文章目录
第五章 PPO
From On-policy to Off-policy
- 如果要学习的 agent 跟和环境互动的 agent 是同一个的话, 这个叫做
on-policy(同策略)。 - 如果要学习的 agent 跟和环境互动的 agent 不是同一个的话, 那这个叫做
off-policy(异策略)。
policy gradient就是on-policy,必须要收集到很多
τ
\tau
τ,然后更新式子,非常耗时。变成off-policy:使用另一个actor
θ
′
\theta’
θ′跟环境互动,用收集到的数据训练
θ
\theta
θ。这样可以重复使用采样到的数据。
近端策略优化(Proximal Policy Optimization,简称 PPO) 是 policy gradient 的一个变形,它是现在 OpenAI 默认的强化学习算法。
Importance Sampling
对于ー个随机变量,通常用概率密度函数来刻画该变量的概率分布特性。具体来说,给定随机变量的一个取值,可以根据概率密度函数来计算该值对应的概率(密度)。反过来,也可以根据概率密度函数提供的概率分布信息来生成随机变量的一个取值,这就是采样。因此,从某种意义上来说,采样是概率密度函数的逆向应用。与根据概率密度函数计算样本点对应的概率值不同,采样过程往往没有那么直接,通常需要根据待采样分布的具体特点来选择合适的采样策略。
没有办法在p上做采样:通过在q做采样,乘上重要性权重(importance weight)
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x)来修正差异。
但是
p
(
x
)
p(x)
p(x)和
q
(
x
)
q(x)
q(x)差距很大会出问题。
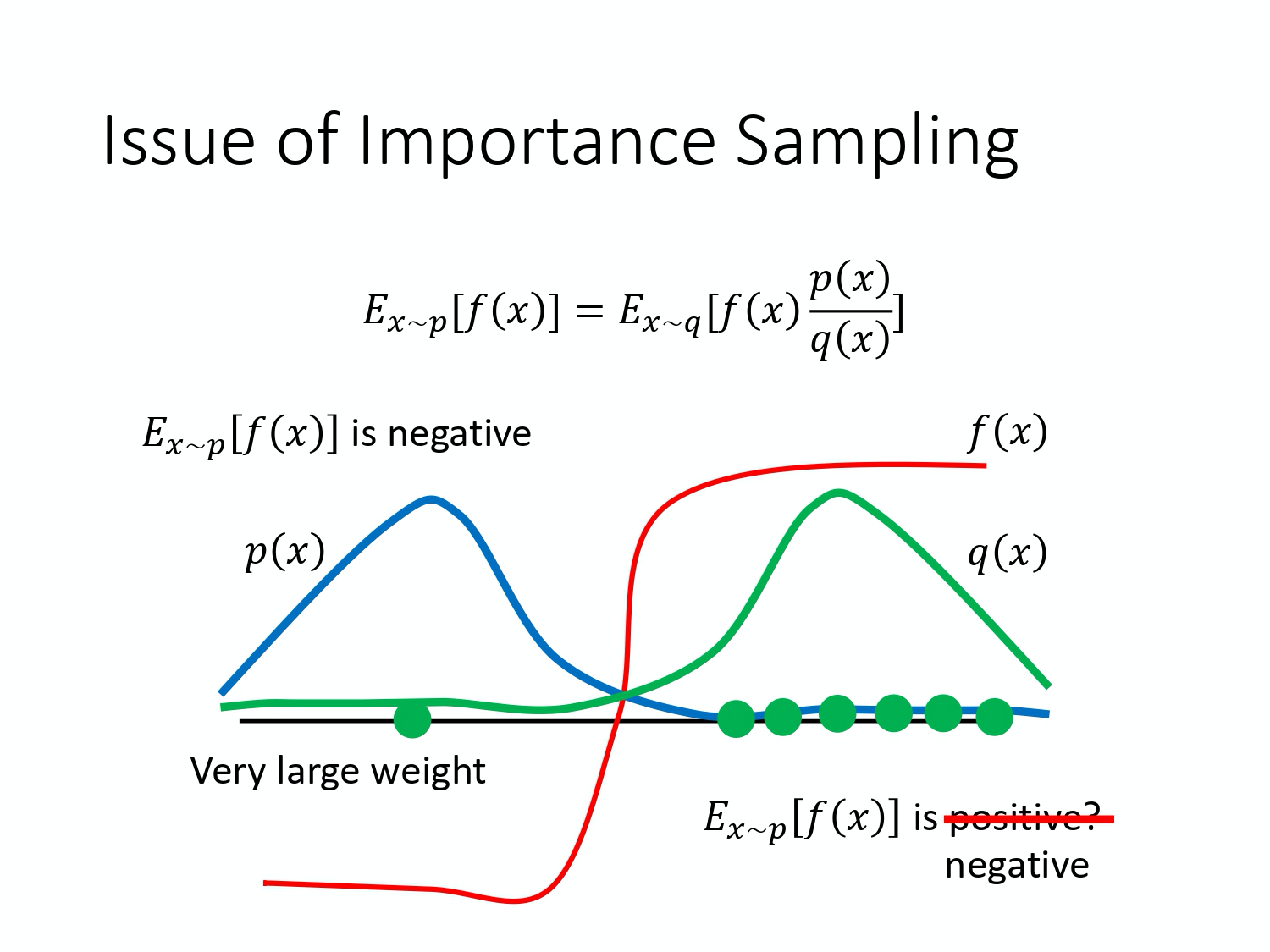
将重要性采样用在off-policy上:

-
θ
′
\theta’
θ′与环境做互动,将数据给θ
\theta
θ,只需要训练θ
\theta
θ。需要一个修正项~
