目录
零拷贝
DMA
传统文件传输
实现零拷贝
mmap + write
sendfile(Linux 2.1)
sendfile(Linux 2.4)
I/O
过程
第一步:将网络中的数据拷贝到内核缓冲区
第二步:将内核缓冲区数据拷贝到应用进程的缓冲区
同步
理解
拷贝操作不是全部由内核来完成;第二步需要阻塞等待
阻塞 I/O
- 第一步:阻塞等待数据拷贝完成
- 第二步:阻塞等待数据拷贝完成
整体都是阻塞的;会一直阻塞等待读/写,无法执行其他操作

非阻塞 I/O
- 第一步:循环进行系统调用,查看数据是否拷贝完成;无论是否有数据,调用都不会阻塞,立即返回;会耗费大量 CPU 资源
- 第二步:阻塞等待数据拷贝完成
阻塞是针对第一步而言的,是否使用 CPU
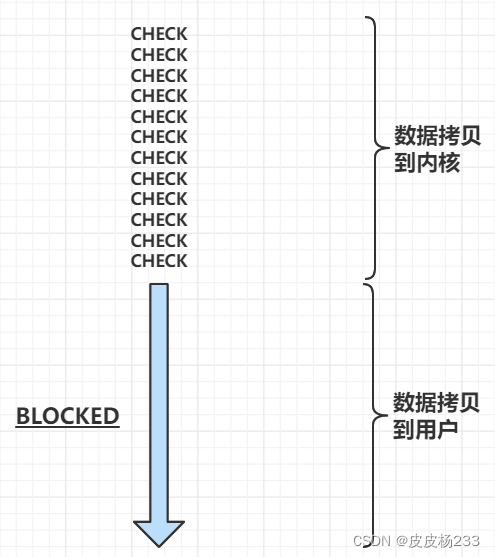
信号驱动式 I/O
- 第一步:完全不阻塞;数据拷贝完成,内核会通知用户进程
- 第二步:阻塞等待数据拷贝完成
只有第二步阻塞

异步
理解
拷贝操作全部由内核来完成
异步 I/O
- 第一步:完全不阻塞
- 第二步:完全不阻塞;数据拷贝完成,内核会通知用户进程
整个过程都不阻塞,内核完成所有操作,通知用户进程

例子:钓鱼🐟
拷贝数据到内核:鱼上钩
拷贝数据到用户态:将鱼放入桶中
- 阻塞 I/O:🐟上钩之前,一直盯着;🐟上钩之后,将🐟入桶
非阻塞 I/O:🐟上钩之前,不需要一直盯着,时不时看看有没有动静;鱼上钩之后,将鱼入桶
信号驱动式 I/O:鱼竿上绑🔔,🐟上钩之前,可以一直不管;🐟上钩之后,🔔会响,然后将🐟入桶
异步 I/O:智能鱼竿,🐟上钩之后,自动入桶;整个过程都不用管,入桶后通知你
I/O 多路复用
出现原因及特点
传统的 socket 模型,一个线程/进程只能处理一个 I/O 请求;无数据读/写,会一直阻塞,无法执行其他操作;要想处理多个 I/O 请求,则需要开多个线程/进程,对资源造成浪费
- I/O 多路复用,一个线程中可以处理多个 I/O 请求
- 可设置超时时间,来决定是否一直阻塞等待系统调用(并非读写数据)
select/poll
过程
- 已连接的 socket 都放到一个文件描述符集合(在用户态)
- select 函数将集合拷贝到内核(第一次拷贝)
- 遍历集合,将产生事件的 socket 标记为可读/可写(第一次遍历 O(n))
- 将集合拷贝回用户态(第二次拷贝)
- 用户态遍历集合,对可读/可写的 socket 进行处理(第二次遍历 O(n))
- 拷贝 2 次,遍历 2 次
select:使用固定长度的 BitsMap,所支持文件描述符个数有限
poll:使用链表,突破文件描述符个数限制

缺点
- 随着并发数上升,拷贝与遍历的开销越来越大
- 检测效率低(可能整个集合都未发生事件)
epoll
特点
① 内核中使用红黑树来跟踪待检测的文件描述符;每次只需要传入一个待检测的 socket,因为存储结构在内核中,不需要再从用户态中将整个集合拷贝;增删查均为 O(logn)
② 使用事件驱动机制,当 socket 有事件发生,通过回调函数内核将其加入就绪队列,不需要再遍历整个集合;内核维护一个链表记录就绪事件
③ 只返回有事件发生的文件描述符
过程
- 需要监控的 socket 通过 epoll_ctl() 加入内核红黑树
- socket 事件发生,加入事件就绪链表
- 用户调用 epoll_wait() 内核将事件就绪链表内描述符,拷贝到用户态

