10+倍性能提升全过程–优酷账号绑定淘宝账号的TPS从500到5400的优化历程
背景说明
2016年的双11在淘宝上买买买的时候,天猫和优酷土豆一起做了联合促销,在天猫双11当天购物满XXX元就赠送优酷会员,这个过程需要用户在优酷侧绑定淘宝账号(登录优酷、提供淘宝账号,优酷调用淘宝API实现两个账号绑定)和赠送会员并让会员权益生效(看收费影片、免广告等等)
这里涉及到优酷的两个部门:Passport(在上海,负责登录、绑定账号,下文中的优化过程主要是Passport部分);会员(在北京,负责赠送会员,保证权益生效)
在双11活动之前,Passport的绑定账号功能一直在运行,只是没有碰到过大促销带来的挑战
会员部分的架构改造
-
接入中间件DRDS,让优酷的数据库支持拆分,分解MySQL压力
-
接入中间件vipserver来支持负载均衡
-
接入集团DRC来保障数据的高可用
-
对业务进行改造支持Amazon的全链路压测
主要的压测过程

上图是压测过程中主要的阶段中问题和改进,主要的问题和优化过程如下:
- docker bridge网络性能问题和网络中断si不均衡 (优化后:500->1000TPS)- 短连接导致的local port不够 (优化后:1000-3000TPS)- 生产环境snat单核导致的网络延时增大 (优化后能达到测试环境的3000TPS)- Spring MVC Path带来的过高的CPU消耗 (优化后:3000->4200TPS)- 其他业务代码的优化(比如异常、agent等) (优化后:4200->5400TPS)优化过程中碰到的比如淘宝api调用次数限流等一些业务问题就不列出来了
