一、ElasticSearch简介
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据,底层基于Lucene实现。
-
数据总体分为两类:结构化数据和非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据。非结构化数据又一种叫法叫全文数据。 -
对比传统数据库
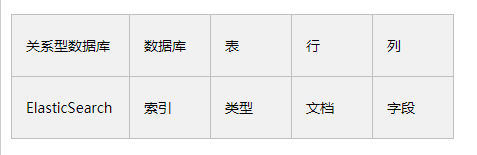
es没有事务的概念,不支持回滚,误删不能恢复。使用es在大量数据搜索和分析,或数据修改很少的场景。

es采用倒排索引,传统数据库采用B+树索引
常规索引:
文档——>关键词 但是这样检索关键词的时候很费力,要一个文档一个文档的遍历一遍。
倒排索引:
关键词——>文档 只要有关键词,立马就能找到她在那个文档里出现过,然后就可以查出整个文档。
二、ElasticSearch原理
Elasticsearch 的数据采集是指:在进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
三、ElasticSearch简单使用
1. elasticsearch安装(Windows版)
官网下载地址

jdk与ElasticSearch版本兼容对照

将下载得到的zip文件解压,并打开bin目录下的elasticsearch.bat文件,等待启动完成

访问 http://localhost:9200,返回数据如下则启动成功

解决jdk版本支持问题
es提示更高版本的jdk支持,但自己的jdk环境是1.8。这里可以使用es自带的jdk,在系统环境变量中添加如下变量。


修改后即可正常启动es,警告消失

2. 安装es可视化工具ElasticHD
ElasticHD 是 github 上的一个开源的项目,没有官方网站。ElasticHD 支持 ES监控、实时搜索,Index template快捷替换修改,索引列表信息查看, SQL converts to DSL(T-SQL语法和DSL语法相互转换)工具等 。
es 6.3版本以后已经支持sql查询了。Elasticsearch SQL是一个X-Pack组件,它允许针对Elasticsearch实时执行类似SQL的查询。无论使用REST接口,命令行还是JDBC,任何客户端都可以使用SQL对Elasticsearch中的数据进行原生搜索和聚合数据。可以将Elasticsearch SQL看作是一种翻译器,它可以将SQL翻译成Query DSL。


ElasticHD下载地址


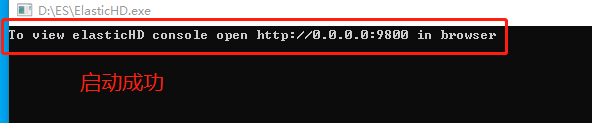
将下载的压缩包解压后得到一个exe文件,双击启动后,通过浏览器连接ElasticHD。连接地址为:http://localhost:9800


3. 安装kibana
Kibana版本必须与ElasticSearch版本保持一致。由于 Kibana 基于 Node.js 运行,我们在这些平台上包含了一些必要的 Node.js 二进制文件。Kibana 不支持在独立维护的 Node.js 版本上运行。
node下载地址
kibana下载地址
- 下载得到的kibana文件解压后,设置连接elasticsearch实例,默认连接本地es服务
kibana-7.13.4-windows-x86_64 -> config -> kibana.yml

- 启动kibana
kibana-7.13.4-windows-x86_64 -> bin-> kibana.bat

- 访问kibana服务:http://localhost:5601/

启动Kibana后,Kibana会自动在配置的es中创建如下索引,用来存储数据,注意不要删除了。

如果把ElasticSearch理解成DB的话,这个仪表盘(Kibana)就是你使用的Navicat。
4. elasticsearch的简单使用
在kibana开发工具控制台管理elasticsearch的数据

- 创建索引
## 创建索引school
## 名字不能包含特殊字符,只能小写,不能以-, _, +开头,不能超过255字节。
## PUT school本质是PUT http://ip:9200/school,也可以通过curl操作es
PUT school

- 向指定索引添加文档
## 添加文档0
## type不需要创建,现在已经移除了type,因为在es的同一个index下不同type是存储在同一个索引中,即只能有一个type。如下_doc为type,0为文档id。
POST school/_doc/0
{
"name":"zhangsan",
"age":18
}
- 查看索引信息
## 查看索引信息
GET school
或通过elasticHD查看

将以上对应的DSL语句复制,在Query中粘贴执行查询操作

查询结果如下

- 删除索引
## 删除索引
DELETE hotel
- 查看所有索引信息
GET _cat/indices
- 向索引添加多条数据:_bulk
## 添加数据PUT和POST都可以
## 注意插入数据时如果指定的_id已经存在,那么新插入的数据会直接替换原ID的数据。
## 一行是要执行的动作(在本例中是“index”),另一行是实际文档。想重复多少次就重复多少次,不要忘记每行最后的换行符。
POST home/book/_bulk
{"index":{"_id":1}}
{"name":"《围城》","price":101}
{"index":{"_id":2}}
{"name":"《格林童话》","price":108}
## 如下格式是错误的
POST home/book/_bulk
{"index":{"_id":1}}
{
"name":"《围城》",
"price":101
}
{"index":{"_id":2}}
{
"name":"《格林童话》",
"price":108
}
- 查看文档信息:_search
GET home/book/_search
{"query":{"match_all":{}}}
- 修改文档信息:_update
## 修改文档信息:_update
#_update API,表示将id为0的document的price改为100
POST home/book/0/_update
{"script":
{"source":"ctx._source.name=params.name",
"lang":"painless",
"params":{"name":"丞相"}
}
}
5. Springboot整合es
es分词器:
