PART Ⅰ:一些常用的英文术语:
procedural:程序;procedural language:程序设计语言,如C++;
variables/types/scope:变量/类型/作用域 instance:例子,实例
PART Ⅱ:一些应有的认知:
①C++ == C++语言本身+标准库
②object based(基于对象)–仅仅只是作了数据成员&方法的封装,也就是只是封装成了对象 object oriented(面向对象)–在对象之间还使用了继承、复合、委托等进行类与类之间的复合
③C与C++在业务实现上的一些区别:
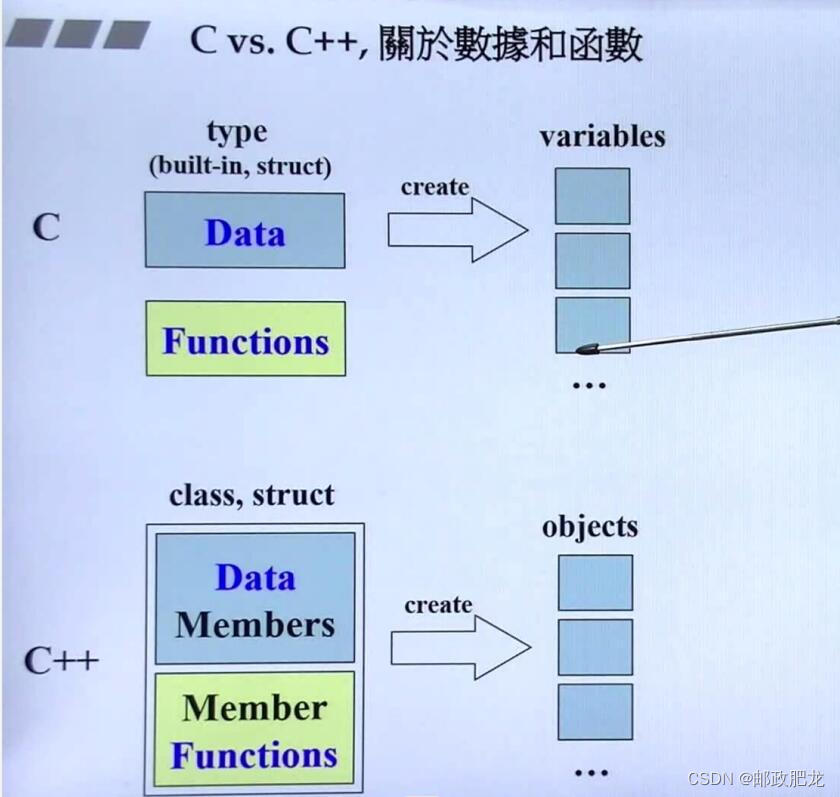
C–面向过程,通过变量、函数来组合并操控数据
C++–面向对象,通过类(结构体也可以看作是类)来复合数据成员&成员方法,封装为对象
※一种很自然的思考:把数据以及处理这些数据的函数放在一起,并且这些数据只有处理它们的方法能看得到,C++的类便提供了实现这种思想的渠道,为程序的编写带来了极大的便捷。也就是,函数的access level往往是public,而内部的数据成员往往是封装而不被外界所可见的。
④永远不要忽视C++标准库在C++程序中的重要地位!一个C++程序可以看作是自编写的头文件(包含了类&各类函数的declaration)+对应的.cpp文件(存储类内方法&其他函数的定义)+程序入口(main函数)+标准库头文件
⑤cout<<“1″;这个语句,与其看作是认为cout作为一个推手,把”1″推到屏幕上,不如看作是把”1″丢到cout里面,然后再对cout进行输出操作。
⑥留一个尾巴:这种现象出现的原因?