这样的话,就可以采集到一大堆数据,让θ
\theta
θ更新很多次哦~ - 图中,对公式进行了拆解,消掉了一项(因为不好计算)。
PPO
- 解决
p
θ
(
a
t
∣
s
t
)
p_{\theta}(a_t|s_t)
pθ(at∣st)跟p
θ
′
(
a
t
∣
s
t
)
p_{\theta’}(a_t|s_t)
pθ′(at∣st)分布差太多的问题。 - PPO是on-policy的算法,因为
θ
′
\theta’
θ′是θ
o
l
d
\theta_{old}
θold,并且是基于actor-critic的,可以在连续(continue)和离散(discrete)空间上起作用。
important sampling不能算是off-policy,PPO里面的 important sampling采样的过程仍然是在同一个策略生成的样本,并未使用其他策略产生的样本,因此它是on-policy的。而DDPG这种使用其他策略产生的数据来更新另一个策略的方式才是off-policy
- 方法:在训练的时候,多加一个约束(KL divergence)。

PPO的前身:信任区域策略优化(Trust Region Policy Optimization,TRPO)
J
T
R
P
O
′
θ
′
(
θ
)
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
\mathrm{J}_{\mathrm{TRPO}^{\prime}}^{\theta^{\prime}}(\theta)=\mathrm{E}_{(\mathrm{st}, \mathrm{at}) \sim \pi_{\theta^{\prime}}}\left[\frac{\mathrm{p}_{\theta}\left(\mathrm{a}_{\mathrm{t}} \mid \mathrm{s}_{\mathrm{t}}\right)}{\mathrm{p}_{\theta^{\prime}}\left(\mathrm{a}_{\mathrm{t}} \mid \mathrm{s}_{\mathrm{t}}\right)} \mathrm{A}^{\theta^{\prime}}\left(\mathrm{s}_{\mathrm{t}}, \mathrm{a}_{\mathrm{t}}\right)\right]
