kPaddleOCR/README_ch.md at release/2.5 · PaddlePaddle/PaddleOCR · GitHub


树编辑距离paper:
GitHub – ibm-aur-nlp/PubTabNet
作者提供了脚本,但是jupter
我复制了一遍,如下:
pred = '<html><body><table><thead><tr><td><b>Name of algori</b></td><td><b>Notablefeatures</b></td></tr></thead><tbody><tr><td>MACS [23]</td><td>Uses both a control library and local statistics to minimize bias</td></tr><tr><td>SICER [15]</td><td>Designed for detecting diffusely enriched regions; for example, histone modification</td></tr><tr><td>PeakSEQ [24]</td><td>Corrects for reference genome mappability and local statistics</td></tr><tr><td>SISSRs [25]</td><td>High resolution, precise identification of binding-site location</td></tr><tr><td>F-seq [26]</td><td>Uses kernel density estimation</td></tr></tbody></table></body></html>'
true = '<html><body><table><thead><tr><td><b>Name of algorithm</b></td><td><b>Notable features</b></td></tr></thead><tbody><tr><td>MACS [23]</td><td>Uses both a control library and local statistics to minimize bias</td></tr><tr><td>SICER [14]</td><td>Designed for detecting diffusely enriched regions; for example, histone modification</td></tr><tr><td>PeakSeq [24]</td><td>Corrects for reference genome mappability and local statistics</td></tr><tr><td>SISSRs [25]</td><td>High resolution, precise identification of binding-site location</td></tr><tr><td>F-seq [26]</td><td>Uses kernel density estimation</td></tr></tbody></table></body></html>'
from metric import TEDS
# Initialize TEDS object
teds = TEDS()
# Evaluate
score = teds.evaluate(pred, true)
print('TEDS score:', score)这两个string,作者只提供了标签,没有提供图片。我们可以直接把标签里面复制到一个html文件中,然后用浏览器打开。
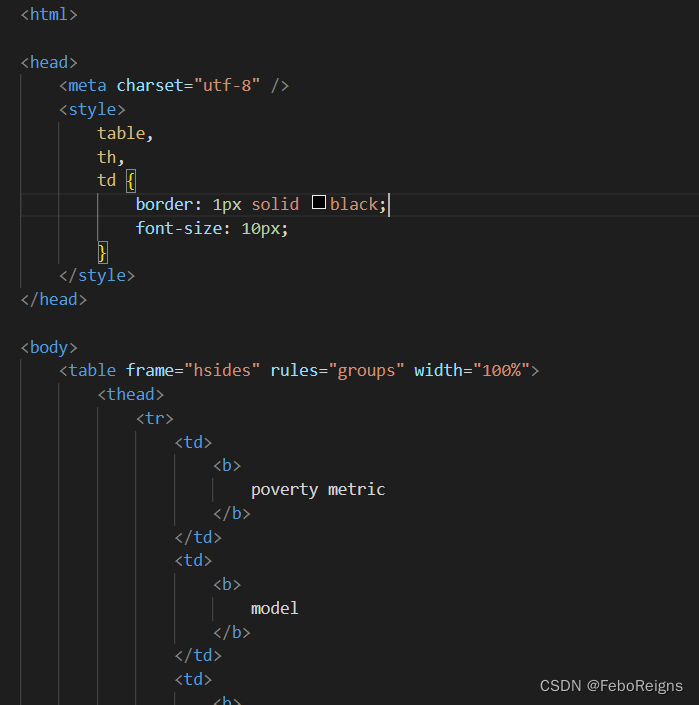
如果你的格式有点乱,可以格式化一下。
我们只关注body 里面的内容。<> 和</>是一对,就像括号一样。thead 是表头,就是下面加黑的那个。tbody是表格身体。tr是一行,td是一个单元格。

下面来说跨行的情况
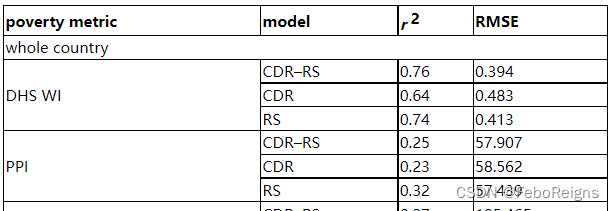
whole country 垮了四列
<tr>
<td colspan="4">
whole country
</td>
</tr>下面是跨行
DHS WI 新开一行 CDR-RS 不新开一行。CDR 和 RS 新开一行。也就是说,是否要新开一行只与上一个单元格的行起点有关系。
<tr>
<td rowspan="3">
DHS WI
</td>
<td>
CDR–RS
</td>
<td>
0.76
</td>
<td>
0.394
</td>
</tr>
<tr>
<td>
CDR
</td>
<td>
0.64
</td>
<td>
0.483
</td>
</tr>
<tr>
<td>
RS
</td>
<td>
0.74
</td>
<td>
0.413
</td>
</tr>上面的图片我是用的作者example文件夹中的,这里不仅有图片还有标签。还有脚本,脚本可以把jason转为HTML格式的字符串。
脚本我运行不了,要改一改
if __name__ == '__main__':
import json
import sys
f = "PubTabNet_Examples.jsonl"
file = open(f, 'r', encoding='utf-8')
for line in file.readlines():
annotations = json.loads(line)
if annotations["imgid"] == 32:
html_string = format_html(annotations)
print(html_string)计算树编辑距离的核心代码就是这里:
PubTabNet/metric.py at master · ibm-aur-nlp/PubTabNet · GitHub
distance = APTED(tree_pred, tree_true, CustomConfig()).compute_edit_distance()
这里核心代码我也不懂,大概意思是作者自定义了一个tree的类,通过递归的方式逐层加载HTML的string,创建出整棵树。然后使用上面那个API计算树的距离。
下面是作者封装的一个树。 tree_true = self.load_html_tree(true)
