本周工作
上一周对于LaneNet这一模型进行了了相关复现,训练以及测试,因为LaneNet算是比较经典的一个车道线检测模型,距今时间较长,而且其问题我也在上一周的博客中指明,这一周我继续对于近今年国际上SOTA水平的车道线预测模型进行了阅读,其中包括SCNN模型,RESA模型。RESA模型是SCNN模型的延伸,而因为SCNN的速度较慢,帧率很低的问题我决定并不复现SCNN,而RESA模型是在SCNN上的改进,速度方面有较大提升,准确率也是在SOTA水平上,我根据论文复现了RESA模型,并进行了相关的模型训练和测试。并自己写了一个demo来验证模型的合理性。我的相关工作也可以看我的个人博客网站个人博客。
SCNN介绍
传统的CNN模型是由卷积块堆叠构建,由上一层输入的张量进行卷积,激活池化等操作,而这种模型对于强先验形状的效果并不好,对于遮挡的部分识别效果并不好。而SCNN在CNN的基础上进行改进,在图片的行和列上进行切片进行卷积操作从而使得图片中行和列可以传递信息,扩大感受野。
RESA网络结构
这是我复现出RESA网络的结构:
RESANet(
(backbone): ResNetWrapper(
(model): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(out): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(resa): RESA(
(conv_d0): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_u0): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_r0): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_l0): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_d1): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_u1): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_r1): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_l1): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_d2): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_u2): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_r2): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_l2): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_d3): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_u3): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_r3): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_l3): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_d4): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_u4): Conv2d(128, 128, kernel_size=(1, 9), stride=(1, 1), padding=(0, 4), bias=False)
(conv_r4): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
(conv_l4): Conv2d(128, 128, kernel_size=(9, 1), stride=(1, 1), padding=(4, 0), bias=False)
)
(decoder): BUSD(
(layers): ModuleList(
(0): UpsamplerBlock(
(conv): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(follows): ModuleList(
(0): non_bottleneck_1d(
(conv3x1_1): Conv2d(64, 64, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_1): Conv2d(64, 64, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn1): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(conv3x1_2): Conv2d(64, 64, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_2): Conv2d(64, 64, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn2): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout2d(p=0, inplace=False)
)
(1): non_bottleneck_1d(
(conv3x1_1): Conv2d(64, 64, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_1): Conv2d(64, 64, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn1): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(conv3x1_2): Conv2d(64, 64, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_2): Conv2d(64, 64, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn2): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout2d(p=0, inplace=False)
)
)
(interpolate_conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(interpolate_bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): UpsamplerBlock(
