结构体字节对齐详解
表述如有不正确的地方,欢迎批评指正。
C++/C 常见的基本数据类型:
- bool
- short (short int)
- int
- long (long int)
- long long (long long int)
- float
- double
- char
- Type* (指针类型)
注意:对于char,short,int,long,long long都有无符号类型(unsigned + type),无符号类型可以表示的数据范围更大。
在常见系统下每种类型所占字节
在判断结构体所占内存情况前,需要记住每种类型在一般情况下所占字节情况,具体是多少由所用平台(平台 ≈ CPU+OS+Compiler)决定,可以用cout<<sizeof(type)<<endl查
32位 平台
| Type | bytes |
|---|---|
| bool | 1 |
| short | 2 |
| int | 4 |
| long | 4 |
| long long | 8 |
| float | 4 |
| double | 8 |
| char | 1 |
| Type* | 4 |
64位 平台
| Type | bytes |
|---|---|
| bool | 1 |
| short | 2 |
| int | 4 |
| long | 4 |
| long long | 8 |
| float | 4 |
| double | 8 |
| char | 1 |
| Type* | 8 |
结构体所占内存,不是结构体内成员所占字节的简单的相加,这涉及到字节对齐的知识(不仅仅是结构体,类也会字节对齐)
先看一个简单的例子:
#include <iostream>
using namespace std;
struct Node1
{
char a;
int b;
};
int main()
{
int node_size = sizeof(Node1);
cout<<(node_size)<<endl;
return 0;
}
输出为:
8
默认情况下结构体字节对齐方式
结论: 默认情况下:以结构体中最大基本类型为基准进行字节对齐,比如上面那个例子,就是以int 为基准进行结构体字节对齐(int : 4 bytes > char: 1bytes)。
基准的意义是 :结构体所占字节 会是 基准的整数倍数
(内存空间按顺序进行连续填充,如果装不下下一个数据成员就放到在下一行)
(下方统一用null 表示 编译器为了实现字节对齐 而填充的内容)
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| a | a | null | null |
| b | b | b | b |
下一个例子:
#include <iostream>
using namespace std;
struct Node2
{
int a; // 4 bytes
short s; // 2
char b; // 1
long c; // 4
char* d; // 64位: 8 bytes ,32位: 4 bytes
};
int main()
{
int node_size = sizeof(Node2); //64位 : 24 ,32位: 16
cout<<(node_size)<<endl;
return 0;
}
64位平台,上述结构体Node2,以8 bytes为基准, 占 24 个字节:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| a | a | a | a | s | s | b | null |
| c | c | c | c | null | null | null | null |
| d | d | d | d | d | d | d | d |
32位平台,上述结构体Node2 ,以4 bytes为基准,占 16 个字节:
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| a | a | a | a |
| s | s | b | null |
| c | c | c | c |
| d | d | d | d |
再看几个个例子自己体会:
case1:
#include <iostream>
using namespace std;
struct Node3
{
int x1; // 4
char y1; // 1
int x2; // 4
char y2; // 1
};
struct Node4
{
char y1; // 1
char y2; // 1
int x1; // 4
int x3; // 4
};
int main()
{
cout<<sizeof(Node3)<<" "<<sizeof(Node4)<<endl; // 16 12
return 0;
}
补充一种情况,case2:
struct Node5
{
char c[7]; // 1 * 7
int b; // 4
char d; // 1
};
struct Node6
{
int a[2]; // 4 * 2
char c; // 1
};
cout<<sizeof(Node5)<<endl; // 16
