定义
是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域
简单入门kafka
来源于B站:https://www.bilibili.com/video/BV1vx411f7hA
首先了解发布与订阅系统,想象一个公众号
运营公众号的人把文章发布到平台上,阅读者只要订阅相应的公众号,当有新的文章发布的时候阅读者就可以阅读到新的文章了。
这种发布者和阅读者没有直接沟通,而是通过中间站来传递消息的模式就是发布和订阅模式
当多个应用程序向多个程序发送消息

可以看到有很多程序和很多的通讯链路
这样会造成三个问题
- 团队之间可能进行着重复的工作,会造成资源的浪费
- 信息过多无法同步时,会造成信息的丢失
- 程序之间相互依赖耦合度太高,可能会牵一发动全身
这样时候基于发布/和订阅的消息系统就很重要了:Kafka

简单的说kafka就是可以接受不同的生产者的消息,然后被不同的消费者来订阅这些消息供自己使用
生产者、消息、订阅者
消息:可以想象成是数据库里面的一行数据
生产者:发布消息的程序
消费者:订阅消息的程序
这样看起来Kafka就像一个管道
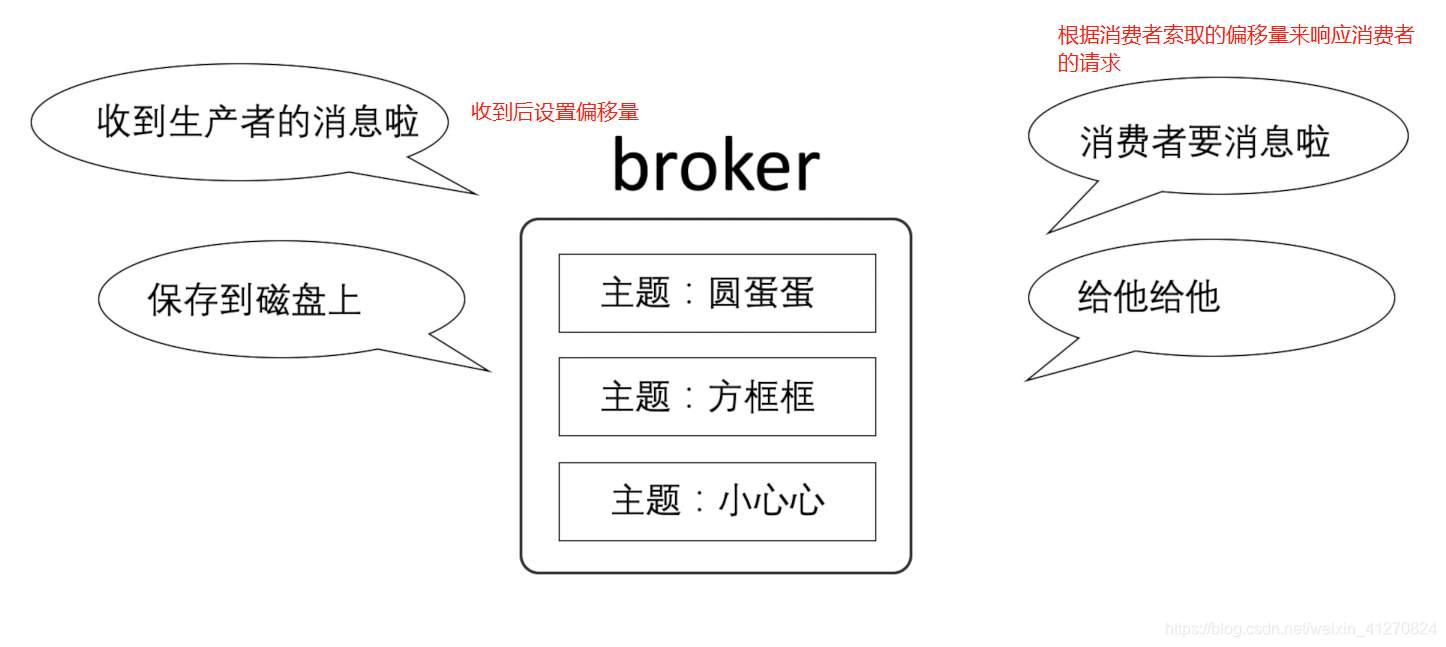
但是既然所以生产者都把消息发到这里,生产者该怎么拿到自己想要的消息呢?
主题(Topic):生产者把消息放进kafka的时候需要给消息分好主题,而消费者会订阅不同的主题

