目录
1、索引数据结构
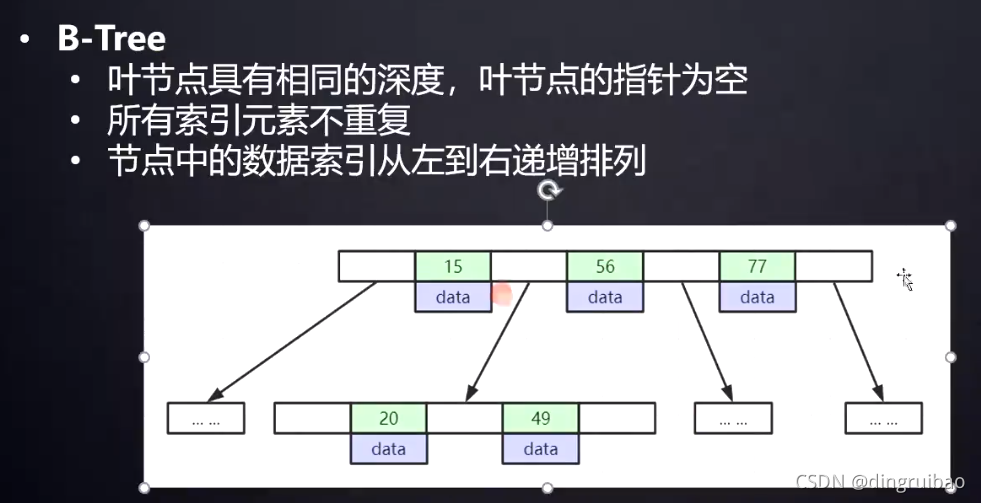
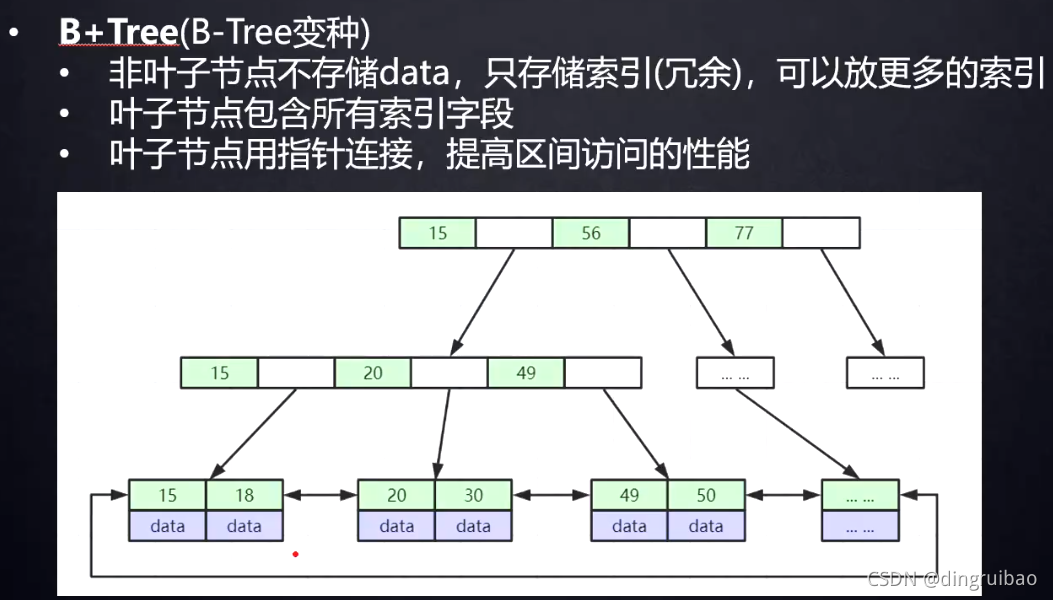
B+Tree:下图:第一、二行非叶子节点,第三行叶子节点。
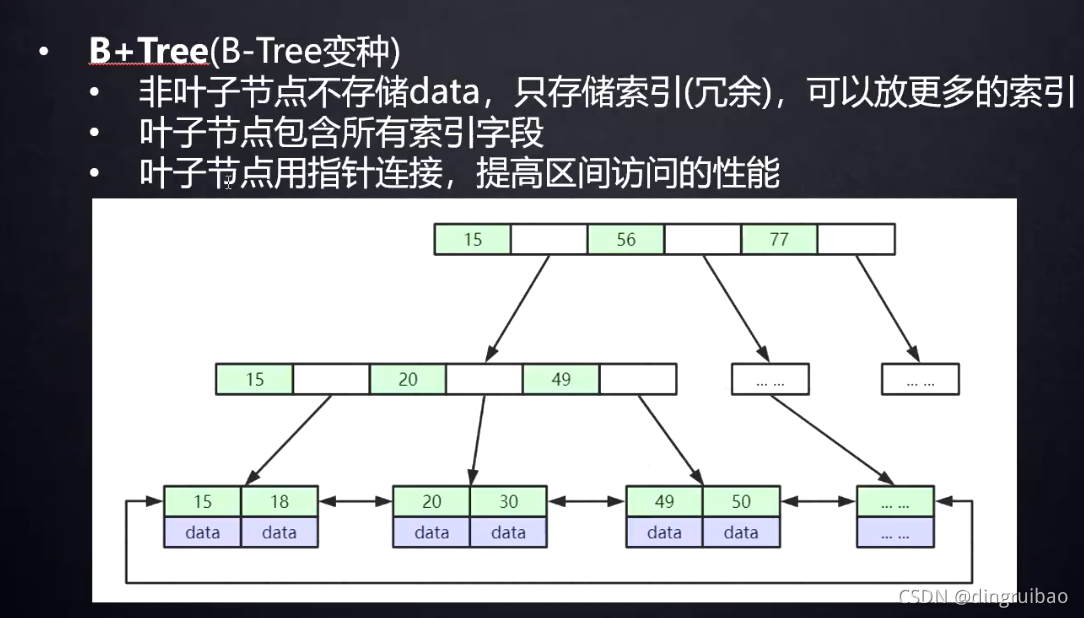
非叶子节点一个节点称一页,一页大小16KB,默认值不推荐改:
![]()
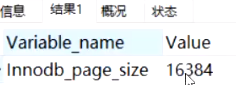
一个非叶子节点:假如索引bingint(8B)+下一个节点的磁盘文件地址(大概6B)=14;16384除以14=1170,一个非叶子节点大概1170个元素,假如叶子节点一个data是1KB,那么3行就是可以存1170乘1170乘16大概是2千多万,也就是千万级别的表也就是3次磁