Passport部分的压力
由于用户进来后先要登录并且绑定账号,实际压力先到Passport部分,在这个过程中最开始单机TPS只能到500,经过N轮优化后基本能达到5400 TPS,下面主要是阐述这个优化过程
Passport 核心服务分两个:
-
Login 主要处理登录请求
-
userservice 处理登录后的业务逻辑,比如将优酷账号和淘宝账号绑定
为了更好地利用资源每台物理加上部署三个docker 容器,跑在不同的端口上(8081、8082、8083),通过bridge网络来互相通讯
Passport机器大致结构

说明:这里的500 TPS到5400 TPS是指登录和将优酷账号和淘宝账号绑定的TPS,也是促销活动主要的瓶颈
userservice服务网络相关的各种问题
太多SocketConnect异常(如上图)
在userservice机器上通过netstat也能看到大量的SYN_SENT状态,如下图: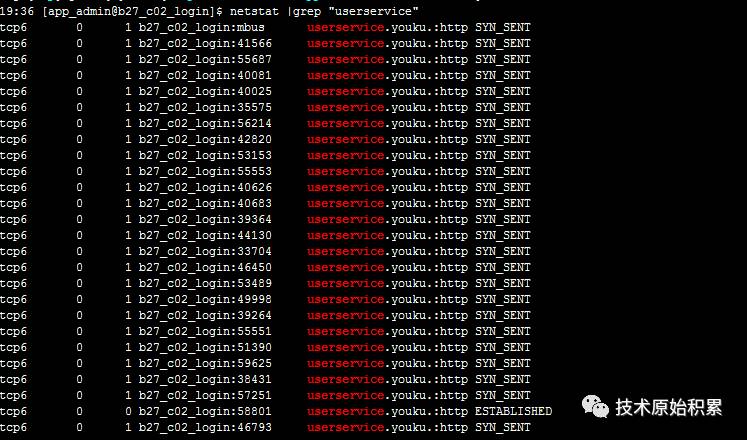
因为docker bridge通过nat来实现,尝试去掉docker,让tomcat直接跑在物理机上
这时SocketConnect异常不再出现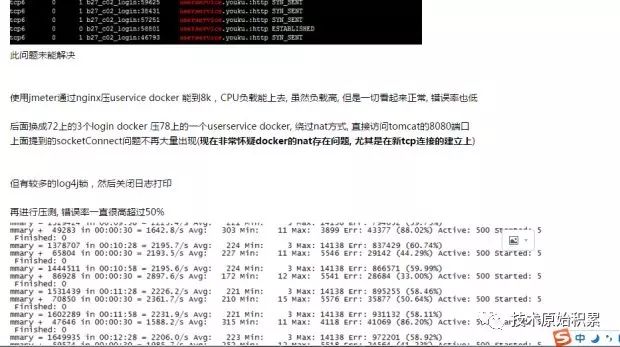
从新梳理一下网络流程
docker(bridge)—-短连接—>访问淘宝API(淘宝open api只能短连接访问),性能差,cpu都花在si上;
如果 docker(bridge)—-长连接到宿主机的某个代理上(比如haproxy)—–短连接—>访问淘宝API, 性能就能好一点。问题可能是短连接放大了Docker bridge网络的性能损耗