cout<<sizeof(Node6)<<endl; // 12
说明一下Node5,字节对齐基准为4 bytes:
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| c | c | c | c |
| c | c | c | null |
| b | b | b | b |
| d | null | null | null |
自己设置结构体字节对齐方式
使用#pragma pack(align_size)自定义对齐基准
struct Node7
{
char a[7]; // 1 * 7
int b; // 4
char c; // 1
float f; // 4
double d; // 8
};
#pragma pack(4) // 设置基准为 4
struct Node8
{
char a[7]; // 1 * 7
int b; // 4
char c; // 1
float f; // 4
double d; // 8
};
#pragma pack() // 不影响后面的基准:后面的依然为默认基准
cout<<sizeof(Node7)<<endl; // 8 + 8 + 8 + 8 = 32
cout<<sizeof(Node8)<<endl; // 4 + 4 + 4 + 4 + 4 + 4 + 4 = 28
详细用法见: #pragma pack()用法详解
struct Node9{};
class Node10{};
typedef union
{
char i; // 1
int k[2]; // 4 * 2
char c; // 1
} DATE;
struct Animal
{
int cat; // 4
DATE cow; // max base var_type:int--> 4
char dog; // 1
};
cout<<sizeof(Node9)<<endl; // 1
cout<<sizeof(Node10)<<endl; // 1
cout<<sizeof(DATE)<<endl; // 8
cout<<sizeof(Animal)<<endl; // 16 = 4 + 4 + 4
类 所占内存
可以通过offsetof宏来成员变量的偏移,根据偏移量可以确定类的成员变量在内存中大致的分布情况:
/*
32 位的平台下
*/
class Normal
{
public:
int a; // 4
char b[3]; // 1 * 3
void print()
{
cout<<"Normal"<<endl;
}
~Normal()
{
cout<<"~Normal"<<endl;
}
};
class Base
{
public:
//void** vptr; // 4 隐含虚表指针,在最前面,也参与字节对齐
int a; // 4
char b[3]; // 1 * 3
virtual void print()
{
cout<<"Base"<<endl;
}
virtual ~Base()
{
cout<<"virtual ~Base"<<endl;
}
};
// main 中输出
cout<<offsetof(Normal,a)<<endl; // 0
cout<<offsetof(Normal,b)<<endl; // 4
cout<<offsetof(Base,a)<<endl; // 4
cout<<offsetof(Base,b)<<endl; // 8
// 可知虚表指针被隐式放在最前面
和结构体一样,存在字节对齐,还有以下结论:
- 普通成员函数不在类的内存区域内(成员函数实际上都是些全局函数,最后都会由this指针进行绑定。所以,他们不会占用类的空间);
- static修饰的静态变量:不在类的内存区域内(原因是编译器将其放在全局变量区);
- 若有虚函数,类中需要额外存储虚表指针(它是void*指针,即void** _vfptr,指向一个指针数组),它被隐式放在 最前面 (如果存在多个虚表指针,有一个在最前面)并 参与字节对齐, 同一个类的不同实例共用同一份虚函数表;
- 对于多继承,可能有多个虚表指针,子类的虚函数地址放在第一个虚表指针指向的指针数组里面;
- 子类所特有的成员变量 被放在子类成员变量后面 ,如果有多个父类,有虚函数的总是被放在最前面;
看几个简单的例子:
/*
32 位平台下
*/
class Normal
{
public:
int a; // 4
char b[3]; // 1 * 3
void print()
{
cout<<"Normal"<<endl;
}
~Normal()
{
cout<<"~Normal"<<endl;
}
};
class Base
{
public:
//void** vptr; // 4 隐含虚表指针,在最前面,也参与字节对齐
int a; // 4
char b[3]; // 1 * 3
virtual void print()
{
cout<<"Base"<<endl;
}
virtual ~Base()
{
cout<<"virtual ~Base"<<endl;
}
};
class Driver:public Base
{
public:
/* Base:
//void** vptr; // 4 隐含虚表指针,在最前面,也参与字节对齐
int a; // 4