盘IO,而且mysql是会把根节点放到内存,高版本的会把所有非叶子节点放到内存,也就是只有叶子节点需要磁盘IO,B+Tree的高度主要由非叶子节点存储元素能力决定。
Mysam存储引擎:非聚集意味着要索引和数据在不同文件中,需要回表。
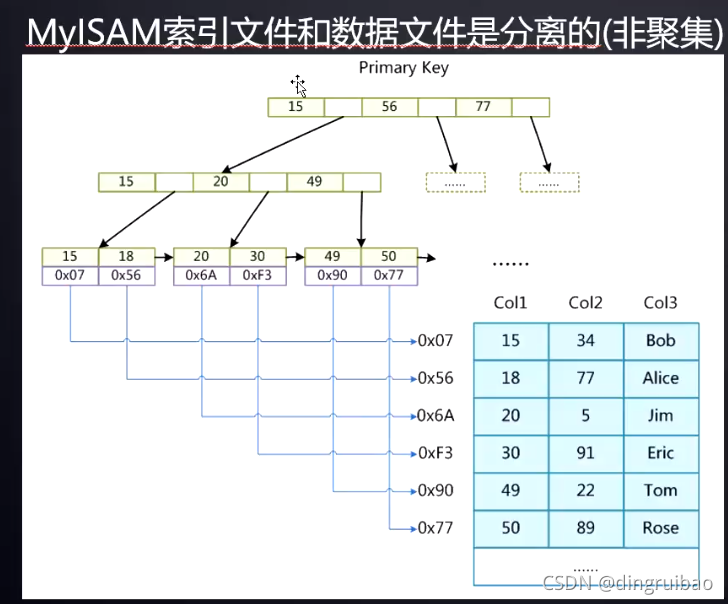
InnoDB:
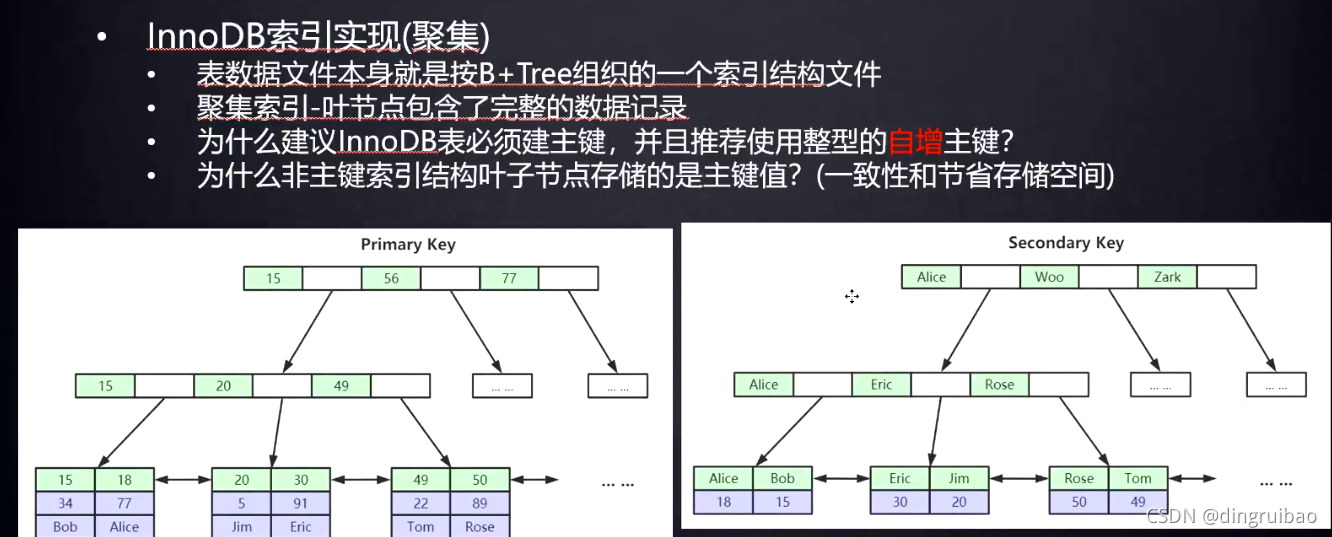
如果我们自己不建主键,mysql会找表中选择所有元素不重复的一列,没有这样的列的话,它会帮我们建一个隐藏列,来组织表数据,这种事尽量不要麻烦它做。
自增(有利于插入速度)整型(排序要比大小,整型比大小比字符串方便,比字符串有利于范围查找)效率较高,而且比字符串占用空间小
