0. 说明
该文件记录的是平时工作中临时用到的但是对我很重要的python知识点,该记录会不定时持续更新。
1. 解释型语言和编译型语言区别
解释型语言(开发环境中编写代码——解释器(读取一行,翻译一行,执行一行)【编译型语言运行速度比解释型语言快,但跨平台性较差】
2. 特殊符号的含义
\n 换行符
\t 制表符
3. 百分号 % 的含义:用于格式化字符串操作,控制字符串的呈现格式。
%s 字符串 (采用str()的显示)
%r 字符串 (采用repr()的显示)
%c 单个字符
%b 二进制整数
%d 十进制整数
%i 十进制整数
%o 八进制整数
%x 十六进制整数
%e 指数 (基底写为e)
%E 指数 (基底写为E)
%f 浮点数
%F 浮点数,与上相同
%g 指数(e)或浮点数 (根据显示长度)
%G 指数(E)或浮点数 (根据显示长度)
参考https://www.cnblogs.com/cy13blogs/p/12726124.html
4. 句柄 (handle)
以Biopython中fasta文件的读取为例说明句柄:
from Bio import SeqIO
handle = open("ls_orchid.fasta","fasta")
seq_record = SeqIO.parse(handle,"r")
for my_seq in seq_record:
print(my_seq.id, len(my_seq))
handle.close()
同样读取ls_orchid.fasta文件,当不使用句柄时:
from Bio import SeqIO
seq_record = SeqIO.parse("ls_orchid","fasta")
for my_seq in seq_record:
print(my_seq.seq, len(my_seq)
使用句柄 (handle)的好处是:
1.对于以不同方式存储的信息,句柄提供了一个标准的处理办法,可以利用一种通用的方式处理这些不同格式和来源的文本信息。
2.句柄可以依次读取文本信息,而不是一次读取所有信息,这在处理大文件时很有用。
5. 类(class)
“类”这部分可以参考我自己之前学习廖雪峰python时记录的笔记文档,可以更好地理解。
URL = ” https://blog.csdn.net/weixin_44065416/article/details/119734862?spm=1001.2014.3001.5501 “
类:由ID和多个方面的属性构成的集合,用来描述该类。
class Protein:
def __init__(self, gene_id):
self.gene_id = gene_id
self.sequence = ""
self.species = ""
例如上述Protein类:该类中gene_id为索引值,gene_id、sequence和species这些属性用于描述该Protein。
将Protein实例化如:
Protein.gene_id = '123'
Protein.sequence = 'ASDDCV'
Protein.species = 'monkey'
6. 字典 (dictionary)
dict_species = {} #定义一个“物种”的字典,由Key和Value组成
with open(infile) as inF: #打开输入文件
for line in inF:
line = line.split(" | ") #将inF中每一行的内容以“|”分隔开
gene_id = line[0].strip() #gene_id对应于第一部分 (line[0]),作为字典中的gene_id
species_id = line[1].strip() #species_id对应于第二部分 (line[1]),作为字典中的species_id
dict_species[gene_id] = species_id #字典中的gene_id (Key) 对应于相应的species_id (Value)
6.1 defaultdict()
作用:可以将多个相同的key合并为一个,同时将对应的value存储在一个list中。
用法:
假设 old_dict中的key是唯一的,但是value有重复项,现在想要构建一个由旧的value为新的key,由旧的key为新的value构成的 new_dict,实现方法如下
from collections import defaultdict
new_dict = defaultdict(list)
for k,v in old_dict.items():
new_dict[v].append(k)
7. 自定义函数 (def)
自定义一个取绝对值的函数,如下所示:
def Jueduizhi (x):
if x >=0:
return x
else:
return -x
当该自定义函数(jueduizhi())命名为SelfMath.py后,可以通过 from SelfMath import jueduizhi 来调用该函数。注意:需要切换到该SelfMath.py文件所在目录下或将该文件放在python模块目录下才可以。
from SelfMath import jueduizhi
print(jueduizhi(-5)
8. startswith(), endswith()
1. startswith(string[start, end])
判断字符串是否以指定string开始,如果是返回 True,否则返回 False。start, end 分别为字符串起始和结束位置。
2. endswith(string[start,end])