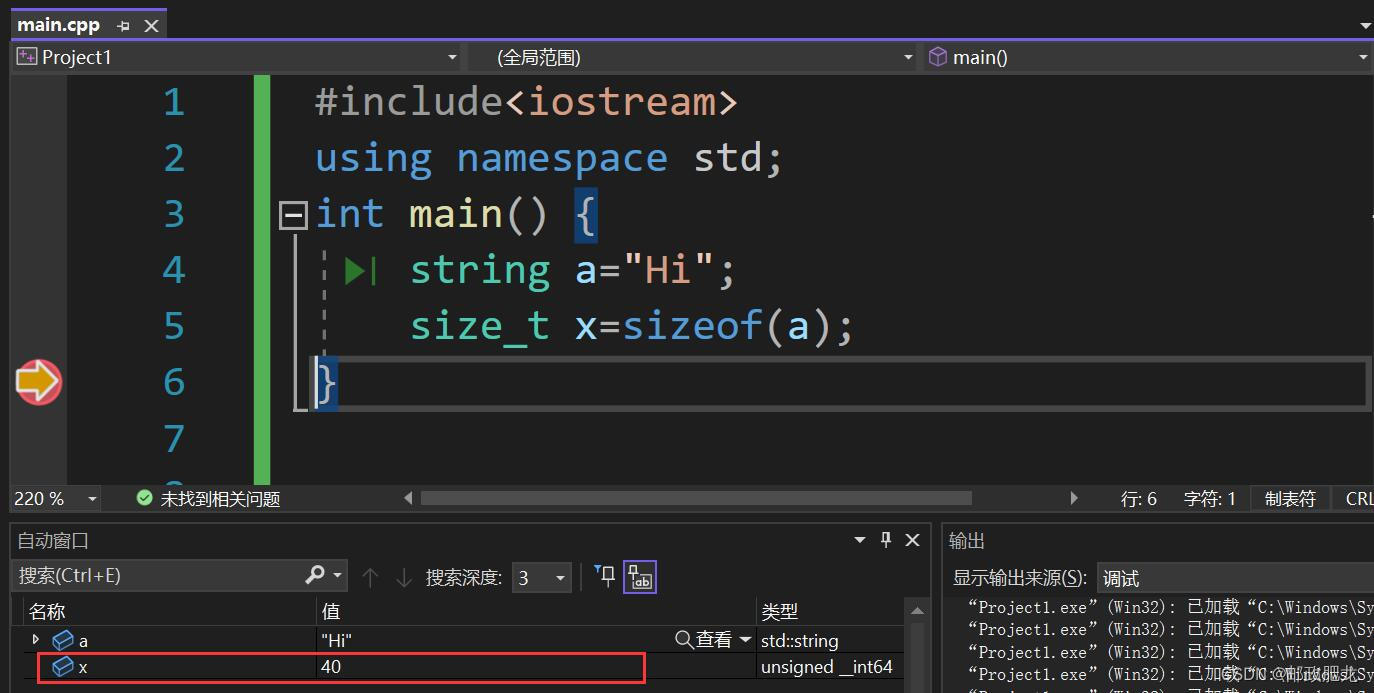
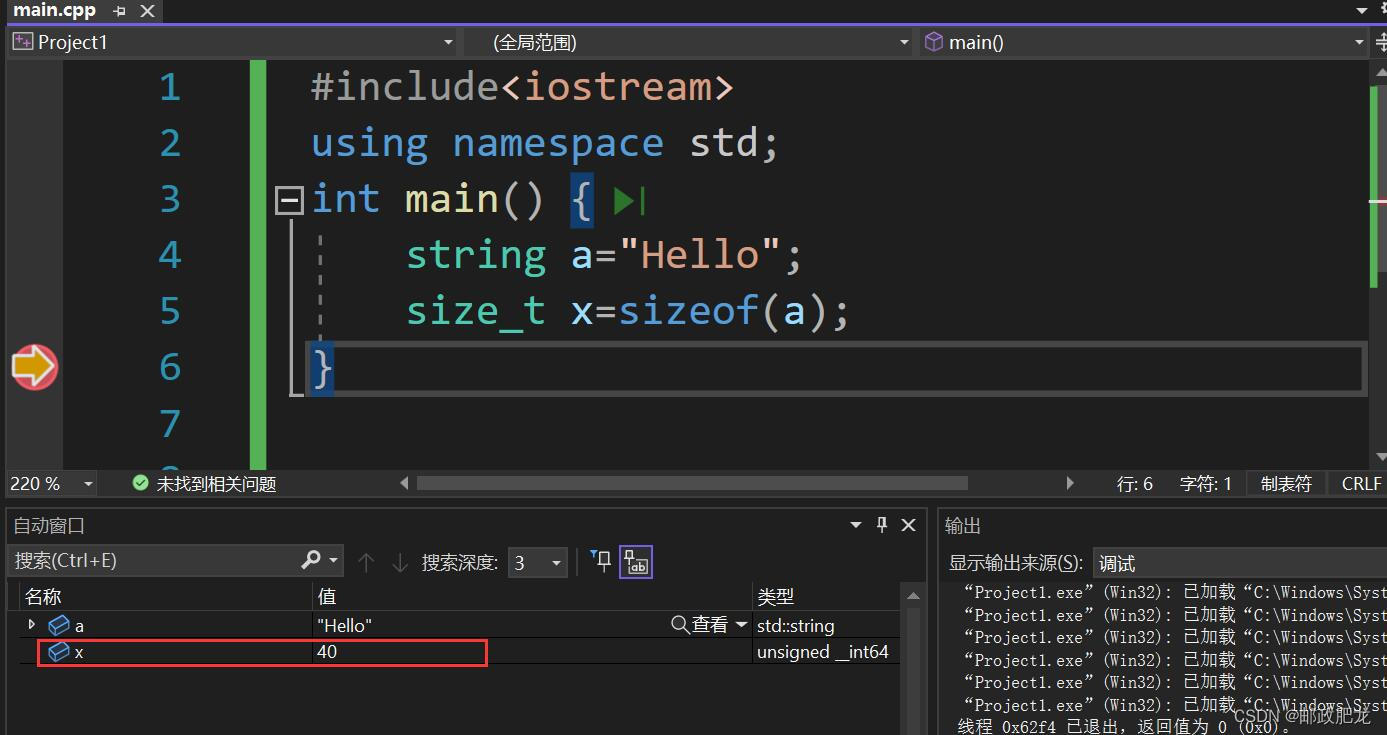
⑦inline函数--(更详细的叙述见Cherno笔记整理(一))其实是可以大胆去指明inline关键字的,即使好几行的函数都可以写,只是编译器会不听你的。但是编译器判断这个函数可否内联也是编译器的工作,所以随意的设置内联只是降低可读性,并不至于消耗性能.