JTRPO′θ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
K
L
(
θ
,
θ
′
)
<
δ
\mathrm{KL}\left(\theta, \theta^{\prime}\right)<\delta
KL(θ,θ′)<δ
- 它与 PPO 不一样的地方是约束摆的位置不一样:① PPO 是直接把约束放到你要优化的那个式子里面,然后你就可以用梯度上升的方法去最大化这个式子。② 但 TRPO 是把 KL 散度当作约束,它希望
θ
\theta
θ 跟θ
\theta
θ 的 KL 散度小于一个δ
\delta
δ。如果你使用的是基于梯度的优化时,有约束是很难处理的。 - KL散度,是衡量动作上的距离(给定同样的state,输出action差距小)而非参数上的距离。
变种1:PPO-Penalty
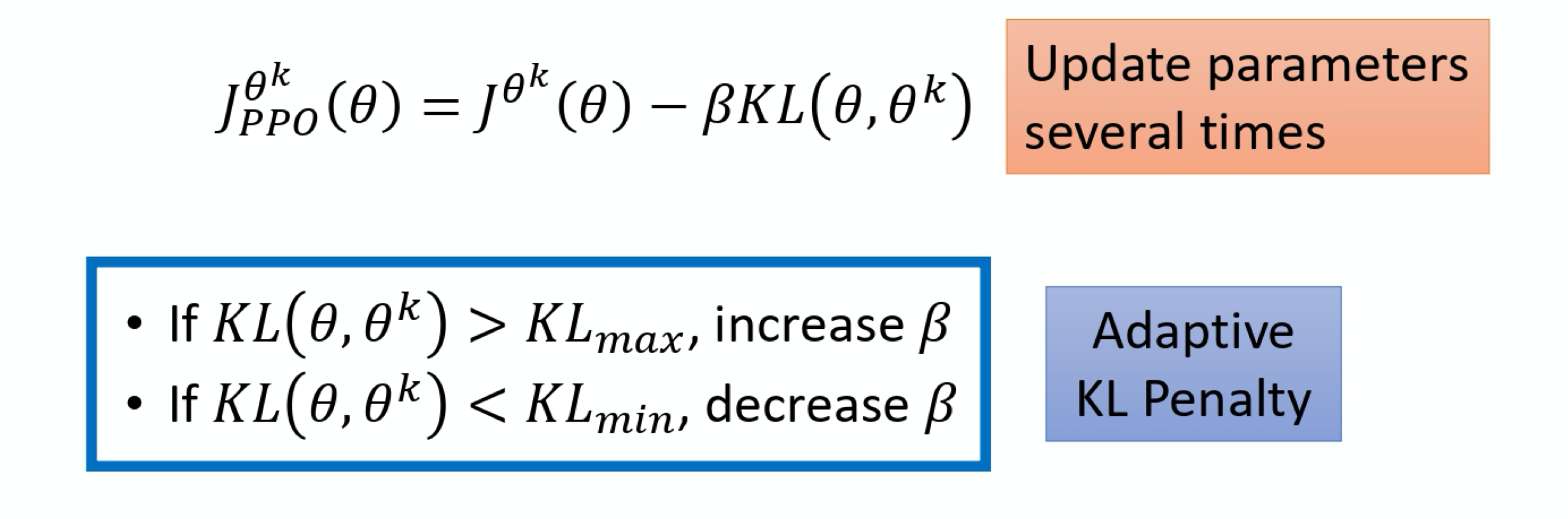
β
\beta
β怎么设置的问题:设置一个可以接受的KL散度的最大值/最小值,再动态调整。adaptive KL penalty
变种2:PPO-Clip
这是现在最常用的PPO算法啦!其中涉及到的优势函数
A
π
(
s
,
a
)
=
Q
π
(
s
,
a
)
−
V
π
(
s
)
A^{\pi}(s,a) = Q^{\pi}(s,a)-V^{\pi}(s)
Aπ(s,a)=Qπ(s,a)−Vπ(s),用的是GAE的方法。
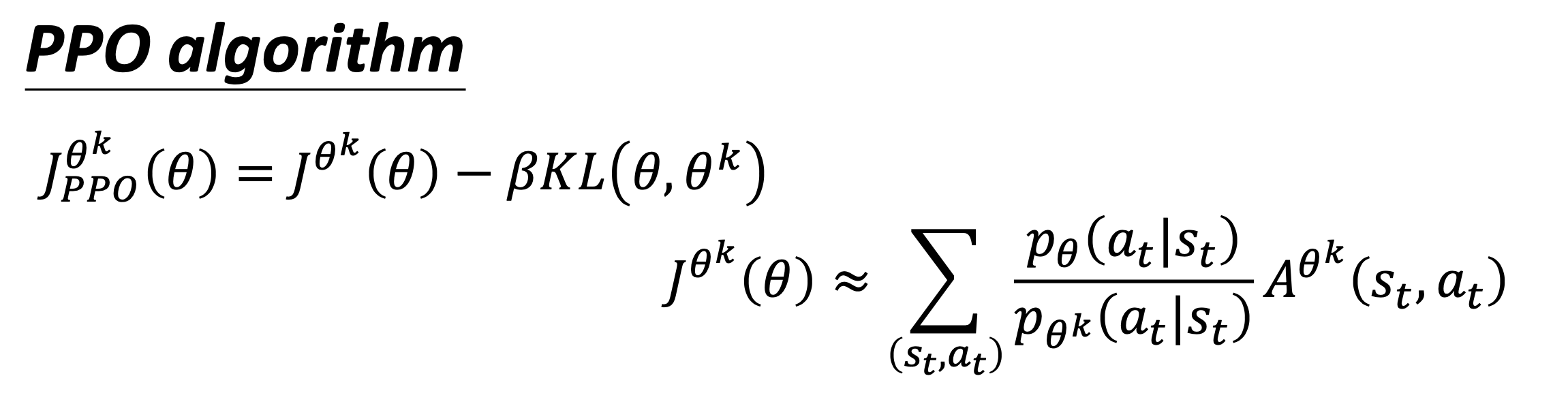
-
去掉了KL散度。PPO2 要去最大化的目标函数如下式所示,它的式子里面就没有 KL 散度:
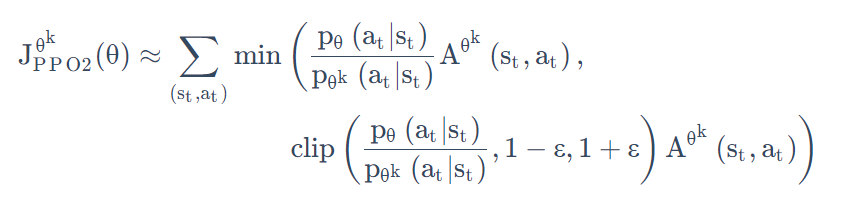
-
