_INSENSITIVE*/);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到 " + matcher.group(0));
}
}
}
4.4 选择匹配符
在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以匹配那个
| 符号 | 含义 | 示例 | 说明 |
| | | 匹配 “ | ”之前或之后的表达式 | ab|cd | ab或cd |
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
*/
public class Regexp04 {
public static void main(String[] args) {
String content = "gugumao 咕 鼓鼓";
String regStr = "gu|咕|鼓";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到 " + matcher.group(0));
}
}
}
4.5 元字符—限定符
用于指定其前面的字符和组合项连续出现多少次
| 符号 | 含义 | 示例 | 说明 |
| * | 指定字符重复0次或n次(无要求)零到多 | (abc)* | 仅包含任意个abc的字符串,等效于\w* |
| + | 指定字符重复1次或n次(至少一次)1到多 | m+(abc)* | 以至少1个m开头,后接任意个abc的字符串 |
| ? | 指定字符重复0次或1次(最多-次)0到1 | m+abc? | 至少1个m开头,后接ab或abc的字符串 |
| {n} | 只能输入n个字符 | [abcd]{3} | 由abcd中字母组成的任意长度为3的字符串 |
| 符号 | 含义 | 示例 | 说明 |
| {n, } | 指定至少n个匹配 | [abcd]{3, } | 由abcd中字母组成的任意长度不小于3的字符串 |
| {n, m} | 指定至少n个但不多于m个匹配 | [abcd]{3, 5} | 由abcd中字母组成的任意长度不小于3,不大于5的字符串 |
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 演示限定符的使用
*/
public class Regexp05 {
public static void main(String[] args) {
String content = "a1111111aaaaaahello";
// String regStr = "a{3}"; //表示匹配 aaa
// String regStr = "1{4}"; //表示匹配 1111
// String regStr = "\\d{2}"; //表示匹配 两位的任意数字字符
//细节:java匹配时默认是贪婪匹配,即尽可能匹配多的
// String regStr = "a{3,4}"; //表示匹配 aaa或者aaaa
// String regStr = "1{4,5}"; //表示匹配 1111或者11111
// String regStr = "\\d{2,5}"; //表示匹配 2位数字h或者3,4,5
//1+
// String regStr = "1+"; //表示匹配一个1或者多个1
// String regStr = "\\d+"; //表示匹配一个数字或者多个数字
//1*
// String regStr = "1*"; ///表示匹配 0 个 1 或者多个 1
//演示?的使用, 遵守贪婪匹配
String regStr = "a1?"; //匹配 a 或者 a1
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到 " + matcher.group(0));
}
}
}
4.6 元字符—定位符
定位符,规定要匹配的字符串的位置,比如在字符串的开始还是在结束的位置
| 符号 | 含义 | 示例 | 说明 |
| ^ | 指定起始字符 | ^[0-9]+[a-z]* | 以至少1个数字开头,后接任意个小写字母的字符串 |
| $ | 指定结束字符 | ^[0-9]\\-[a-z]+$ | 以1个数字开头后接连字符“-”,并以至少1个小写字母结尾的字符串 |
| \\b | 匹配目标字符串的边界 | gu\\b | 这里说的字符串的边界指的是子串间有空格,或者是自标字符串的结束位置 |
| \\B | 匹配目标字符串的非边界 | gu\\B | 和\b的含义刚刚相反 |
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 演示定位符的使用
*/
public class Regexp06 {
public static void main(String[] args) {
// String content = "123-abc";
String content = "gugumao spgu zxgu";
//以至少 1 个数字开头,后接任意个小写字母的字符串
// String regStr = "^[0-9]+[a-z]";
//以至少 1 个数字开头, 必须以至少一个小写字母结束
// String regStr = "^[0-9]+\\-[a-z]+$";
//表示匹配边界的 han[这里的边界是指:被匹配的字符串最后,
// 也可以是空格的子字符串的后面]
// String regStr = "gu\\b";
//和\\b 的含义刚刚相反
String regStr = "gu\\B";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到 " + matcher.group(0));
}
}
}
4.7 分组
| 常用分组构造形式 | 说明 |
| (pattern) | 非命名捕获。捕获匹配的子字符串。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其他捕获结果则根据左括号的顺序从1开始自动编号 |
| (?<name>pattern) | 命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。用于name 的字符串不能包含任何标点符号,并且不能以数字开头。可以使用单引号代替尖括号,例如( ? ‘name’ ) |
| 常用分组构造形式 | 说明 |
| (?:pattern) | 匹配pattern但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用”or”字符(|)组合模式部件的情况很有用。 |
| (?=pattern) | 它是一个非捕获匹配。例如,”Windows (?=95|98[NT|2000)’匹配”Windows 2000″中的“Windows”,但不匹配”Windows 3.1″中的”Windows”。 |
| (?!pattern) | 该表达式匹配不处于匹配pattern的字符串的起始点的搜索字符串。它是一个非捕获匹配。例如,”Windows (?!95|98[NT|2000)’匹配 “Windows 3.1″中的“Windows”,但不匹配”Windows 2000″中的”Windows”。 |