事件触发模式
边缘触发(edge-triggered,ET)
只有第一次满足条件才触发事件;如 socket 中数据从 0 到有,只触发这一次读事件,下一次 0 到有则会再次触发
- 对该文件描述符的操作必须一次性执行完,最好结合非阻塞 I/O(返回的事件并不一定可读写,非阻塞 I/O 可以检测状态)
- 系统调用次数更少,效率更高
- epoll 支持
水平触发(level-triggered,LT)
只要满足条件就会一直触发事件;如 socket 中只要有数据,就会一直触发读事件
- 没必要一次性执行完
- 可以继续检测该文件描述符状态
- select/poll/epoll 支持
优点
- 减少内核和用户态大量拷贝和内存分配
- 极大提高了检测效率
Reactor
基础
核心架构
I/O 多路复用 + 线程池
- I/O 多路复用监听事件
- 收到事件,Dispatch 根据事件类型,分发给某个线程
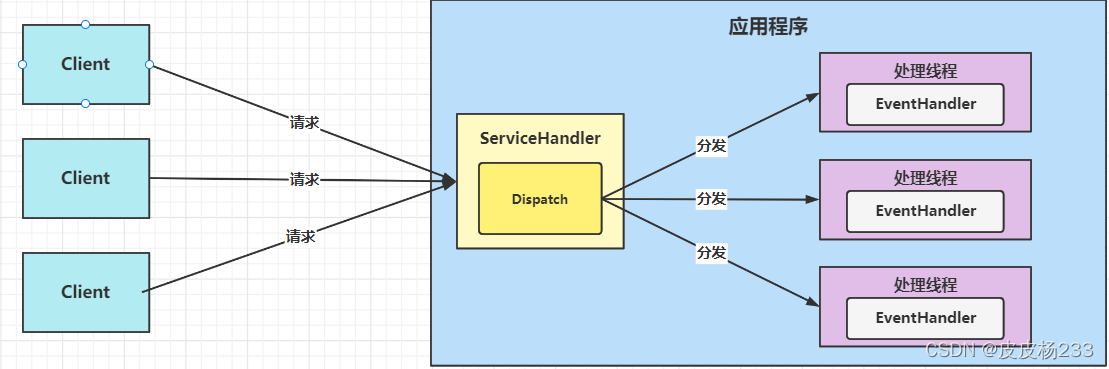
模式优点
- 实现相对简单,可最大程度避免多线程同步以及交换的开销
- 整体是同步的,但不会因为单个同步时间而阻塞
- 可扩展性强,增加 Reactor 实例很方便,以此充分利用 CPU 资源
- 可复用性高,与事件具体处理逻辑无关
适用场景
同时接受多个服务请求,并依次同步处理
单 Reactor 单线程
架构
- Reactor 对象 通过 Select 监听客户端请求事件,收到事件后通过 Dispatch 分发
- 为连接事件,则建立新连接并加入监听队列,为连接分配 Handler 做后续业务操作
- 不为连接事件,则分发调用连接对应的 Handler 来响应

优点
- 模型简单
- 没有多线程竞争问题,都在一个线程内完成
缺点
- 性能问题:不能发挥多核 CPU 的性能优势;在单线程中处理所有事件的监听和响应;处理某个连接的业务时,无法处理其他连接的事件,容易造成性能瓶颈
- 可靠性问题:线程意外终止或者进入死循环,会造成整个系统通信模块不可用,造成结点故障
应用实例
客户数量有限,并且业务处理速度极快 -> redis
单 Reactor 多线程
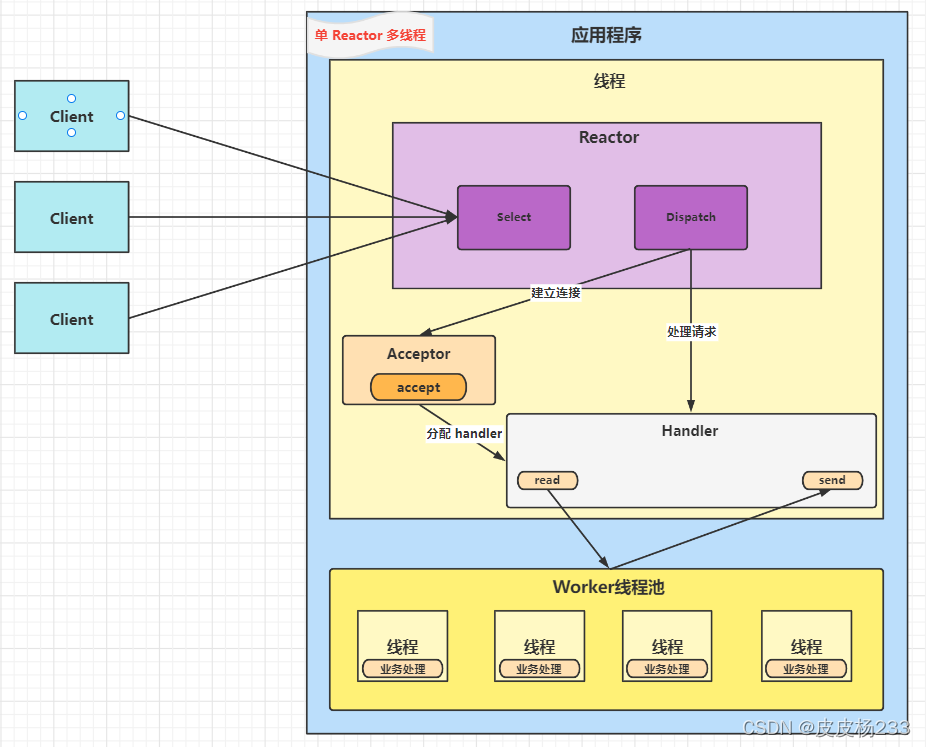
架构
- Reactor 对象 通过 Select 监听客户端请求事件,收到事件后通过 Dispatch 分发
- 为连接事件,则建立新连接并加入监听队列,为连接分配 Handler 做后续业务操作
- 不为连接事件,则分发调用连接对应的 Handler
- Handler 只负责响应,不负责业务处理
- Handler read 数据后,业务交给 Worker 线程池中线程处理;收到业务处理结果后,通过 send 响应客户端
Handler 收到结果才返回,为什么不阻塞?
- Reactor 采用非阻塞 I/O
- 非阻塞 I/O 无数据可读/可写时,不会一直等待(read/send),可以执行其他操作
- 单 Reactor 单线程阻塞,是因为所有复杂耗时的业务都在一个线程中处理
- 将会引起阻塞的业务处理交给其他线程处理,避免了阻塞
优点
充分利用多核 CPU 性能优势
缺点
- 多线数据共享和访问比较复杂
- 单 Reactor 处理所有事件的监听和响应,在单线程中,容易出现性能瓶颈
主从 Reactor 多线程
架构
- Main Reactor 只监听连接事件;建立新连接后,将连接分发给 Slave Reactor;后续所有业务处理事件,就由 Slave Reactor 独立管理
- Slave Reactor 将新连接加入监听队列,为连接分配 Handler 做后续业务操作
- Handler 只负责响应,不负责业务处理
- Handler read 数据后,业务交给 Worker 线程池中线程处理;收到业务处理结果后,通过 send 响应客户端
- 单个 Main Reactor 可以对应多个 Slave Reactor