利用clip函数将其固定在了一定的范围之内,同样也可以起到限制约束。
Summary:
- on-policy的可改进之处:sample数据很耗时,并且sample一次只能更新一次,又要重新收集data
- important sampling注意点:两个分布不能差太多
- 重要性采样:使用另外一种数据分布,来逼近所求分布的一种方法,算是一种期望修正的方法
- 重要性采样和off-policy是不一样的!在强化学习中,为什么TRPO和PPO算法属于On-Policy的算法?
代码
PPO是对PG的改进(
θ
′
\theta’
θ′与环境互动产生数据,更新
θ
\theta
θ),代码实现方面:
- (1)PG必须要一整个
episode结束(done),通常要存储好几个回合的数据(pool中),才能计算G
t
G_t
Gt,然后套公式更新参数;然后再将pool=[ ],重新玩很多轮,更新… 这样子更新是非常耗时的!辛辛苦苦sample了这么久,更新一次就不用了,又要重新收集,很麻烦。 - (2)PPO不需要等到episode全部结束,玩了几次就可以update参数了。
PPO-Clip算法:
① agent包含了一个actor(输入state,经过MLP+softmax,产生action概率distribution)和critic(输入state,经过MLP,输出分数value)。
②choose_action时,输入state,返回action, probs, value(critic输出)。这三个|| state, reward, done 存入memory。
③ 交互几次后,就需要从memory中取出数据,对每个reward计算advantage(GAE),分batch更新参数了(刚刚存的一批数据会更新参数好几次):从memory中取出的pro记作old_pro;将state再次传入actor和critic,获得new_pro(并没有生成新action,只是重新算了一下pro)以及critic_value;计算重要性权重n
e
w
_
p
r
o
.
e
x
p
(
)
o
l
d
_
p
r
o
.
