cat
展示文件的内容
more
more file
可以按空格往下翻
不能翻回去
less
会把文件加载到内存中
因此可以上下来回看
b enter q退出
head
head file
head 默认可以输出前10行
head -num file查看前几行
tail
tail file
默认打印后10行
tail -num file查看后几行
tail -f file打印追加的文件,可以监控日志文件
echo “xx” >>file
管道
cat b.txt | head -3
echo “/” | ls
– 当前列表下的文件信息
看某个文件第五行怎么看?
head -5 file | tail -1
VI
全屏编辑器:
vim /path/to/somefile
vim +# :打开文件,并定位于第#行
vim +:打开文件,定位至最后一行
vim +/PATTERN : 打开文件,定位至第一次被PATTERN匹配到的行的行首
关闭文件
末行模式:
:q 退出 没有动过文件
:wq 保存并退出 动过了,不后悔
:q! 不保存并退出 动过了,后悔了
:w 保存
:w! 强行保存
:wq --> :x
set nu 打开行号
shift +ZZ: 保存并退出 不需要冒号,编辑模式
有三种模式:
编辑模式:按键具有编辑文本功能:默认打开进入编辑模式
输入模式:按键本身意义
末行模式:接受用户命令输入
编辑模式-》输入模式:
i: 在当前光标所在字符的前面,转为输入模式;
a: 在当前光标所在字符的后面,转为输入模式;
o: 在当前光标所在行的下方,新建一行,并转为输入模式;
O:在当前光标所在行的上方,新建一行,并转为输入模式;
I:在当前光标所在行的行首,转换为输入模式
A:在当前光标所在行的行尾,转换为输入模式
输入-》编辑
ESC
编辑–>末行:
:
末行-》编辑:
ESC,ESC
输入模式不能进到末行模式
编辑模式
-
字符
hjkl也可以移动光标 -
单词
w: 移至下一个单词的词首 e: 跳至当前或下一个单词的词尾 b: 跳至当前或前一个单词的词首
行内
0: 绝对行首
^: 行首的第一个非空白字符
$: 绝对行尾
-
行间
G:文章末尾 3G:第3行 gg:文章开头 -
翻屏
ctrl:f,b -
删除&替换单个字符
x:删除光标位置字符 3x:删除光标开始3个字符 r:替换光标位置字符 -
删除命令 : d
dw,dd 4dw删除字母 4dd 删除行 -
复制粘贴&剪切
yw 复制一个单词 yy 复制一整行 p 粘贴 P 在这一行的上边粘贴 dd剪切 3yw 复制三个单词 -
撤销&重做
u 撤销 ctrl+r 重做 撤销的操作 . 重复上一步的操作
末行模式
-
set:设置
set nu number set nonu nonumber set readonly 只在当前环境下有效,跟外边的权限没有关系 set noreadonly -
/:查找
/:after (单词所在行行首) /after (单词行首) n,N 翻页 ?向上查找 -
!:执行命令
:!ls -l / 例如当配置JAVA_HOME 时不用新建窗口就能知道路径 -
s查找并替换
s/str1/str2/gi 查找的字符串 替换的字符串 模式 /:临近s命令的第一个字符为边界字符:/,@,#(当用搜索的字符中有/时可以使用###) g:一行内全部替换(如果不加这个的话,就只替换这一行的第一个) i:忽略大小写 需要加范围才能使用 n:行号 .:当前光标行 +n:偏移n行 $:末尾行,$-3 %:全文 .,$s/after/before/gi
dG全部删除
., $-2d从当前行开始删剩下两行
1, $-2从第一行删到末尾剩下两行
3,9y复制
粘贴p
正则表达式
-
grep:显示匹配行
v:反显示 e:使用扩展正则表达式 -
匹配操作符
\ 转义字符 . 匹配任意单个字符 [1249a],[^12],[a-k] 字符序列单字符占位,非12以外的字符,a到k之间的字符 ^ 行首 $ 行尾 \<,\>:\<abc 单词首尾边界 | 连接操作符 (,) 选择操作符 \n 反向引用 -
重复操作符:
? 匹配0到1次。 * 匹配0到多次。 + 匹配1到多次。 {n} 匹配n次。 {n,} 匹配n到多次。 {n,m} 匹配n到m次。 与扩展正则表达式的区别:grep basic \?, \+, \{, \|, \(, and \) 匹配任意字符 .*(非空)
数据
ooxx12121212ooxx
ooxx 12121212
oox 12121212
1212 ooxx 1212
oo3xx
oo4xx
ooWxx
oomxx
$ooxx
oo1234xx
ooxyzxx

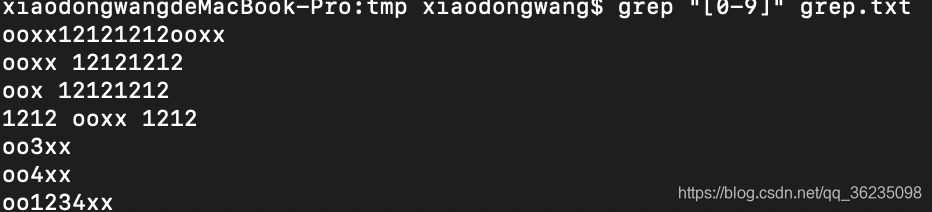



当做

包含单词的行

只包含4位数字的行

列举法

aaabbcaaa
aa bbc aaa
bb bbc bbb
asgodssgoodsssagodssgood
asgodssgoodsssagoodssgod
sdlkjflskdjf3slkdjfdksl
slkdjf2lskdjfkldsjl
匹配 第三行
grep ".*\(god\).*\(good\).*\1.*\2" test
\1就是第一个括号
\2就是第二个括号
版权声明:本文为qq_36235098原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。