char b[3]; // 1 * 3
*/
double d; // 8
char c; // 1
virtual void print()
{
cout<<"Driver"<<endl;
}
virtual ~Driver()
{
cout<<"virtual ~Driver"<<endl;
}
};
// main 中输出
cout<<sizeof(Normal)<<endl; // 4 + 4 = 8
cout<<sizeof(Base)<<endl; // 4 + 4 + 4 = 12
cout<<sizeof(Driver)<<endl; // 8 + 8 + 8 + 8 = 32
有关虚表指针的深度好文见:C++虚函数表,虚表指针,内存分布
放上述推荐的好文里面的两张图总结一下:
- 如果子类继承了有虚函数的基类,子类中虚表指针个数就是有虚函数的基类的个数
- 如果基类中没有虚函数,子类有虚函数,那么就只有一个虚表指针
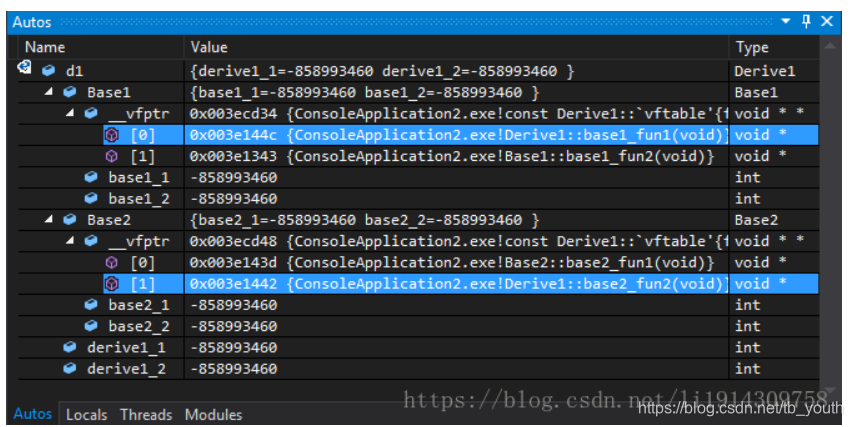

有了上面两张图,类的字节对齐就很好推断了
/*
32 位平台下
*/
class Base1
{
public:
//void** vptr1; // 4 隐含虚表指针,在最前面,也参与字节对齐
int a; // 4
char b[3]; // 1 * 3
virtual void print()
{
cout<<"print Base1"<<endl;
}
virtual ~Base1()
{
cout<<"virtual ~Base1"<<endl;
}
};
class Base2
{
public:
//void** vptr2; // 4
virtual void print()
{
cout<<"Base2"<<endl;
}
virtual ~Base2()
{
cout<<"virtual ~Base2"<<endl;
}
};
class Base3
{
public:
//void** vptr3; // 4
virtual void print3()
{
cout<<"print Base3"<<endl;
}
virtual ~Base3()
{
cout<<"virtual ~Base3"<<endl;
}
};
class Driver:public Base,public Base3,public Base2
{
public:
/* Base1:
//void** vptr1; // 4 隐含虚表指针,在最前面,也参与字节对齐
int a; // 4
char b[3]; // 1 * 3
*/
/*
Base3:
//void** vptr3; // 4
*/
/*
Base2:
//void** vptr2; // 4
*/
double d; // 8
char c; // 1
virtual void print()
{
cout<<"Driver"<<endl;
}
virtual ~Driver()
{
cout<<"virtual ~Driver"<<endl;
}
};
cout<<sizeof(Driver)<<endl; // 8 + 8 + 8 + 8 + 8 = 40
需要明确一点:基类指针赋值为子类对象时,是强制类型转换(子类独有的不能被直接访问和调用了,但可以通过虚函数表间接访问,所以这也存在安全问题~)
Driver d;
Driver * dptr = &d;
dptr->deriver1_fun1(); // ok
Base1 * b1ptr = &d;
b1ptr->deriver1_fun1(); // 编译不过
Base2 *b2ptr = &d;
b2ptr->deriver1_fun1(); // 编译不过
补充
1. 关于数据类型所占内存的说明
我们熟悉的是1byte = 8bit.
但是这不是绝对的,这只是通常情况下1byte = 8 bit.
因为在美国,基本字符集通常位ASCII和EBCDIC字符集,他们都可以使用8位来容纳,所以在这两种字符集的系统中,C++中的 1byte = 8 bit.但是在国际上,可能需要使用更大的字符集。如Unicode,所以有些实现1byte = 16bit 甚至 1byte = 32bit.
我们目前只需要记住通常情况,但是对于其他情况需要有一个了解。
数据类型所占内存随实现而异,这可能在将C++从一种环境迁移到另一种环境时引发问题。(包括在同一个系统中使用不同的编译器)
C++中的 short, int, long, long long通常使用不同数目的位来存储,C++提供了一种灵活的标准,它确保了最小长度,如下所示:
- short >= 16 bit (2 byte) : short至少16位
- sizeof(int) >= sizeof(short) :int 至少与short一样长
- long >= 32 bit (4 byte):long 至少32位
- sizeof(long) >= sizeof(int): long至少与int一样长
- long long >= 64bit (8 byte):long long 至少64位
- sizeof(long long) >= sizeof(long): long long 至少与long 一样长
上述标准有何用途?