优点
- 主从职责明确:主 Reactor 只负责接收新连接;从 Reactor 只负责处理业务
- 主从数据交互简单:主 Reactor 只需把新连接分发给从 Reactor(之后无需再管);从 Reactor 无需返回数据,可自行返回
缺点
编程复杂度高
应用实例
- nginx(主进程只负责初始化 socket,其他操作都交给从进程)
- memcached
- netty 主从模型
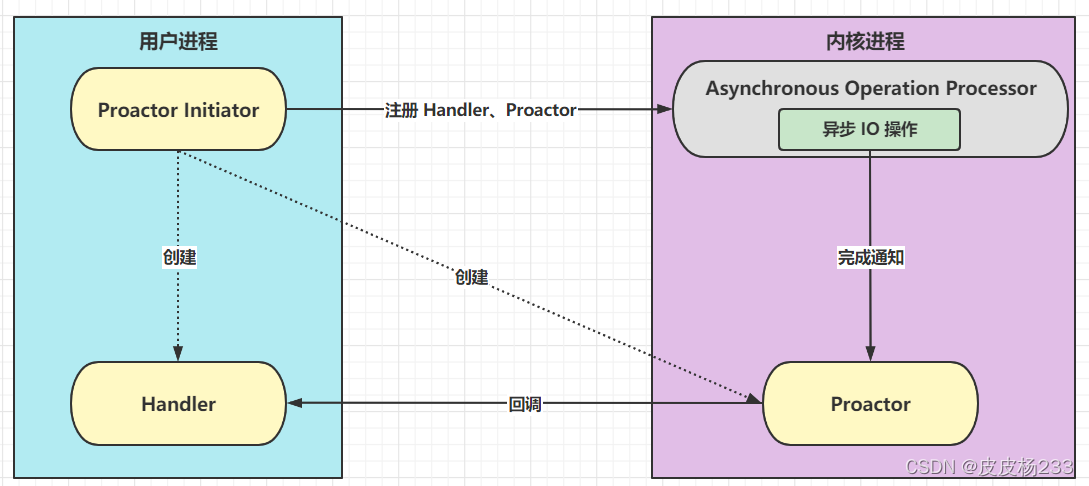
Proactor
基础
核心架构
- Proactor Initiator 创建 Handler、Proactor,并通过 Asynchronous Operation Processor 注册到内核
- Asynchronous Operation Processor 异步处理注册请求和 I/O 操作;I/O 操作完成,通知 Proactor
- Processor 通过事件类型回调不同 Handler 执行业务操作
模式缺点
- 编程复杂性
- 操作系统支持,Windows下通过IOCP实现了真正的异步 I/O,Linux2.6 才引入
适用场景
同时接受多个服务请求,并同时处理
与 Reactor 区别
- Reactor:来了事件,通知应用进程处理(非阻塞 I/O,基于待完成 I/O 事件)
- Proactor:来了事件,操作系统来处理,完成后通知应用进程 (异步 I/O,基于已完成 I/O 事件)