(conv): ConvTranspose2d(64, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(follows): ModuleList(
(0): non_bottleneck_1d(
(conv3x1_1): Conv2d(32, 32, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_1): Conv2d(32, 32, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn1): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(conv3x1_2): Conv2d(32, 32, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_2): Conv2d(32, 32, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn2): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout2d(p=0, inplace=False)
)
(1): non_bottleneck_1d(
(conv3x1_1): Conv2d(32, 32, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_1): Conv2d(32, 32, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn1): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(conv3x1_2): Conv2d(32, 32, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_2): Conv2d(32, 32, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn2): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout2d(p=0, inplace=False)
)
)
(interpolate_conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(interpolate_bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(2): UpsamplerBlock(
(conv): ConvTranspose2d(32, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(follows): ModuleList(
(0): non_bottleneck_1d(
(conv3x1_1): Conv2d(16, 16, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_1): Conv2d(16, 16, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn1): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(conv3x1_2): Conv2d(16, 16, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_2): Conv2d(16, 16, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn2): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout2d(p=0, inplace=False)
)
(1): non_bottleneck_1d(
(conv3x1_1): Conv2d(16, 16, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_1): Conv2d(16, 16, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn1): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(conv3x1_2): Conv2d(16, 16, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(conv1x3_2): Conv2d(16, 16, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(bn2): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout2d(p=0, inplace=False)
)
)
(interpolate_conv): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(interpolate_bn): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(output_conv): Conv2d(16, 7, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(heads): ExistHead(
(dropout): Dropout2d(p=0.1, inplace=False)
(conv8): Conv2d(128, 7, kernel_size=(1, 1), stride=(1, 1))
(fc9): Linear(in_features=6440, out_features=128, bias=True)
(fc10): Linear(in_features=128, out_features=6, bias=True)
)
)
它的网络结构如下图所示: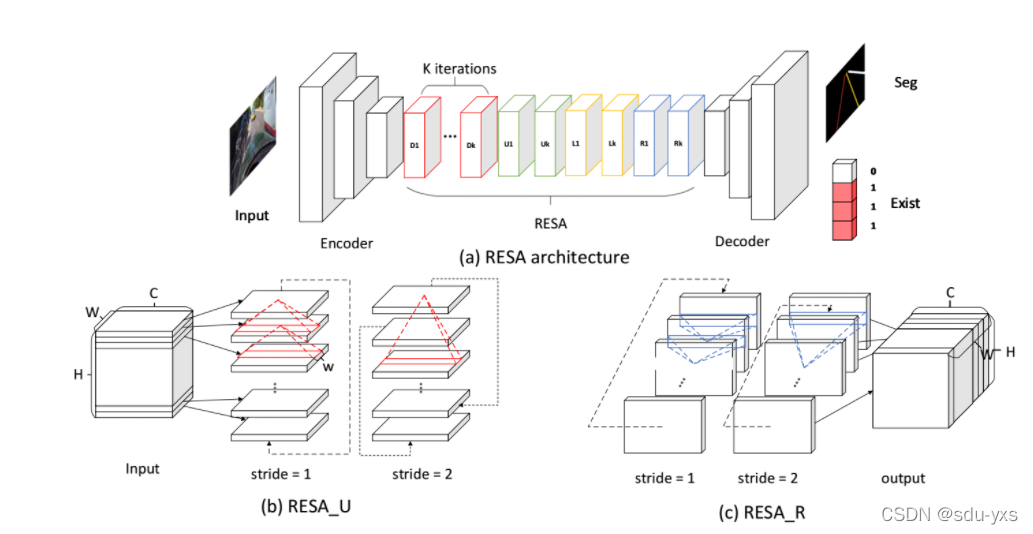
根据我的分析和查看相关代码,将RESA的模型网络结构总结如下:
1.编码器
用来提取图片的主要特征,可以使用resnet,vgg等网络 ,通过我的观察和研究,这一部分属于每一个车道线模型的基本步骤。
它的主要创新点为下面两个网络
2.RESA网络
代码主要如下所示:
class RESA(nn.Module):
def __init__(self, cfg):
super(RESA, self).__init__()
self.iter = cfg.resa.iter
chan = cfg.resa.input_channel
