VGG是ILSVRC2014分类任务的亚军,可以看成是加深版的AlexNet,都是由Conv layer + FC layer组成。
一. VGG的特点:
多个小尺寸的卷积核代替大尺寸卷积核
主要表现,使用2个3×3的卷积核替代5×5的卷积核
这样做的好处:
1.1 在保证相同的感受野的情况下,多个小的卷积层堆积可以提高网络 的深度,有利于提高特征提取能力。
1.2 参数量更少,一个5×5的卷积核,其参数量为5 x 5 x Channel_in x Channel_out,两个3×3的卷积核,其参数量为2 x 3 x 3 x Channel,很明显,25Channel_in x Channel_out > 18Channel_in x Channel_out。
1.3 3×3卷积核更有利于保持图像性质
二. VGG的网络结构:
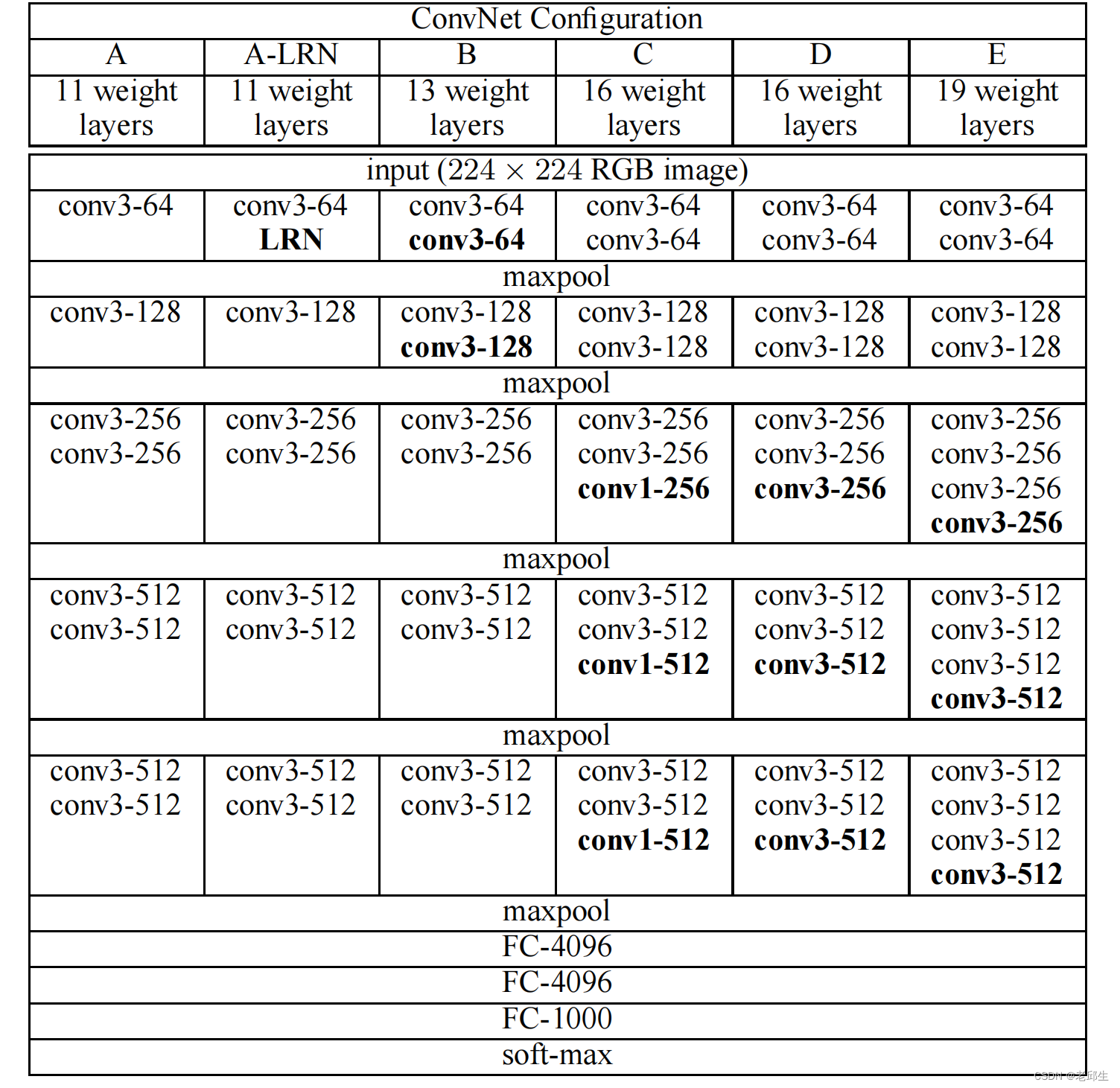
图1:VGG网络结构图
三. 花品种分类代码实现
3.1 vgg模型框架搭建
import torch
import torch.nn as nn
class VGG(nn.Module):
def __init__(self, feature, num_classes=100, init_weights=False):
super(VGG, self).__init__()
self.features = feature
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']}
def make_feature(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
def vgg(model_name, **kwargs):
assert model_name in cfgs, " Warning : model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_feature(cfg), **kwargs)
return model
if __name__ == "__main__":
model = vgg("vgg16", num_classes=5)
data = torch.rand(1, 3, 244, 244)
result = model(data)
print(result.shape)
3.2 训练代码搭建
import torch
import torch.nn as nn
import os
import sys
import json
from torchvision import datasets, transforms
from tqdm import tqdm
from model import vgg
import torch.optim as optim
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
data_root = os.path.abspath(os.path.join(os.getcwd(), "./data_set/flower_data/"))
assert os.path.exists(data_root), "{} path does not exist.".format(data_root)
train_dataset = datasets.ImageFolder(root=os.path.join(data_root, "train"), transform=data_transform["train"])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open("class_indices.json", 'w') as f:
f.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print("Using {} dataloader workers every process".format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(data_root, "val"), transform=data_transform['val'])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=nw)
net = vgg("vgg16", num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 1
best_acc = 0.0
save_path = "Module/vgg16.pth"
train_steps = len(train_loader)
for epoch in range(epochs):
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch+1, epochs, loss)
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_image, val_label = val_data
outputs = net(val_image.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_label.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epochs+1, running_loss/train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net, save_path)
print("finsh training")
if __name__ == "__main__":
main()
3.3 预测代码搭建
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "./xrk.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
model = vgg(model_name="vgg16", num_classes=5).to(device)
# load model weights
weights_path = "Module/vgg16-3-8-1522.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
# model = torch.load("Module/vgg16.pth")
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
完整的代码链接:
版权声明:本文为2301_76382363原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。