e
x
p
(
)
∗
a
d
v
a
n
t
a
g
e
\frac{new\_pro.exp()}{old\_pro.exp()}*advantage
old_pro.exp()new_pro.exp()∗advantage。
④ 计算actor(下面这个公式)和critic(就是使得critic的结果和Q值尽量相近,advantage function会用到)的损失,再更新。
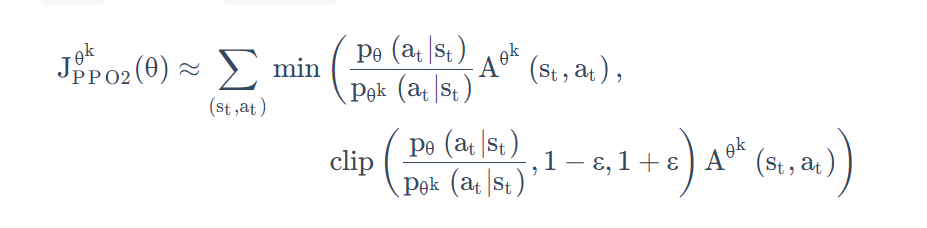
Categorical:按照传入的probs中给定的概率,在相应的位置处进行取样,.sample()采样返回该位置的整数索引。- tensor转numpy:
.numpy
pro = torch.tensor([0.4,0.8,0.1])
dist = Categorical(pro)
dist
Out[4]: Categorical(probs: torch.Size([3]))
index = dist.sample()
index
Out[6]: tensor(2)
index.numpy()
Out[7]: array(2, dtype=int64)
torch.clamp(input, min, max, out=None)将输入input张量每个元素的缩放到区间 [min,max][min,max],并返回结果到一个新张量。(大于max设为max,小于min设为min)
tianshou code
set.union(set1, set2...):返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。->是为了告诉用户 具体参数和参数的类型lambda函数: g = lambda x:x+1 相当于定义了一个匿名函数getattr(object, name[, default])返回一个对象属性值。
第六章 DQN
传统的Q-learning使用表格形式存储状态价值函数
V
(
s
)
V(s)
V(s)或者动作价值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a),对连续状态空间不适用。
使用价值函数近似(Value Function Approximation)
Q
ϕ
(
s
,
a
)
Q^{\phi}(s,a)
Qϕ(s,a)表示近似计算,它通常是一个参数为
ϕ
\phi
ϕ的函数(比如神经网络),称为Q-network。
State Value Function
value-based:学习一个critic,用于评估actor的策略π
\pi
π好坏,即Policy Evaluation。
DQN 是指基于深度学习的 Q-learning 算法,主要结合了
价值函数近似(Value Function Approximation)与神经网络技术,并采用了目标网络和经历回放的方法进行网络的训练。
- critic既可以是
Q
(
s
,
a
)
Q(s,a)
Q(s,a)也可以是V
(
s
)
V(s)
V(s),这里先讨论state value function。就是,输入一个状态s,输出一个标量,表示actor的策略为π
\pi
π时,当前状态下,未来收益可以是多大。 - 一个critic一定对应一个actor,它衡量的实际是actor好坏,并不是状态的好坏。

