一、代码
# -*- coding:utf-8 -*-
# 词云展示
from wordcloud import WordCloud
import pandas as pd
import matplotlib.pyplot as plt
from nltk.tokenize import word_tokenize
# 去掉停用词
def remove_stop_words(f):
stop_words = ['Movie']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
# 生成词云
def create_word_cloud(f):
print('根据词频,开始生成词云!')
f = remove_stop_words(f)
cut_text = word_tokenize(f)
#print(cut_text)
cut_text = " ".join(cut_text)
wc = WordCloud(
max_words=100,
width=2000,
height=1200,
)
wordcloud = wc.generate(cut_text)
# 写词云图片
wordcloud.to_file("wordcloud.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 数据加载
data = pd.read_csv('movies.csv')
#print("data:", data)
# 读取title 和 genres字段
title = " ".join(data['title'])
print("data['title']:", data['title'])
genres = " ".join(data['genres'])
all_word = title + genres
#print("all_word:", all_word)
# 生成词云
create_word_cloud(all_word)
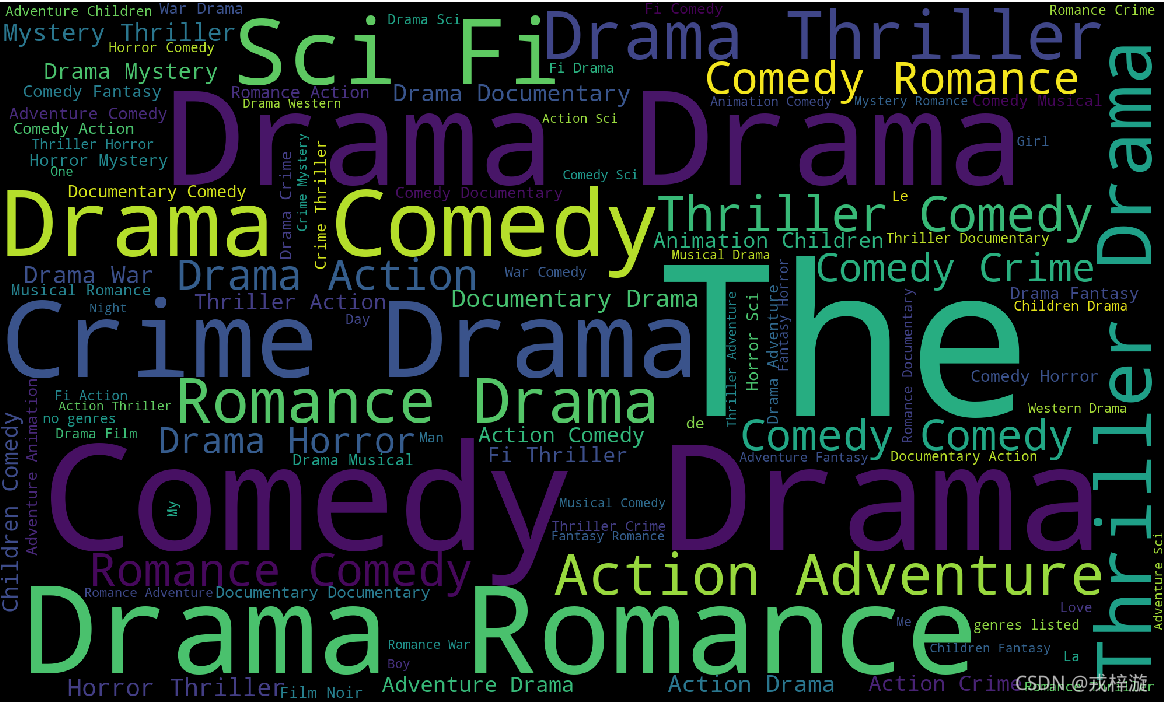
二、生成效果
版权声明:本文为weixin_43817898原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。