定义
ANTLR, 语言识别的另一个工具(ANother Tool for Language Recognition ),(前身是PCCTS)是一种语言工具,它提供了一个框架,可以通过包含 Java,C++,或 C#动作(action)的语法描述来构造语言识别器,编译器和解析器。
关键概念
- 前端:定义语法规则,antlr通过g4文件来定义
- lexer:词法解规则,就是将一个句子多个字符进行组装分成多个单词的规则
- parser:语法解析,对分词后的整个句子进行解析,可以对每个分词单元做出自定义的处理,从而来实现自己的语法解析功能。
g4文件
g4文件是antlr生成词法解析规则和语法解析规则的基础。该文件是我们自定义的,文件名后缀需要是.g4。
rule
rule是antlr生成词法语法解析的基础。包括了lexer与parser,每条规则都是key:value的形式,以分号结尾。lexer首字母大写,parser小写。
Tokens
词法原子单元会生成一个tokens文件,文件里为每个原子单元定义了一个序号(记号)
fragment词法规则
ANTLR文法中语法规则是在词法规则基础上建立的。但不一定每个词法规则都会被语法规则直接使用。这就象一个类的公有成员和私有成员,公有成员是对外公开的会被外界直接调用。而私有成员不对外公开是由公有成员间接调用的。在词法规则中那些不会被语法规则直接调用的词法规则可以用一个fragment关键字来标识,fragment标识的规则只能为其它词法规则提供基础。
//正确用法
a : INT;
INT : DIGIT+;
fragment DIGIT : ‘0’ .. ‘9’;
//错误用法
a : DIGIT;
INT : DIGIT+;
fragment DIGIT : ‘0’ .. ‘9’;
工作流程

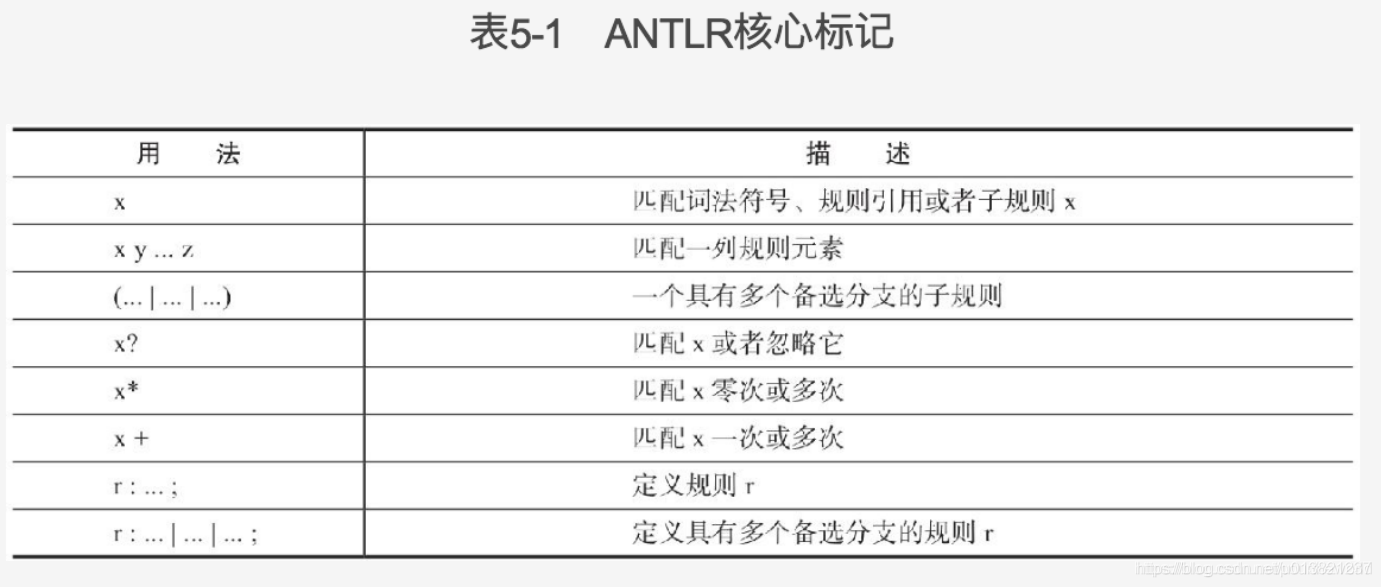
核心标记
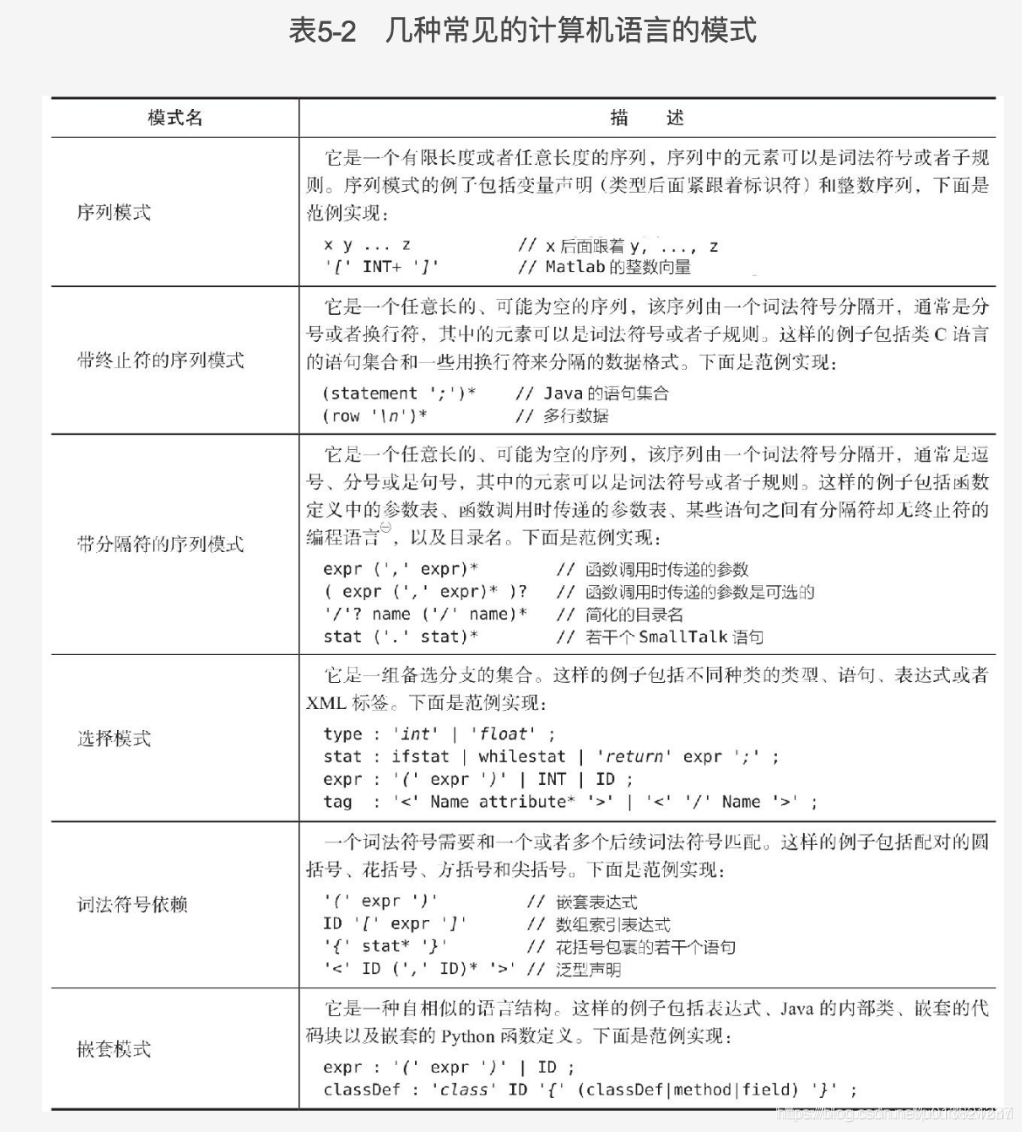
常见模式
核心词法规则总结

版权声明:本文为u013821237原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。