State Value Function Estimation
如何衡量状态价值函数
V
π
(
s
)
V^{\pi}(s)
Vπ(s):MC-based,TD-based
MC-based:actor与environment互动(玩完一整个游戏),产生累积奖励,告诉critic。相当于一个回归问题。Temporal-difference(时序差分):V
π
(
s
t
)
=
V
π
(
s
t
+
1
)
+
r
t
V^{\pi}(s_t) = V^{\pi}(s_{t+1})+r_t
Vπ(st)=Vπ(st+1)+rt。只需要知道(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s_t,a_t,r_t,s_{t+1})
(st,at,rt,st+1)。训练的时候,希望输入s
t
s_t
st和s
t
+
1
s_{t+1}
st+1,对应的输出相差r
t
r_t
rt。- MC VS. TD : MC方差很大(游戏本身就具有随机性)。
State-action Value Function(Q-function)
- 刚刚讨论的是
state value function,即critic为V
(
s
)
V(s)
V(s)时。这里我们讨论另一种critic,Q-function,也称为state-action value function。
- 状态价值函数的输入是一个状态,它是根据状态去计算出,看到这个状态以后的期望的累积奖励( expected accumulated reward)是多少。
- 状态-动作价值函数的输入是一个状态、动作对,它的意思是说,在某一个状态采取某一个动作,假设我们都使用演员 π ,得到的累积奖励的期望值有多大。
- Q-function有两种写法:
- 输入是状态跟动作,输出就是一个标量;
- 输入是一个状态,输出就是好几个值。
- 我们学习到了Q-function后,就可以决定要采取哪个动作,可以进行
策略改进(Policy Improvement)。找到更好的策略:π
′
(
s
)
=
a
r
g
max
a
Q
π
(
s
,
a
)
{\pi}'(s) = arg\max_{a} Q^{\pi}(s,a)
π′(s)=argmaxaQπ(s,a) - 这边要注意一下,给定这个状态 s,你的策略 π 并不一定会采取动作a,我们是给定某一个状态 s 强制采取动作 a,用 π 继续互动下去得到的期望奖励,这个才是 Q-function 的定义。
Target Network
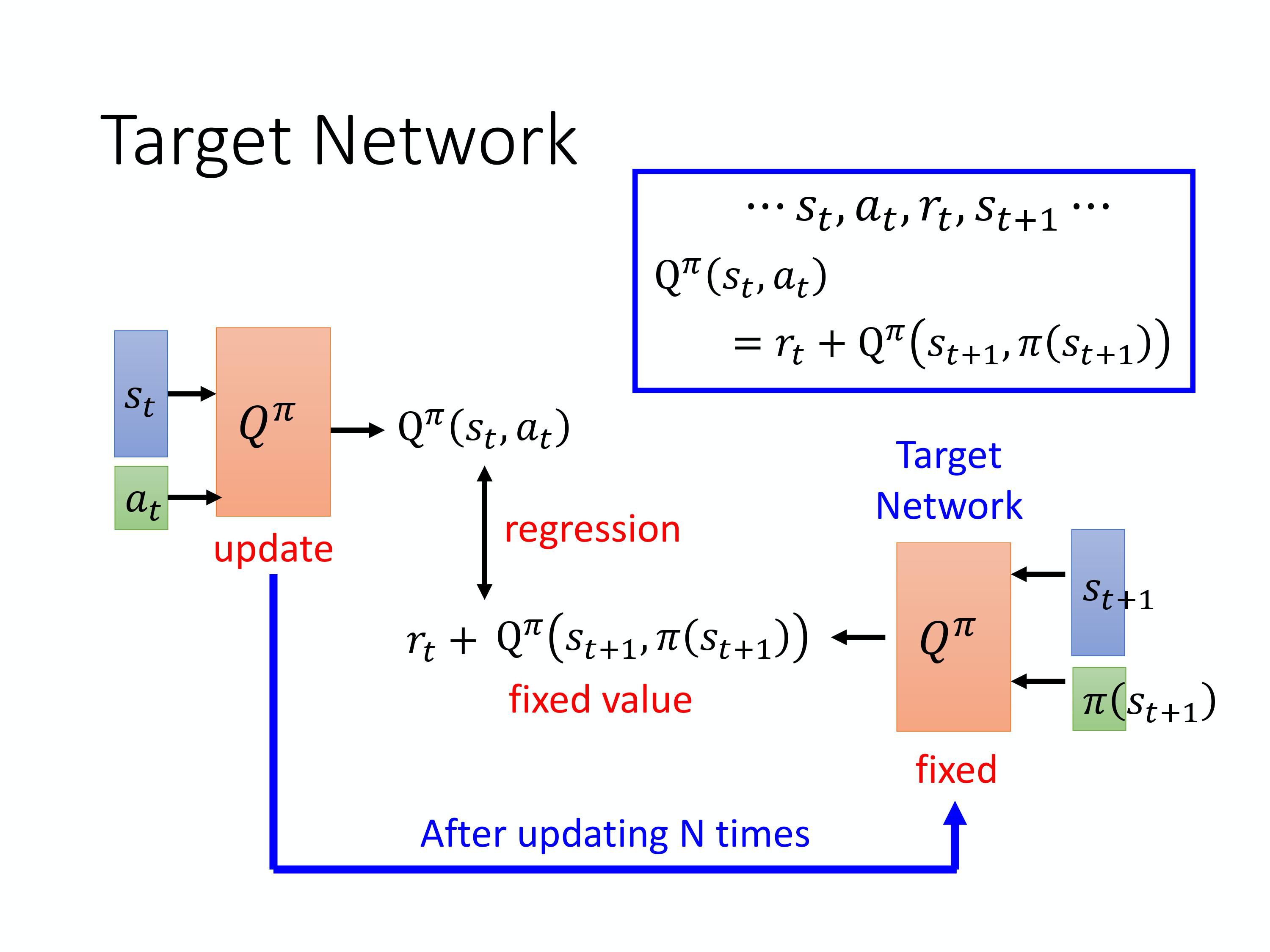
- 因为在学习Q-function的时候也会用到TD的概念
- target 在动,模型训练不稳定,拟合的目标一直在变;(有点像猫捉老鼠,猫是Q estimation,老鼠是Q target;猫和老鼠一起跑,就不好优化了,而且训练不稳定;因此我们固定一下老鼠,隔几步才动,就可以慢慢拟合了。)
- 因此我们会固定住一个网络,专门用于产生目标。在更新左边网络好几次后,再去替换目标网络。
Exploration
和PG输出动作分布不一样,Q-function输出能让Q最大的action。这样的话action就固定了,都不知道其他action好坏。
Epsilon Greedy:ε
\varepsilon