还有一个很重要的概念
分区(partition):分区可以分布在不同的服务器上,这样一个主题就可以分布在多个服务器上了
生产者会把消息放入到相应的主题相应的分区上面
生产者怎么知道该放入哪个分区里面呢?
1、跟之前指定主题一样,生产者指定去哪个分区
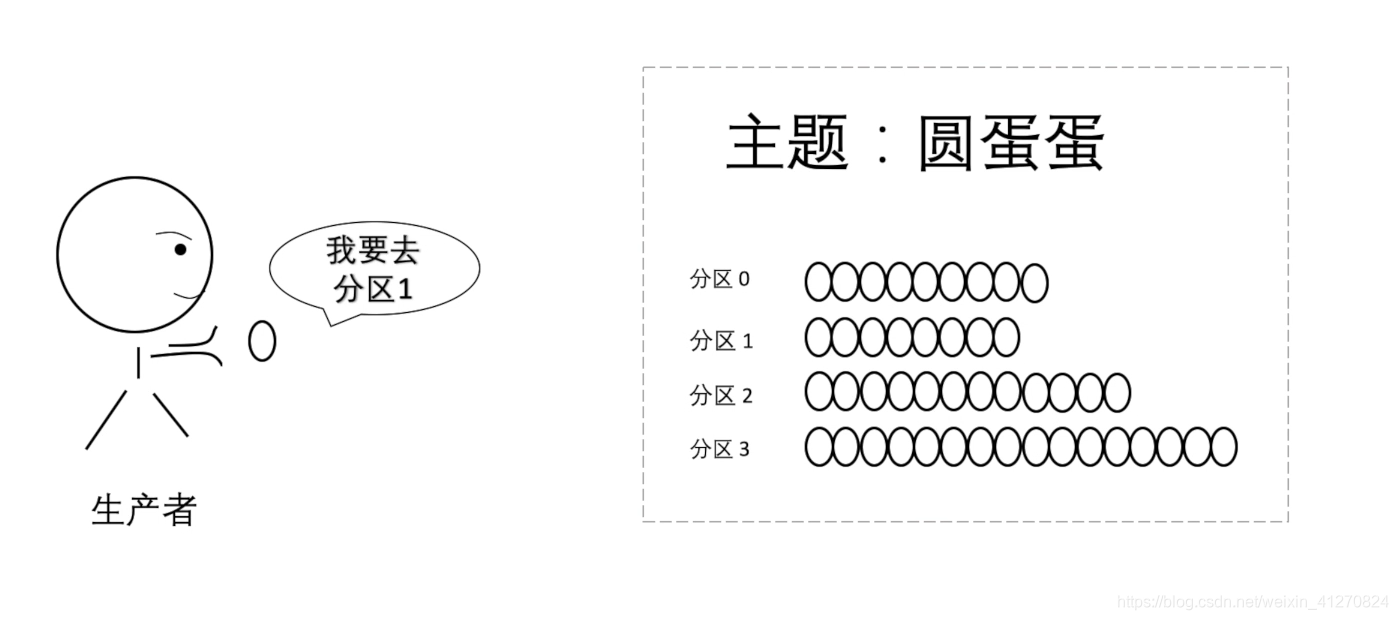
2、如果没 指定的话,消息里面的键就起作用了,分区器会根据键来决定消息的去处

突然我们又引入了两个概念
键:一个标记,每一个值都会对应一个标记,每一条消息都会对应一个标记
分区器:一个算法,输入值是键,输出值是该去哪个分区
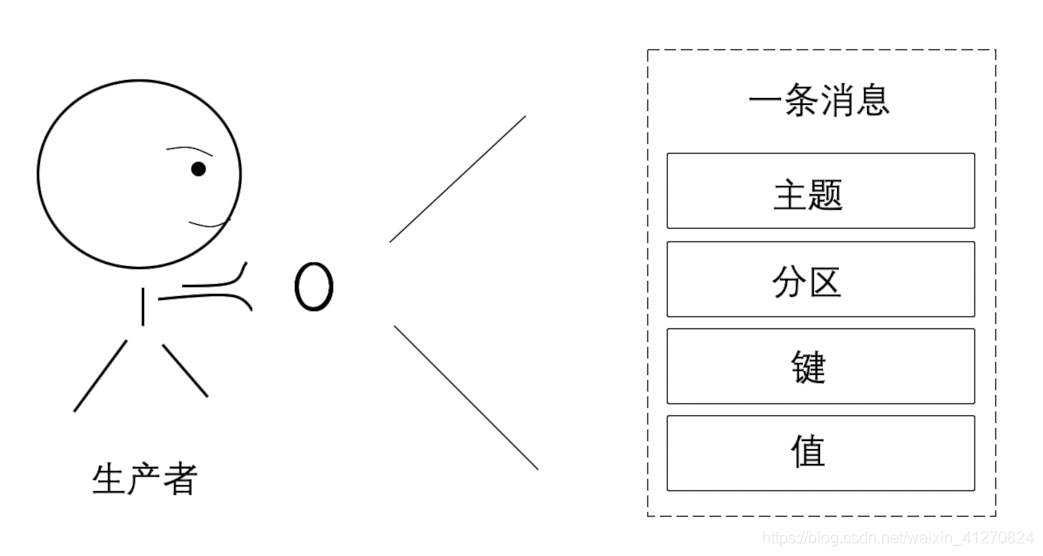
一条消息可能会包含这些内容:
那接下来我们消费者要怎么读取数据呢?
这又要引入一个很重要的概念了:偏移量
- 偏移量:也就是第几个
- 一个分区里,每个消息的偏移量都是唯一的
- 消费者只能顺序读取