{
"tag": table{
"tag": thead{
"tag": tr{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['<b>', 'N', 'a', 'm', 'e', ' ', 'o', 'f', ' ', 'a', 'l', 'g', 'o', 'r', 'i', 't', 'h', 'm', '</b>'
]
}{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['<b>', 'N', 'o', 't', 'a', 'b', 'l', 'e', ' ', 'f', 'e', 'a', 't', 'u', 'r', 'e', 's', '</b>'
]
}
}
}{
"tag": tbody{
"tag": tr{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['M', 'A', 'C', 'S', ' ', '[', '2', '3', '
]'
]
}{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['U', 's', 'e', 's', ' ', 'b', 'o', 't', 'h', ' ', 'a', ' ', 'c', 'o', 'n', 't', 'r', 'o', 'l', ' ', 'l', 'i', 'b', 'r', 'a', 'r', 'y', ' ', 'a', 'n', 'd', ' ', 'l', 'o', 'c', 'a', 'l', ' ', 's', 't', 'a', 't', 'i', 's', 't', 'i', 'c', 's', ' ', 't', 'o', ' ', 'm', 'i', 'n', 'i', 'm', 'i', 'z', 'e', ' ', 'b', 'i', 'a', 's'
]
}
}{
"tag": tr{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['S', 'I', 'C', 'E', 'R', ' ', '[', '1', '4', '
]'
]
}{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['D', 'e', 's', 'i', 'g', 'n', 'e', 'd', ' ', 'f', 'o', 'r', ' ', 'd', 'e', 't', 'e', 'c', 't', 'i', 'n', 'g', ' ', 'd', 'i', 'f', 'f', 'u', 's', 'e', 'l', 'y', ' ', 'e', 'n', 'r', 'i', 'c', 'h', 'e', 'd', ' ', 'r', 'e', 'g', 'i', 'o', 'n', 's', ';', ' ', 'f', 'o', 'r', ' ', 'e', 'x', 'a', 'm', 'p', 'l', 'e', ',', ' ', 'h', 'i', 's', 't', 'o', 'n', 'e', ' ', 'm', 'o', 'd', 'i', 'f', 'i', 'c', 'a', 't', 'i', 'o', 'n'
]
}
}{
"tag": tr{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['P', 'e', 'a', 'k', 'S', 'e', 'q', ' ', '[', '2', '4', '
]'
]
}{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['C', 'o', 'r', 'r', 'e', 'c', 't', 's', ' ', 'f', 'o', 'r', ' ', 'r', 'e', 'f', 'e', 'r', 'e', 'n', 'c', 'e', ' ', 'g', 'e', 'n', 'o', 'm', 'e', ' ', 'm', 'a', 'p', 'p', 'a', 'b', 'i', 'l', 'i', 't', 'y', ' ', 'a', 'n', 'd', ' ', 'l', 'o', 'c', 'a', 'l', ' ', 's', 't', 'a', 't', 'i', 's', 't', 'i', 'c', 's'
]
}
}{
"tag": tr{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['S', 'I', 'S', 'S', 'R', 's', ' ', '[', '2', '5', '
]'
]
}{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['H', 'i', 'g', 'h', ' ', 'r', 'e', 's', 'o', 'l', 'u', 't', 'i', 'o', 'n', ',', ' ', 'p', 'r', 'e', 'c', 'i', 's', 'e', ' ', 'i', 'd', 'e', 'n', 't', 'i', 'f', 'i', 'c', 'a', 't', 'i', 'o', 'n', ' ', 'o', 'f', ' ', 'b', 'i', 'n', 'd', 'i', 'n', 'g', '-', 's', 'i', 't', 'e', ' ', 'l', 'o', 'c', 'a', 't', 'i', 'o', 'n'
]
}
}{
"tag": tr{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['F', '-', 's', 'e', 'q', ' ', '[', '2', '6', '
]'
]
}{
"tag": td,
"colspan": 1,
"rowspan": 1,
"text": ['U', 's', 'e', 's', ' ', 'k', 'e', 'r', 'n', 'e', 'l', ' ', 'd', 'e', 'n', 's', 'i', 't', 'y', ' ', 'e', 's', 't', 'i', 'm', 'a', 't', 'i', 'o', 'n'
]
}
}
}
}