判断字符串是否以指定string结束,如果是返回 True,否则返回 False。start, end 分别为字符串起始和结束位置。
9. dict() 和 set()
dict:字典,由key和value组成。其中key是唯一的。
set:集合,类似于dict,但是仅仅由key组成,无序、无重复、唯一。
用python去重复时,可以利用dict和set这两个的特性进行处理。创建空的集合用set(),但是set不可以用下标进行访问,需要先转换为list,即list(set())
案例1(未用到set())
infile = 'C:\\Users\\19535\\Desktop\\RCC1\\rcc1.fasta'
outfile = 'C:\\Users\\19535\\Desktop\\RCC1\\rcc1_uniq.fasta'
outF = open(outfile,'w')
with open(infile) as inF:
j = 1
gs_dict = {}
g_list = [] #这里创建了两个空列表,没有用到集合(set())。
s_list = []
for line in inF:
if line.strip()[0] == '>':
line = line.strip().split('_')
line.pop()
gid = '_'.join(line)
g_list.append(gid)
elif j % 3 == 2:
sequ = line.strip()
s_list.append(sequ)
j += 1
for i in range(0,len(g_list)):
gs_dict[g_list[i]] = s_list[i]
for k,v in gs_dict.items():
if k.endswith(';'):
outF.write('%s\n%s\n' % (k[:-1],v))
else:
outF.write('%s\n%s\n' % (k,v))
outF.close()
案例2(用到了集合set())
infile = 'C:\\Users\\19535\\Desktop\\RCC1\\rcc1.fasta'
outfile = 'C:\\Users\\19535\\Desktop\\RCC1\\rcc1_uniq_1.fasta'
outF = open(outfile,'w')
with open(infile) as inF:
j = 1
gs_dict = {}
g_list = list(set()) # set 与 dict类似,无序、无重复、只有 key,没有value
s_list = list(set())
for line in inF:
if line.strip()[0] == '>':
line = line.strip().split('_')
line.pop()
gid = '_'.join(line)
g_list.append(gid)
elif j % 3 == 2:
sequ = line.strip()
s_list.append(sequ)
j += 1
for i in range(0,len(g_list)):
gs_dict[g_list[i]] = s_list[i]
for k,v in gs_dict.items():
if k.endswith(';'):
outF.write('%s\n%s\n' % (k[:-1],v))
else:
outF.write('%s\n%s\n' % (k,v))
outF.close()
10. 异常处理 (try...except...)
try:
command_1 (执行代码)
except:
error_1 (若出现错误,则执行error_1)
首先执行 try 中的 command_1语句,如果正常,则忽略 except 中的语句;否则,则执行 except 中的命令,抛出相应的异常。
excpet 后面经常会接一些错误类型 (如:RuntimeError, TypeError, NameError)。
11. os模块
1. os.listdir()
os.listdir():返回path指定的文件夹包含的文件或文件夹的名字的列表。
import os
# 返回桌面上所有文件的名称
infilepath='/Users/Desktop/'
for filename in os.listdir(infilepath):
print(filename)
2. os.system()
os.system():在python脚本中运行终端命令
os.system('cp ' + targetfile + ' ' + newpath + ' ; ' + 'cd ' + newepath + ' ; ' + 'mv ' + targetfile + ' ' + newfilename + '.txt')
该脚本执行的命令有三个:1. 从当前目录下将目标文件复制到新的路径下;2. 切换到新的路径下;3. 将目标文件的名字改为新名字。
各条命令之间用;隔开,依次运行。
11.00 from subprocess import call
call(cmd, shell=False) 可以在python中运行一些命令行的命令,其中shell默认为False,详情参考:
https://www.cnblogs.com/hixiaowei/p/10801932.html
from subprocess imoport call
call(['ls','-l','*.txt']) ## 将当前目录下所有txt文件列出;