到现在我们已经看到了一个独立的kafka服务器了,这就是broker
多个broker就组成了kafka集群
我们可以看到两个broker里面的消息是一样的,当broker1宕掉的时候broker2还是好的,我们可以继续从broker2里面来读取数据。
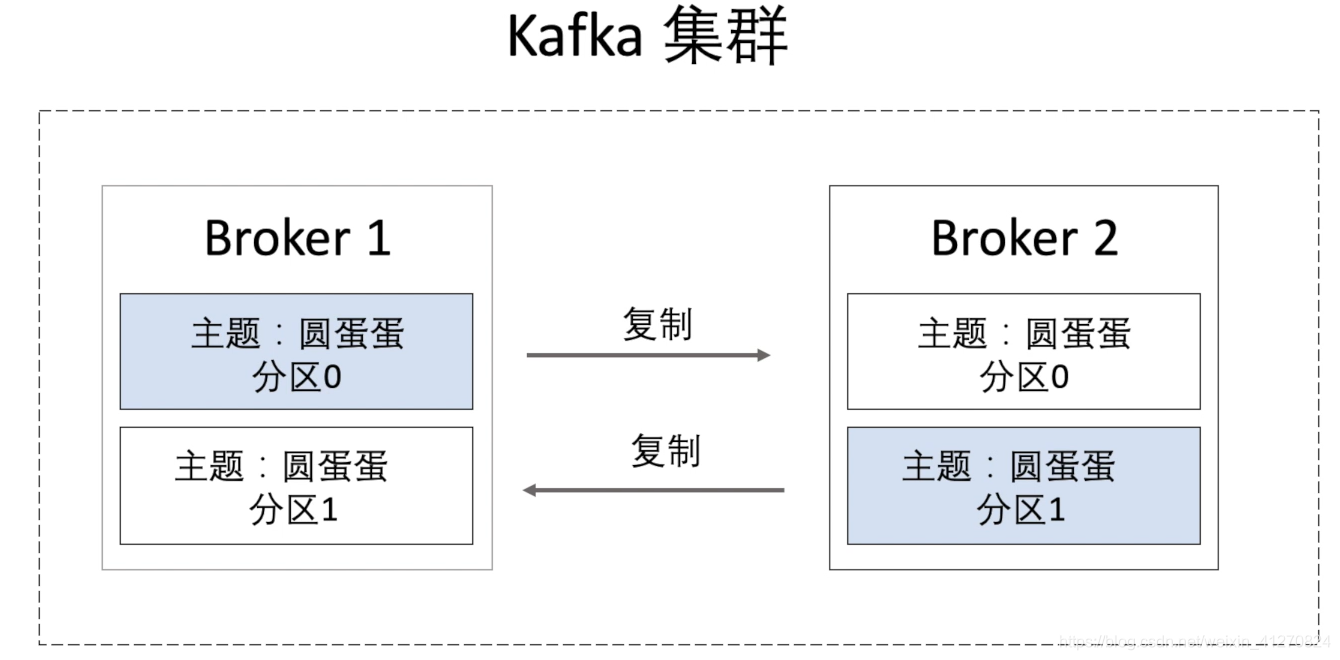
kafka集群里面还有一个Broker来当作充当控制器的角色,可能会负责一些分区该分配给哪些Broker死掉这些
总结:
我们主要介绍了:
1、消息、生产者(发布)、消费者(订阅)
2、主题(指定)、分区(指定、[分区器、键])
3、broker、集群