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
*/
public class Regexp07 {
public static void main(String[] args) {
String content = "gugumao s7789 nn1189gu";
//下面就是非命名分组
//说明
// 1. matcher.group(0) 得到匹配到的字符串
// 2. matcher.group(1) 得到匹配到的字符串的第 1 个分组内容
// 3. matcher.group(2) 得到匹配到的字符串的第 2 个分组内容
// String regStr = "(\\d\\d)(\\d\\d)";
//命名分组: 即可以给分组取名
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";//匹配 4个数字的字符串
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到 " + matcher.group(0));
System.out.println("第一个分组内容= " + matcher.group(1));
System.out.println("第一个分组内容[通过组名]= " + matcher.group("g1"));
System.out.println("第二个分组内容= " + matcher.group(2));
System.out.println("第二个分组内容[通过组名]= " + matcher.group("g2"));
}
}
}
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
*/
public class Regexp08 {
public static void main(String[] args) {
String content = "hello 咕咕猫教育 jack 咕咕猫老师 咕咕猫同学 hello";
// 找到 咕咕猫教育 、咕咕猫老师、咕咕猫同学 子字符串
// String regStr = "咕咕猫教育|咕咕猫老师|咕咕猫同学";
//上面的写法可以等价非捕获分组, 注意:下面不能使用 matcher.group(1)
// String regStr = "咕咕猫(?:教育|老师|同学)";
//找到 咕咕猫 这个关键字,但是要求只是查找咕咕猫教育和 咕咕猫老师 中包含有的咕咕猫
//下面也是非捕获分组,不能使用 matcher.group(1)
// String regStr = "咕咕猫(?=教育|老师)";
//找到 咕咕猫 这个关键字,但是要求只是查找 不是 (咕咕猫教育 和 咕咕猫老师) 中包含有的咕咕猫
//下面也是非捕获分组,不能使用 matcher.group(1
String regStr = "咕咕猫(?!教育|老师)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
}
}
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 演示正则表达式的使用,验证复杂的URL
*/
public class Regexp11 {
public static void main(String[] args) {
// String content = "https://www.bilibili.com/video/BV1fh411y7R8?p=894";
String content = "https://www.bilibili.com/blackboard/activity-summer-pc.html?spm_id_from=333.1007.0.0";
/**
* 思路
* 1. 先确定 url的开始部分 https:// | http://
* 2. 然后通过 ([\w-]+\.)+[\w-]+ 匹配 www.bilibili.com
*/
String regStr = "^((https|http)://)?([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?$"; //当[? . *]表示匹配就是符号本身
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.find()){
System.out.println("满足格式");
}else{
System.out.println("不满足格式");
}
}
}
4.8 正则表达式三个常用类
java.util.regex包主要包括以下三个类:Pattern类、Matcher类和PatternSyntaxException
- Pattern类
pattern对象是一个正则表达式对象。Pattern类没有公共构造方法。要创建一个Pattern对象,调用其公共静态方法,它返回一个Pattern对象。该方法接受一个正则表达式作为它的第一个参数
- Matcher类
Matcher对象是对输入字符串进行解释和匹配的引擎。与Pattern类一样,Matcher也没有公共构造方法。需要调用Pattern对象的matcher方法来获得一个Matcher对象
- PatternSyntaxException
PatternSyntaxException是一个非强制异常类,它表示一个正则表达式模式中的语法错误

package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
*/
public class MatcherMethod {
public static void main(String[] args) {
String content = "hello ggm jack tom hellosmith ggm hello ggm";
String regStr = "hello";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println("==============");
System.out.println(matcher.start());
System.out.println(matcher.end());
System.out.println("找到 " + content.substring(matcher.start(),matcher.end()));
}
//整体匹配方法,常用于,去校验某个字符串是否满足某个规则
System.out.println("整体匹配" + matcher.matches());
//完成如果 content 有 ggm 替换成 咕咕猫
regStr = "ggm";
pattern = Pattern.compile(regStr);
matcher = pattern.matcher(content);