fea_stride = cfg.backbone.fea_stride
self.height = cfg.img_height // fea_stride
self.width = cfg.img_width // fea_stride
self.alpha = cfg.resa.alpha
conv_stride = cfg.resa.conv_stride
## 在垂直和水平方向上进行卷积,设置步长,实现了并行的传递信息
for i in range(self.iter):
conv_vert1 = nn.Conv2d(
chan, chan, (1, conv_stride),
padding=(0, conv_stride//2), groups=1, bias=False)
conv_vert2 = nn.Conv2d(
chan, chan, (1, conv_stride),
padding=(0, conv_stride//2), groups=1, bias=False)
setattr(self, 'conv_d'+str(i), conv_vert1)
setattr(self, 'conv_u'+str(i), conv_vert2)
conv_hori1 = nn.Conv2d(
chan, chan, (conv_stride, 1),
padding=(conv_stride//2, 0), groups=1, bias=False)
conv_hori2 = nn.Conv2d(
chan, chan, (conv_stride, 1),
padding=(conv_stride//2, 0), groups=1, bias=False)
setattr(self, 'conv_r'+str(i), conv_hori1)
setattr(self, 'conv_l'+str(i), conv_hori2)
idx_d = (torch.arange(self.height) + self.height //
2**(self.iter - i)) % self.height
setattr(self, 'idx_d'+str(i), idx_d)
idx_u = (torch.arange(self.height) - self.height //
2**(self.iter - i)) % self.height
setattr(self, 'idx_u'+str(i), idx_u)
idx_r = (torch.arange(self.width) + self.width //
2**(self.iter - i)) % self.width
setattr(self, 'idx_r'+str(i), idx_r)
idx_l = (torch.arange(self.width) - self.width //
2**(self.iter - i)) % self.width
setattr(self, 'idx_l'+str(i), idx_l)
def forward(self, x):
x = x.clone()
for direction in ['d', 'u']:
for i in range(self.iter):
conv = getattr(self, 'conv_' + direction + str(i))
idx = getattr(self, 'idx_' + direction + str(i))
x.add_(self.alpha * F.relu(conv(x[..., idx, :])))
for direction in ['r', 'l']:
for i in range(self.iter):
conv = getattr(self, 'conv_' + direction + str(i))
idx = getattr(self, 'idx_' + direction + str(i))
x.add_(self.alpha * F.relu(conv(x[..., idx])))
return x
对于SCNN的信息传递网络
def message_passing_once(self, x, conv, vertical=True, reverse=False):
"""
Argument:
----------
x: input tensor
vertical: vertical message passing or horizontal
reverse: False for up-down or left-right, True for down-up or right-left
"""
nB, C, H, W = x.shape
##对于输入的张量的H,W,迭代传递信息,时间会比resa慢很多
if vertical:
slices = [x[:, :, i:(i + 1), :] for i in range(H)]
dim = 2
else:
slices = [x[:, :, :, i:(i + 1)] for i in range(W)]
dim = 3
if reverse:
slices = slices[::-1]
out = [slices[0]]
for i in range(1, len(slices)):
out.append(slices[i] + F.relu(conv(out[i - 1])))
if reverse:
out = out[::-1]
return torch.cat(out, dim=dim)
比较可以看出resa时间上的优势十分明显。
3.BUSD
RESA的解码网络也加入了自己的元素,创新了双向上采样的解码器,解码器由两个分支组成,一个分支是恢复粗粒度特征,另一个是修复细微的损耗。输入将通过两个分支,并且将产生通道数量减半的2x上采样输出。 通过这些堆叠的解码器块后,RESA生成的1/8特征图将恢复为与输入图像相同的大小。粗
粗粒度分支将从最后一层快速输出粗略向上采样的特征,这可能会忽略细节。设计了一条简单而浅的路径。 我们首先应用1×1卷积来减少
通道数乘以输入特征图的2倍,然后是BN。 双线性插值直接用于对输入特征图进行上采样。 最后,执行ReLU。
细粒度分支用于微调来自粗粒度分支的信息丢失,并且路径比另一个更深。 使用步幅为2的转置卷积对特征图进行上采样,并同时将通道数减少2倍。 与粗粒度分支中使用的类似设计一样,对ReLU进行上采样。 Non-bottleneck块由具有BN和ReLU的四个3×1和1×3卷积组成,可以保持特征图的形状并以分解的方式有效地提取信息。 在上采样操作之后,堆叠了两个non-bottleneck。
4.loss
该网络使用的是交叉熵损失,而具体过程就是使用真正的seg与通过模型前向计算后的seg并softmax后进行求交叉熵损失操作,并进行梯度计算和反向传播。
测试结果
训练出的RESA模型在测试集上的结果还是非常不错的,在服务器上跑出的测试结果如下图所示:

而它的预测的平均速度要比SCNN快很多,在显卡为3090的服务器上推理速度可以达到50帧的水平。