InnoDB只有一个主键(聚集)索引,其它索引的叶子节点(只存自己索引列的值和主键索引列的值)指向主键索引的叶子节点,为了一致性和节省空间,主要节省空间。
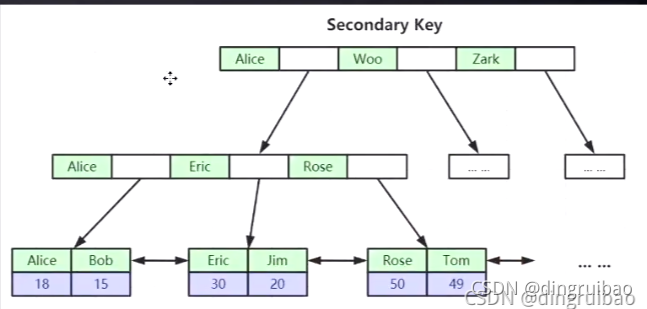
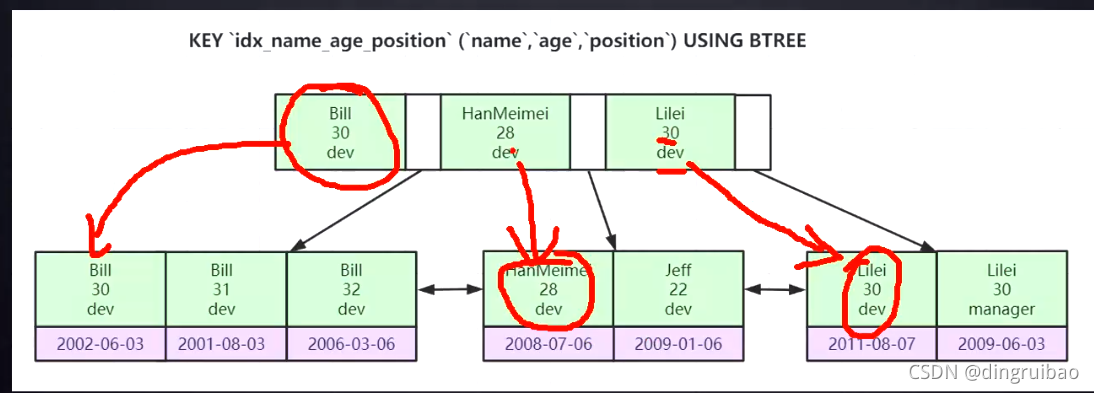
组合索引最左前缀原则:查询条件顺序需要按照组合索引顺序,如果组合索引有三列a,b,c,那么查询条件a,b,c; a,b; a这三种才能用到索引。
如下图如果查询条件只是age=30,那么30 31 32 28 22 30 30,很明显是无序的,无序意味着需要全表扫描。
2、explain详解和实战


















![]()
![]()
![]()


版权声明:本文为dingruibao原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。