当时看到的cpu si非常高,截图如下:
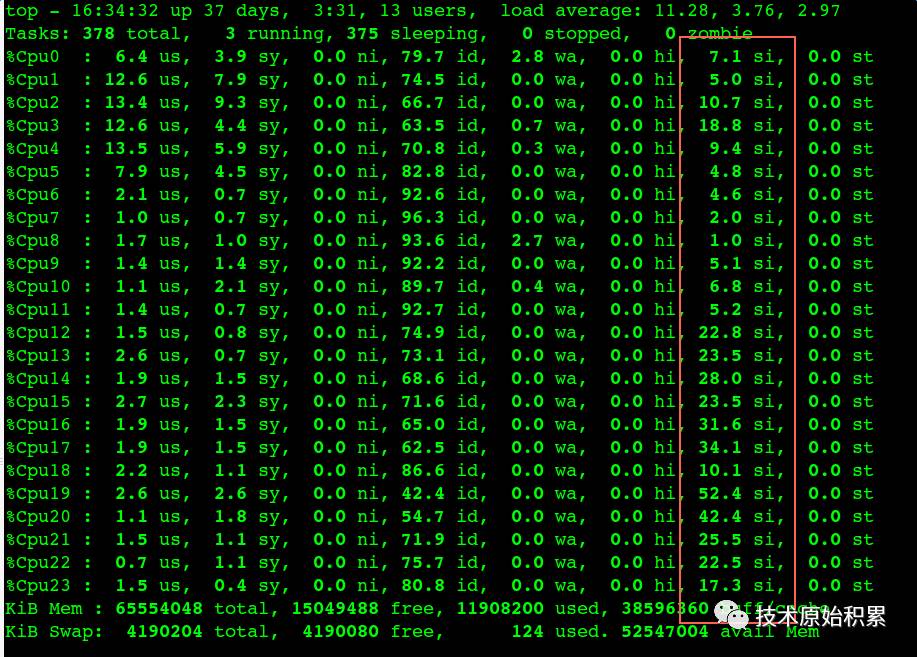
去掉Docker后,性能有所提升,继续通过perf top看到内核态寻找可用的Local Port消耗了比较多的CPU,gif动态截图如下(可以点击看高清大图):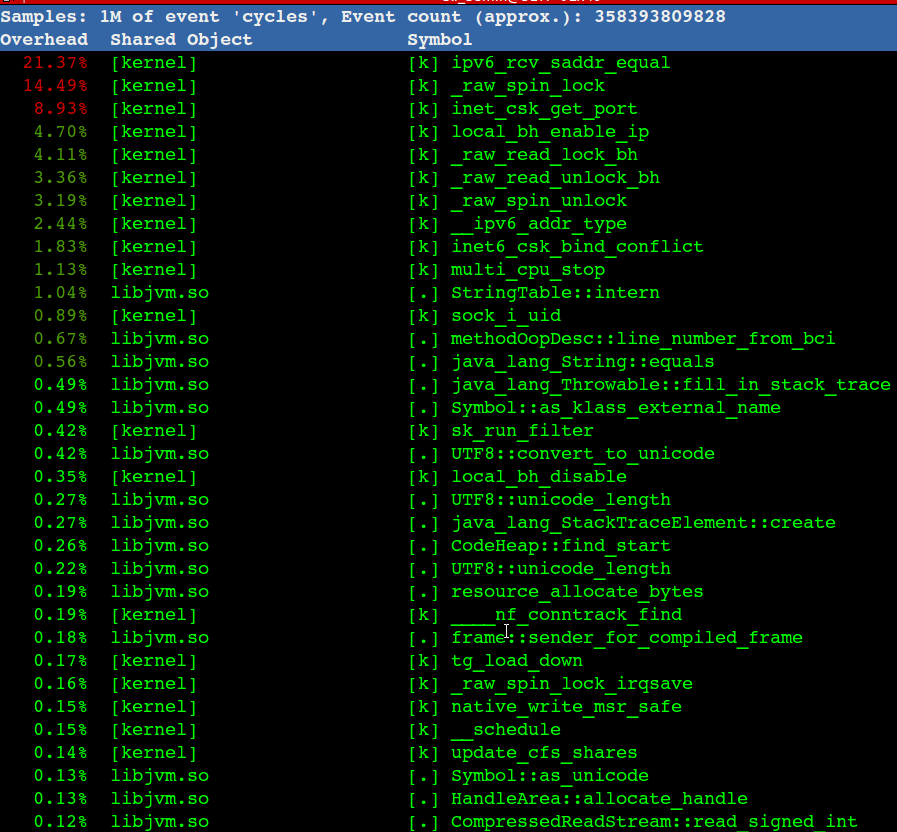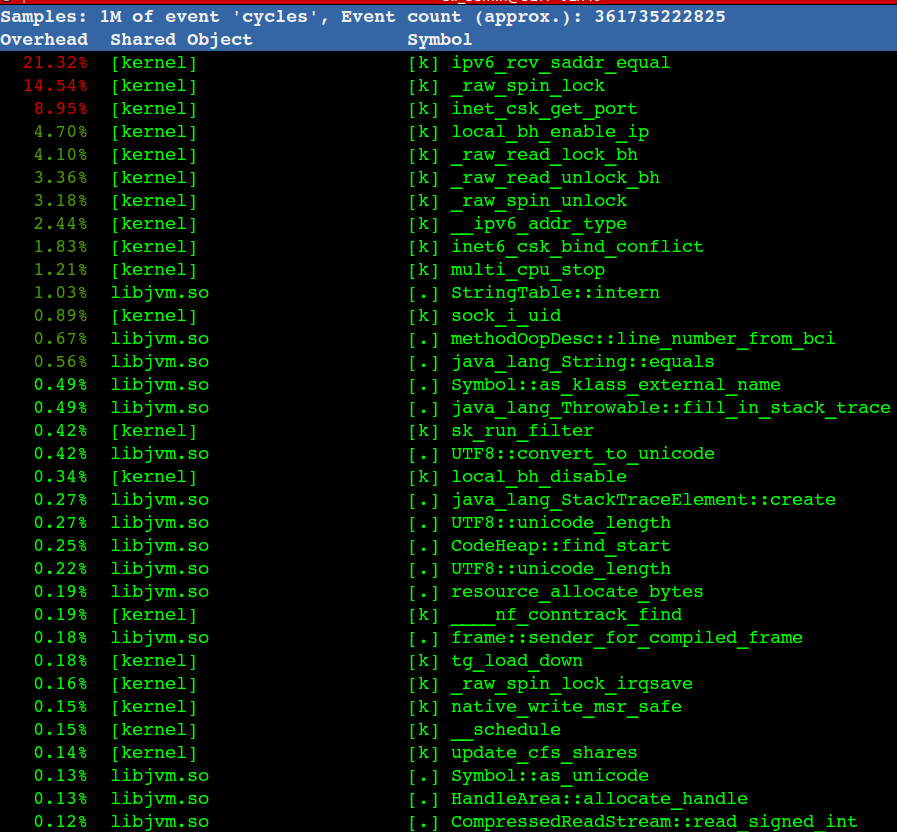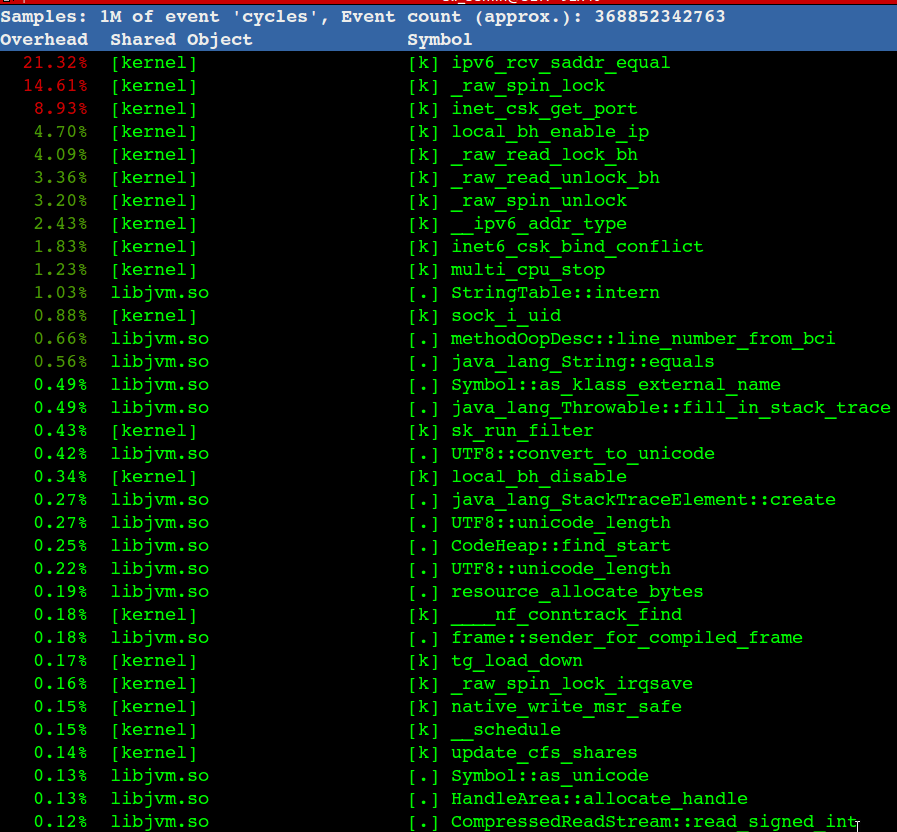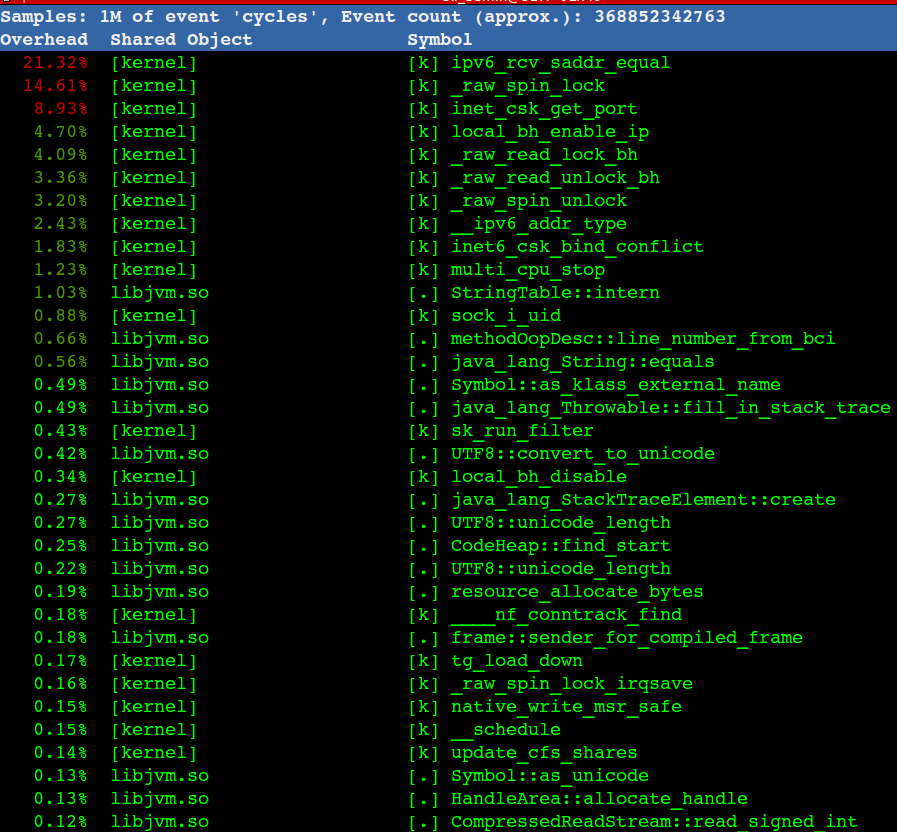
注意图中ipv6_rcv_saddr_equal和inet_csk_get_port 总共占了30%的CPU
一般来说一台机器可用Local Port 3万多个,如果是短连接的话,一个连接释放后默认需要60秒回收,30000/60 =500 这是大概的理论TPS值
同时观察这个时候CPU的主要花在sy上,最理想肯定是希望CPU主要用在us上,截图如下: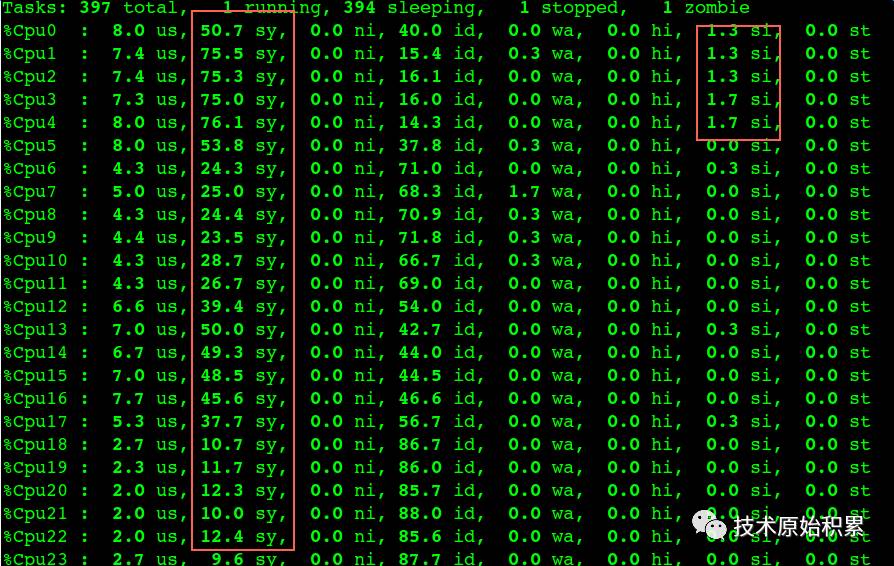
sy占用了30-50%的CPU,这太不科学了,同时通过 netstat 分析连接状态,确实看到很多TIME_WAIT: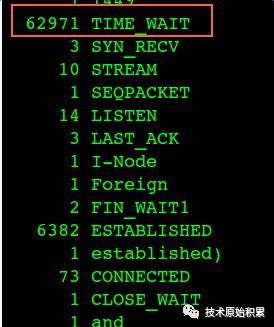
于是让PE修改了tcp相关参数:降低 tcp_max_tw_buckets和开启tcp_tw_reuse,这个时候TPS能从1000提升到3000
优化到3000 TPS后上线继续压测