String newString = matcher.replaceAll("咕咕猫");
//注意:返回的字符串才是替换后的字符串 原来的 content 不变化
System.out.println("newString= " + newString);
System.out.println("content= " + content); //原来的content不会变化,除非 content = matcher.replaceAll("咕咕猫");
}
}
4.9 分组、捕获、反向引用
1. 分组
我们可以用圆括号组成一个比较复杂的匹配模式,那么一个圆括号的部分我们可以看作是一个子表达式/一个分组
2. 捕获
把正则表达式中子表达式/分组匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后边引用,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。组0代表的是整个正则式
3. 反向引用
圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用匹配模式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用\\分组号,外部反向引用$分组号
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 反向引用
*/
public class Regexp12 {
public static void main(String[] args) {
String content = "hello12321-333999111 jack33333 tom11 jack22 12345yyy x1551xx";
//匹配两个连续相同的数字
// String regStr = "(\\d)\\1";
//匹配五个连续相同的数字
// String regStr = "(\\d)\\1{4}";
//匹配个位与千位相同,十位与百位相同的数,如:5225
// String regStr = "(\\d)(\\d)\\2\\1";
/**
* 请在字符串中检索商品编号,形式如:12321-333999111 这样的号码,
* 要求满足前面是一个五位数,然后一个1号,然后是一个九位数,连续的每三位要相同
*/
String regStr = "\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while(matcher.find()){
System.out.println("找到: " + matcher.group(0));
}
}
}
package com.learn.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author 咕咕猫
* @version 1.0
* 经典的结巴程序,通过正则表达式修改语句
*/
public class Regexp13 {
public static void main(String[] args) {
String content = "我....我要....学学学学....编程 java!";
// 1.去掉所有的.
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
content = matcher.replaceAll("");
// System.out.println("content= " + content);
//2. 去掉重复的字 我我要学学学学编程 java!
// 思路
//(1) 使用 (.)\\1+
//(2) 使用 反向引用$1 来替换匹配到的内容
// 注意:因为正则表达式变化,所以需要重置 matcher
// pattern = Pattern.compile("(.)\\1+");
// matcher = pattern.matcher(content);
// while(matcher.find()){
// System.out.println("找到:" + matcher.group(0));
// }
// //使用反向引用$1 来替换匹配到的内容
// content = matcher.replaceAll("$1");
// System.out.println("content= " + content);
//3.使用一条语句 去掉重复的字 我我要学学学学编程 java
content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");
System.out.println("content= " + content);
}
}
4.10 String类中使用正则表达式
4.10.1 替换功能
String类 public String replaceAll(String regex,String replacement)
4.10.2 判断功能
String类 public boolean matcher(String regex){} //使用Pattern和Matcher类
4.10.3 分割功能
String类 public String[] split(String regex)
package com.learn.regexp;
/**
* @author 咕咕猫
* @version 1.0
*/
public class StringReg {
public static void main(String[] args) {
String content = "2000 年 5 月,JDK1.3、JDK1.4 和 J2SE1.3 相继发布,几周后其" +
"获得了 Apple 公司 Mac OS X 的工业标准的支持。2001 年 9 月 24 日,J2EE1.3 发" +
"布。" +
"2002 年 2 月 26 日,J2SE1.4 发布。自此 Java 的计算能力有了大幅提升";
//使用正则表达式方式,将 JDK1.3 和 JDK1.4 替换成 JDK
content = content.replaceAll("JDK1.3|JDK1.4", "JDK");
System.out.println("content= " + content);
//要求 验证一个 手机号, 要求必须是以 138 139 开头的
content = "13888889999";
if (content.matches("1(38|39)\\d{8}")) {
System.out.println("验证成功");
} else {
System.out.println("验证失败");
}
//要求按照 # 或者 - 或者 ~ 或者 数字 来分割
System.out.println("===============");
content = "hello#abc-jack12smith~北京";
String[] split = content.split("#|-|~|\\d+");
for (String s : split) {
System.out.println(s);
}
}
}