ε随着训练次数慢慢变小。Boltzmann Exploration:类似PG,根据Q值去定一个概率分布。
Experience Replay
- 构建一个
Replay Buffer / Replay Memory,有一个策略π
\pi
π与环境互动,收集数据将其存在buffer中。 - replay buffer里的经验可能来自不同的策略,装满之后会把旧数据丢掉。
- 训练的时候,每次从buffer挑一个batch更新。
- 属于
off-policy,因为replay buffer里的经验可能来自于其他策略。
DQN
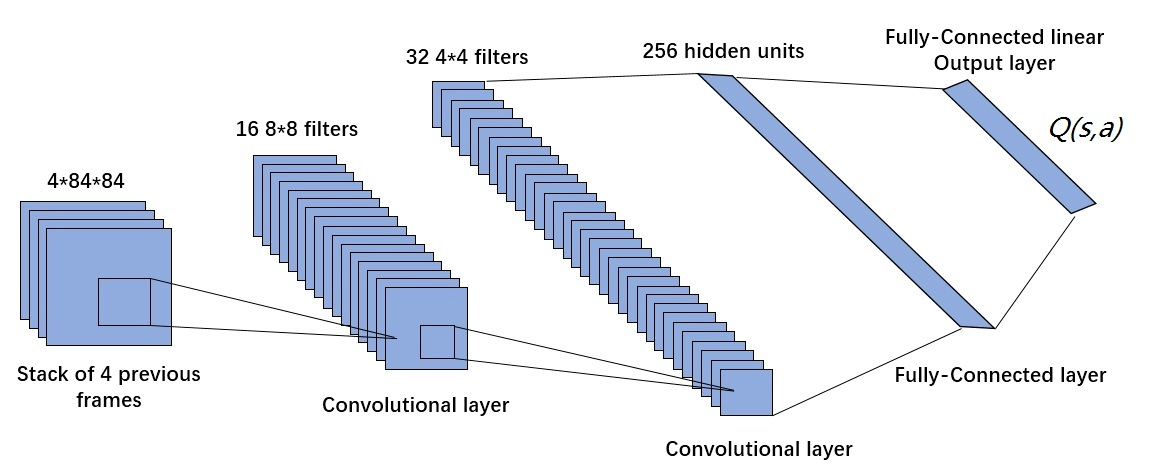
- 使用深度卷积神经网络拟合状态动作值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a),DQN 模型的输入是距离当前时刻最近的 4 帧图像,该输入经过 3 个卷积层和 2 个全连接层的非线性变化后,最终在输出层输出每个动作对应的 Q 值。

与Q-learning区别:
- DQN 将 Q-learning 与深度学习结合,用深度网络来近似动作价值函数,而 Q-learning 则是采用表格存储;
- DQN 采用了经验回放的训练方法,从历史数据中随机采样,而 Q-learning 直接采用下一个状态的数据进行学习。
代码
- DQN包含两个network:policy_net, target_net;有一个ReplayBuffer
- choose_action时,以
1
−
ϵ
1-\epsilon
1−ϵ概率选择policy_net(state)最大值的action,ϵ
\epsilon
ϵ概率随机选择。 - 一次交互,存储
(state, action, reward, next_state, done) - 有
batch_size条数据后,update。使用policy_net计算当前state对应的Q-value,使用target_net计算下一个state对应的Q-value。根据TD计算loss,更新policy_net。
on-policy与off-policy区别:更新值函数时是否只使用当前策略所产生的样本.
- DQN有两个网络,
policy_net和target_net。off-policy,因为有两个agent,一个表示当前policy,一个表示目标policy。replay buffer中存储的是很多历史样本,更新Q函数时的target用的样本是从这些样本中采样而来,因此更新时使用的可能是历史样本。(memory不会定时清理,只有达到容量上限时,会除掉开始的数据) - PPO也有两个网络,
actor和critic。on-policy,因为学习的 agent 跟和环境互动的 agent是同一个。并且用于更新的样本是当前策略产生的样本。也有memory,不过更新一次就会clear。
总结
- 高冷的面试官:请问不打破数据相关性,神经网络的训练效果为什么就不好?
- 答:在神经网络中通常使用随机梯度下降法。随机的意思是我们随机选择一些样本来增量式的估计梯度,比如常用的 采用batch训练。如果样本是相关的,那就意味着前后两个batch的很可能也是相关的,那么估计的梯度也会呈现 出某种相关性。如果不幸的情况下,后面的梯度估计可能会抵消掉前面的梯度量。从而使得训练难以收敛。