我们知道 int 至少与short一样长,short至少16bit,也就是说,极端情况下:int可以是16bit,可以表示的最大整数是
2
2
2
16
16
16
−
1
=
65536
−
1
=
65535
-1 = 65536-1=65535
−1=65536−1=65535
对于需要跨平台的项目中,即使目前平台上 int 是32bit ,也应该使用具有更多bit的数据类型(比如long ,long long)。这样即使将项目移植到 int为16bit 的平台上,项目运行时也不会因为数据溢出而出错。
- 为了确定某种类型所在环境所占内存情况,可以函数
sizeof来确定。 - 每种类型可表示的数据范围等相关信息定义在头文件
<climits>中
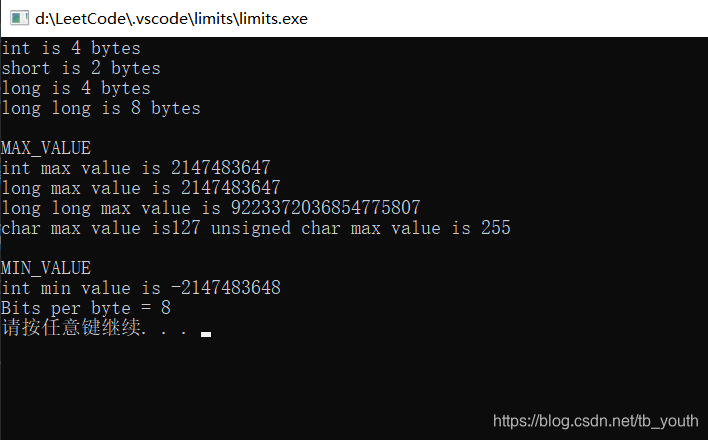
示例:
/*
* @Author: tbyouth
* @Date: 2020-12-17 18:49:36
* @LastEditTime: 2020-12-17 19:58:58
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: \LeetCode\.vscode\hello\limits.cpp
*/
#include <iostream>
#include <climits>
int main()
{
using namespace std;
int n_int = INT_MAX;
short n_short = SHRT_MAX;
long n_long = LONG_MAX;
long long n_llong = LONG_LONG_MAX;
//sizeof:sizeof(type) or sizeof(var_name) or sizeof var_name
cout<<"int is "<<sizeof(int)<<" bytes"<<endl;
cout<<"short is "<<sizeof(n_short)<<" bytes"<<endl;