居然性能又回到了500,太沮丧了,其实最开始账号绑定慢,Passport这边就怀疑taobao api是不是在大压力下不稳定,程序员一般都是认为自己没问题,有问题的一定是对方 :) ,taobao api那边给出调用数据都是1ms以内就返回了(alimonitor监控图表)。
于是怀疑从优酷的机器到淘宝的机器中间链路上有瓶颈,但是需要设计方案来证明这个问题在链路上,要不各个环节都会认为自己没有问题的,当时Passport的开发也只能拿到Login和Userservice这两组机器的权限,中间的负载均衡、交换机都没有权限接触到。
在尝试过tcpdump抓包、ping等各种手段分析后,设计了场景证明问题在中间链路上。
设计如下三个场景证明问题在中间链路上:
-
压测的时候在userservice ping 淘宝的机器;
-
将一台userservice机器从负载均衡上拿下来(没有压力),ping 淘宝的机器;
-
从公网上非优酷的机器 ping 淘宝的机器;
这个时候奇怪的事情发现了,压力一上来场景1、2的两台机器ping淘宝的rt都从30ms上升到100-150ms,场景1 的rt上升可以理解,但是场景2的rt上升不应该,同时场景3中ping淘宝在压力测试的情况下rt一直很稳定(说明压力下淘宝的机器没有问题),到此确认问题在优酷到淘宝机房的链路上有瓶颈,而且问题在优酷机房出口扛不住这么大的压力。于是从上海Passport的团队找到北京Passport的PE团队,确认在优酷调用taobao api的出口上使用了snat,PE到snat机器上看到snat只能使用单核,而且对应的核早就100%的CPU了,因为之前一直没有这么大的压力所以这个问题一直存在只是没有被发现。