call('ls -l *.txt', shell=True) ## 将当前目录下所有txt文件列出;
11.01 from subprocess import check_output
check_output() 可以在python中运行外部命令行命令,详情参考:
https://python3-cookbook.readthedocs.io/zh_CN/latest/c13/p06_executing_external_command_and_get_its_output.html 和
https://blog.csdn.net/whatday/article/details/107631127
11.02 subprocess.run()
subprocess.run() 类似于subprocess.call(),可以是字符串(shell=True)或者是数组(shell=False),详情参考:
https://www.cnblogs.com/itwhite/p/12329916.html
12. python多进程并行运算
from concurrent.futures import ProcessPoolExecutor
def yourfunction():
xxxx
xxxx
if __name__ == '__main__':
p = ProcessPoolExecutor(10)
filelist = ['file1','file2','file3']
for infile in filelist:
p.submit(yourfunction, infile)
p.shutdown(wait=False)
整体思路就是:将自己的待并行的部分封装到一个函数中,在用ProcessPoolExecutor()去调用自己的自定义函数。注意ProcessPoolExecutor.shutdown(wait=False)
我理解的 if __name__ == "__main__" 的意思是,当前.py文件被当做包import到其他程序中时,不执行if __name__ == "__main__"以下的代码。
12.00 from multiprocessing import Pool和from functools import partial
pool = Pool(processes=10)
result = pool.map(partial(your_func, paramater1), paramater2_list) ## paramater2_list:由第二个参数构成的列表,如果直接是参数2,那么不需要用到partial()。
pool.close()
pool.join()
def func(paramater1, paramater2):
pass
func1 = partial(func, paramater2 = paramater)
partial(func1, paramater1=paramater1_list)
具体参考:
https://blog.csdn.net/weixin_38819889/article/details/107815272
https://blog.csdn.net/qq_33688922/article/details/91890142
import time
from multiprocessing import Pool
def f1(i):
return i * 2
def multi_pro(in_list,cpu):
p = Pool(int(cpu))
result = p.map(f1,in_list)
p.close()
p.join()
return result
if __name__ == '__main__':
time1 = time.time()
nums_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
result = multi_pro(nums_list,3)
print(result)
time2 = time.time()
print("计算用时:", time2-time1)
参考:https://juejin.cn/post/6996935915188781070
13. python输出.log文件
import logging
import time
logging.basicConfig(level=logging.INFO,filename='/Desktop/process.log')
localtime = time.asctime(time.localtime(time.time()))
logging.info('程序运行开始,时间是:%s' % localtime)
此外,用nohup后台运行程序,会自动在当前目录生成nohup.out文件。
14. Python手动生成PSSM矩阵文件
1. 产生PSSM文件并据此计算分值。
1.1 python3代码
def GetPSSM(infile,outfile):
#list_10 = []
list_9 = []
list_8 = []
list_7 = []
list_6 = []
list_5 = []
list_4 = []
list_3 = []
list_2 = []
list_1 = []
count = 0
with open(infile) as inF:
for line in inF:
count += 1
line = line.strip()
#list_10.append(line[0])
list_9.append(line[0])
list_8.append(line[1])