cout<<"long is "<<sizeof n_long<<" bytes"<<endl;
cout<<"long long is "<<sizeof n_llong<<" bytes"<<endl;
cout<<endl;
// Maximum
cout<<"MAX_VALUE"<<endl;
cout<<"int max value is "<<n_int<<endl;
cout<<"long max value is "<<n_long<<endl;
cout<<"long long max value is "<<n_llong<<endl;
cout<<"char max value is"<<CHAR_MAX<<"unsigned char max value is "<<UCHAR_MAX<<endl;
cout<<endl;
cout<<"MIN_VALUE "<<endl;
cout<<"int min value is "<<INT_MIN<<endl;
cout<<"Bits per byte = "<<CHAR_BIT<<endl;
system("pause");
return 0;
}
64位编译器下的运行结果:
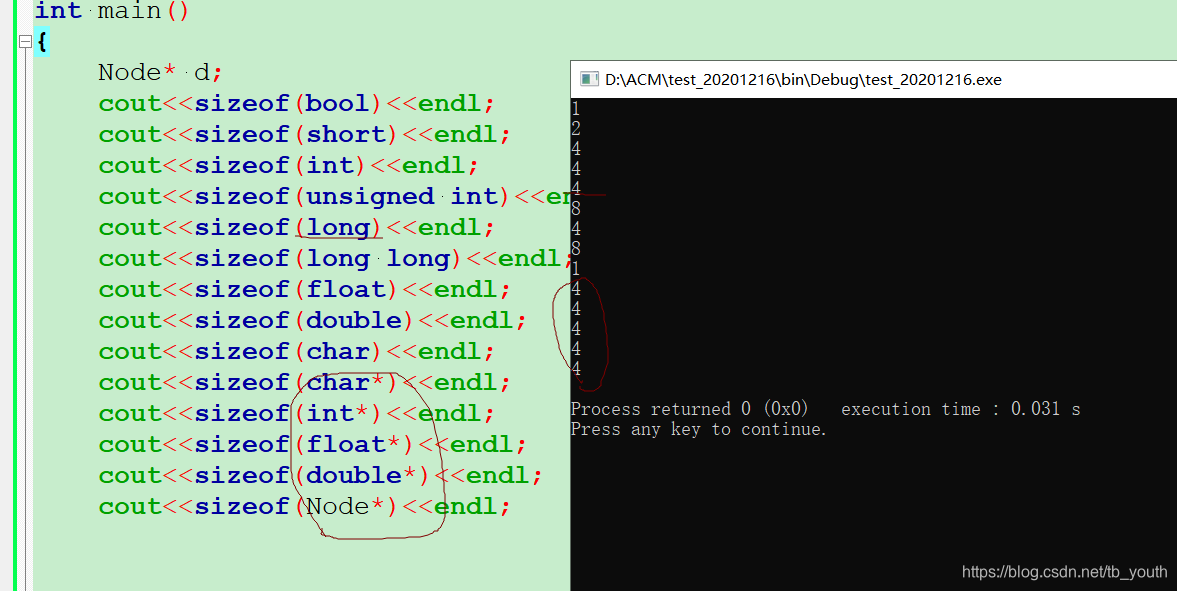
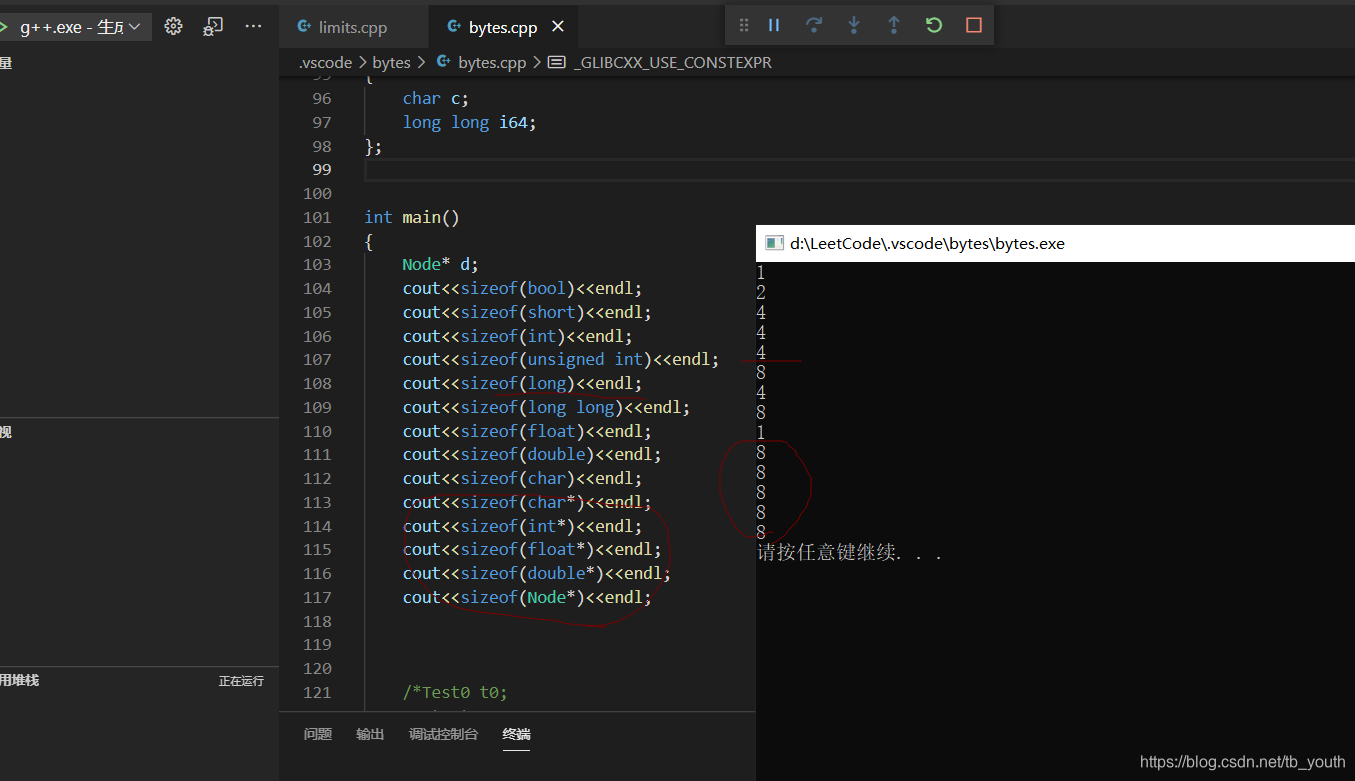
2. 指针类型所占内存
先特别说明指针类型(Type*),因为指针类型指向的是一段地址空间,所以在逻辑上
对于32位的CPU的寻址空间为
2
2
2
32
32
32,即有32bit = 4 bytes。
同理对于64位的CPU,64bit = 8 bytes,对于16位的CPU就是 16bit = 2 bytes
而实际上与 平台(CPU+OS+Compiler)相关
我在使用的不同编译器(Compiler)的两个不同IDE验证与编译器有关:
参考:
1. 32位和64位系统区别及字节对齐
2. 结构体字节对齐,C语言结构体字节对齐详解
3. #pragma pack()用法详解
4. C++ primer plus 第六版