于是PE去掉snat,再压的话 TPS稳定在3000左右
到这里结束了吗? 从3000到5400TPS
优化到3000TPS的整个过程没有修改业务代码,只是通过修改系统配置、结构非常有效地把TPS提升了6倍,对于优化来说这个过程是最轻松,性价比也是非常高的。实际到这个时候也临近双11封网了,最终通过计算(机器数量*单机TPS)完全可以抗住双11的压力,所以最终双11运行的版本就是这样的。 但是有工匠精神的工程师是不会轻易放过这么好的优化场景和环境的(基线、机器、代码、工具都具备配套好了)
优化完环境问题后,3000TPS能把CPU US跑上去,于是再对业务代码进行优化也是可行的了。
进一步挖掘代码中的优化空间
双11前的这段封网其实是比较无聊的,于是和Passport的开发同学们一起挖掘代码中的可以优化的部分。这个过程中使用到的主要工具是这三个:火焰图、perf、perf-map-java。相关链接:http://www.brendangregg.com/perf.html ; https://github.com/jrudolph/perf-map-agent
通过Perf发现的一个SpringMVC 的性能问题
这个问题具体参考我之前发表的优化文章http://www.atatech.org/articles/65232 。 主要是通过火焰图发现spring mapping path消耗了过多CPU的性能问题,CPU热点都在methodMapping相关部分,于是修改代码去掉spring中的methodMapping解析后性能提升了40%,TPS能从3000提升到4200.
