本篇内容可以和上一篇结合使用p站爬取数据绕过vip筛选高人气画作
先放码
import requests
import json
import time
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def load_cookies():
cookie_json = {}
try:
with open('cookies.json','r',encoding = 'utf-8') as cookies_file:
cookie = json.load(cookies_file)
except:
print('cookies读取失败')
else:
for i in range(len(cookie)):
if cookie[i]['domain'] == '.pixiv.net':
cookie_json[cookie[i]['name']] = cookie[i]['value']
return cookie_json
def get_session(item_id):
head = {
'accept': 'application/json',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '60',
'content-type': 'application/json; charset=utf-8',
'Host': 'www.pixiv.net',
'Origin': 'https://www.pixiv.net',
'Referer': 'https://www.pixiv.net/users/'+item_id+'/bookmarks/artworks',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
'x-csrf-token': '584507416fc0fc3c61bdb59f7b7a0792',
}
cookie_json = load_cookies()
session = requests.session()
session.headers = head
requests.utils.add_dict_to_cookiejar(session.cookies,cookie_json)
return session
def Collection(item_id):
session = get_session(item_id)
request_payload = {"illust_id":item_id,"restrict":0,"comment":"","tags":[]}
url = 'https://www.pixiv.net/ajax/illusts/bookmarks/add'
try:
Collection = session.post(url,data=json.dumps(request_payload),verify=False).json()
except:
print('错误:'+str(item_id))
else:
if Collection['error'] == False:
print('保存成功:'+str(item_id))
else:
print(Collection)
def data_load(folder):
try:
Collection_id = json.load(open('Collection.json','r',encoding = 'utf-8'))
except:
Collection_id = []
data = json.load(open('./item_data/'+folder+'.json','r',encoding = 'utf-8'))
for item_id in data:
if int(data[item_id]['book_mark_count']) >= 40000 or int(data[item_id]['book_like_count']) >= 20000:
if item_id in Collection_id:
pass
else:
Collection(item_id)
Collection_id.append(item_id)
json.dump(Collection_id,open('Collection.json','w',encoding = 'utf-8'))
time.sleep(2)
if __name__ == '__main__':
data_load('2020-03-28-22')
load_cookies()
由于是关于收藏夹的改动,肯定需要验证登入啊
这就不加以赘述了,详情请看p站收藏夹爬虫
get_session(item_id)
def get_session(item_id):
head = {
'accept': 'application/json',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '60',
'content-type': 'application/json; charset=utf-8',
'Host': 'www.pixiv.net',
'Origin': 'https://www.pixiv.net',
'Referer': 'https://www.pixiv.net/users/'+item_id+'/bookmarks/artworks',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
'x-csrf-token': '', #该参数在请求中找
}
cookie_json = load_cookies()
session = requests.session()
session.headers = head
requests.utils.add_dict_to_cookiejar(session.cookies,cookie_json)
return session
大家注意到请求头中存在x-csrf-token,这个每个人的值都不同。需要到网页中查看
先点开任意一个图片项目,如何在打开F12的情况下


这些参数必不可少,还有referer的配置,需要根据套图id的变化而变化。
Collection(item_id)
def Collection(item_id):
session = get_session(item_id)
request_payload = {"illust_id":item_id,"restrict":0,"comment":"","tags":[]}
url = 'https://www.pixiv.net/ajax/illusts/bookmarks/add'
try:
Collection = session.post(url,data=json.dumps(request_payload),verify=False).json()
except:
print('错误:'+str(item_id))
else:
if Collection['error'] == False:
print('保存成功:'+str(item_id))
else:
print(Collection)
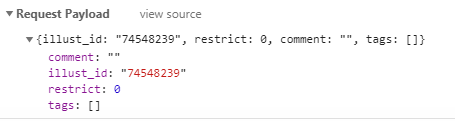
唯一需要变动的是illust_id的值。这里要使用post方法传入数据。
data_load(folder)
def data_load(folder):
try:
Collection_id = json.load(open('Collection.json','r',encoding = 'utf-8'))
except:
Collection_id = []
data = json.load(open('./item_data/'+folder+'.json','r',encoding = 'utf-8'))
for item_id in data:
if int(data[item_id]['book_mark_count']) >= 40000 or int(data[item_id]['book_like_count']) >= 20000:
#print('一档 '+'https://www.pixiv.net/artworks/'+item_id+' '+data[item_id]['book_title'])
if item_id in Collection_id:
pass
else:
Collection(item_id)
Collection_id.append(item_id)
json.dump(Collection_id,open('Collection.json','w',encoding = 'utf-8'))
time.sleep(2)
elif 40000 > int(data[item_id]['book_mark_count']) >= 30000 or 20000 > int(data[item_id]['book_like_count']) >= 17500:
#print('二档 '+'https://www.pixiv.net/artworks/'+item_id+' '+data[item_id]['book_title'])
if item_id in Collection_id:
pass
else:
Collection(item_id)
Collection_id.append(item_id)
json.dump(Collection_id,open('Collection.json','w',encoding = 'utf-8'))
time.sleep(2)
首先获取在上篇文章中讲述的方法保存的数据,再通过筛选,获取到高人气的画作。
在通过Collection()方法进行收藏。为了减少重复工作,我加入了一条关于验证的代码
def data_load(folder):
try:
Collection_id = json.load(open('Collection.json','r',encoding = 'utf-8'))
except:
Collection_id = []
...snip...
if item_id in Collection_id:
pass
else:
Collection(item_id)
Collection_id.append(item_id)
json.dump(Collection_id,open('Collection.json','w',encoding = 'utf-8'))
time.sleep(2)
每次收藏时记录已保存的套图id,如果已经收藏过就跳过
时间:2020/3/29
版权声明:本文为DHS2219576309原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。