list_7.append(line[2])
list_6.append(line[3])
list_5.append(line[4])
list_4.append(line[5])
list_3.append(line[6])
list_2.append(line[7])
list_1.append(line[8])
from collections import Counter
#result10 = Counter(list_10)
result9 = Counter(list_9)
result8 = Counter(list_8)
result7 = Counter(list_7)
result6 = Counter(list_6)
result5 = Counter(list_5)
result4 = Counter(list_4)
result3 = Counter(list_3)
result2 = Counter(list_2)
result1 = Counter(list_1)
list_all = [result9,result8,result7,result6,result5,result4,result3,result2,result1]
import pandas as pd
dt = pd.DataFrame(columns=[-9,-8,-7,-6,-5,-4,-3,-2,-1],index=["A","C","D","E","F","G","H","I","K","L","M","N","P","Q","R","S","T","V","W","Y"])
j = -10
for i in list_all:
j += 1
for k, v in i.items():
dt.at[k,j] = round(v / count, 3)
dt = dt.fillna(value=0)
dt.to_csv(outfile)
# 得到原始序列文件LRR-III_0.txt对应的原始PSSM文件
GetPSSM('C:\\Users\\19535\\Desktop\\LRR-III_0.txt','C:\\Users\\19535\\Desktop\\LRR-III.csv')
# 得到筛选后(score > 3)的原始序列文件对应的最终的LRR-III.txt
import pandas as pd
infile2_1 = 'C:\\Users\\19535\\Desktop\\LRR-III_0.txt'
infile2_2 = 'C:\\Users\\19535\\Desktop\\LRR-III.csv'
outfile2 = 'C:\\Users\\19535\\Desktop\\LRR-III.txt'
outF2 = open(outfile2,'w')
dt = pd.read_csv(infile2_2,index_col=0)
with open(infile2_1) as inF2:
for line in inF2:
score = 0
line = line.strip()
for i in range(1,len(line)+1):
j = len(line)+1 - i
sumj = dt.loc[line[i-1],str(-j)]
score += sumj
if score > 3: # Select The Score > 3
#outF2.write('%s, %f\n'% (line, score))
outF2.write('%s\n' % line)
outF2.close()
1.2 输入数据
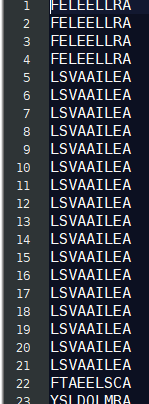
1.3 输出结果:
输出的PSSM矩阵文件(结果1)如下:
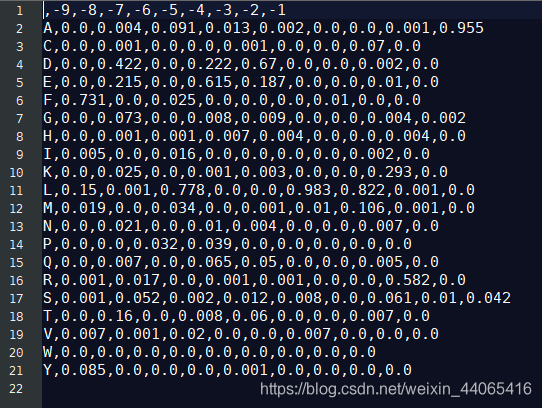
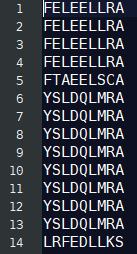
根据该PSSM文件,计算原文件中每一行的得分值,选取score>3的结果,如下(结果2):
15. if...elif...else
if condition1:
commandX
elif condition2:
commandY
else:
commandZ
commandA
形如上述结构,该部分只会执行
commandX + commandA 或者
commandY + commandA 或者
commandZ + commandA
16. if not
如下所示:
fast = False
if fast:
print('0')
if not fast:
print('1')
运行该脚本只会得到 “1”,而如果把fast = False换成fast = True,那么则会得到“0”,原因如下:
首先fast初始是False,而if xxx = xxx is True,if not xxx = xxx is False,因为fast默认是False,所以会执行if not fast。
a = []
not a
True
从上面这一段可以看出,if not a 表示if a is None
实践. 遇到的小问题及解决办法
1.在 for循环中将结果以一个字符串的形式输出
例如:在字符串seq中,以括号中的内容以第一个字符来代替整个括号的内容。如下所示,其最终结果应为ADGJK
seq = '(ABC)(DEF)(GHI)J(KLM)'
a = seq.split('(')
b = len(a)
result = ''
for i in range(0,b):
result += a[i][0] + a[i][4:]