著名的fillInStackTrace导致的性能问题
代码中的第二个问题是我们程序中很多异常(fillInStackTrace),实际业务上没有这么多错误,应该是一些不重要的异常,不会影响结果,但是异常频率很高,对这种我们可以找到触发的地方,catch住,然后不要抛出去(也就是别触发fillInStackTrace),打印一行error日志就行,这块也能省出10%的CPU,对应到TPS也有几百的提升。

部分触发fillInStackTrace的场景和具体代码行(点击看高清大图):
对应的火焰图(点击看高清大图):

解析useragent 代码部分的性能问题
整个useragent调用堆栈和cpu占用情况,做了个汇总(useragent不启用TPS能从4700提升到5400)
实际火焰图中比较分散:
最终通过对代码的优化勉勉强强将TPS从3000提升到了5400(太不容易了,改代码过程太辛苦,不如改配置来钱快)
优化代码后压测tps可以跑到5400,截图:
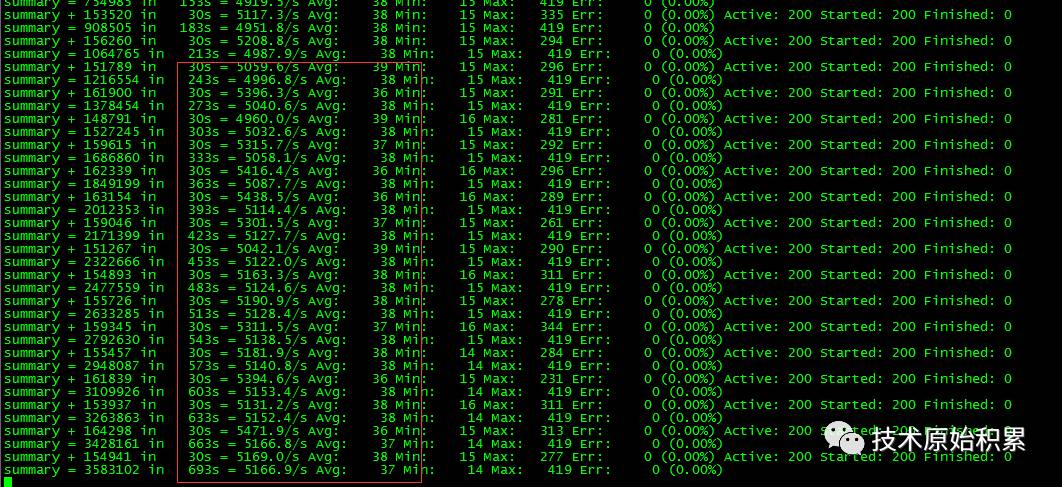
最后再次总结整个压测过程的问题和优化历程
- docker bridge网络性能问题和网络中断si不均衡 (优化后:500->1000TPS)- 短连接导致的local port不够 (优化后:1000-3000TPS)- 生产环境snat单核导致的网络延时增大 (优化后能达到测试环境的3000TPS)- Spring MVC Path带来的过高的CPU消耗 (优化后:3000->4200TPS)- 其他业务代码的优化(比如异常、agent等) (优化后:4200->5400TPS)整个过程得到了淘宝API、优酷会员、优酷Passport、网络、蚂蚁等众多同学的帮助,本来是计划去上海跟Passport的同学一起复盘然后再写这篇文章的,结果一直未能成行,请原谅我拖延到现在才把大家一起辛苦工作的结果整理出来,可能过程中的数据会有一些记忆上的小错误。
此文来自阿里巴巴同事:蛰剑