※:函數若在 class body 內定義完成,便自動成為 inline 候選人!!!
留个问题:

PART Ⅲ:从complex类的书写谈起面向对象设计:
①re:real quantity,实部;imag:imaginary quantity,虚部
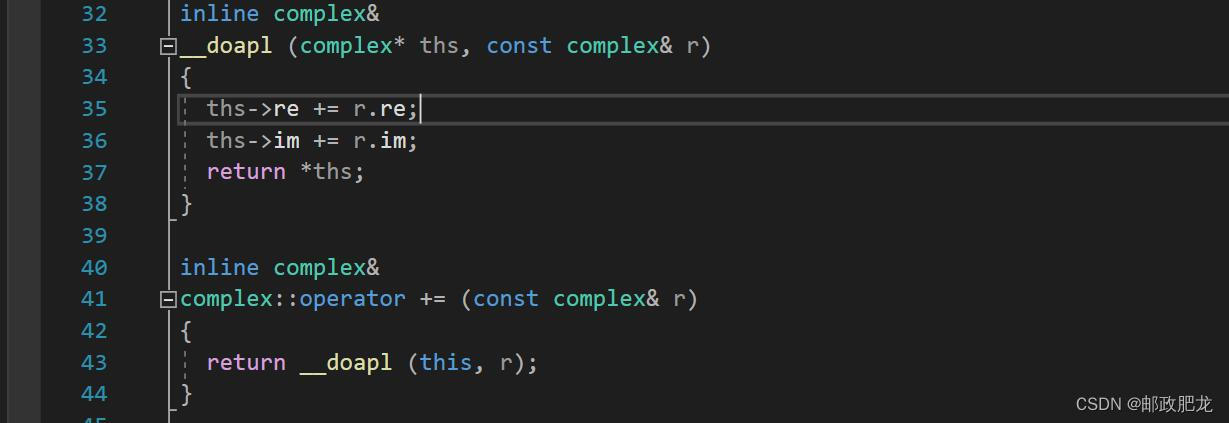
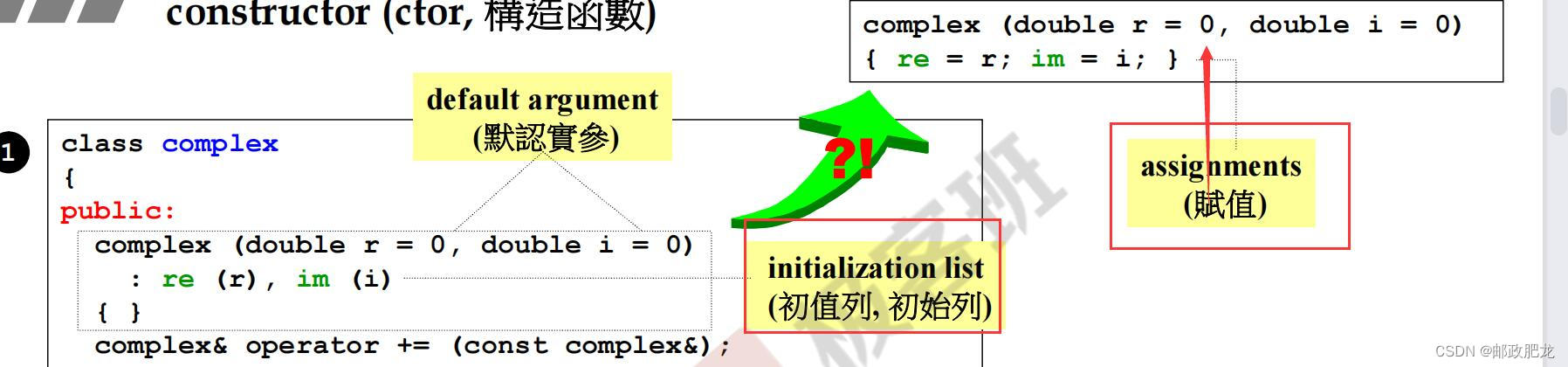
例:对于”+=”运算符的重载:
②非常关键的一点:构造函数中,只有初始化列表处给成员变量做的是初始化工作,而函数体内部做的实际上是“已经初始化之后的赋值工作”!!!!
③从目前阶段来看,对于析构函数而言,如果类内没有指针成员(ptr member)的话,一般是不需要我们自己特地去书写析构函数的。因为带着指针成员了即需要去考虑深拷贝的问题!!
④几点补充:
(1)确实不会有两个同名的函数,所谓的函数重载,只是人看起来同名,编译器在进行处理的时候也会给它们额外添加许多符号来进行标识
(2)相同类的各个成员互为友元,因此它们是可以互相访问对方的private区的成员的!
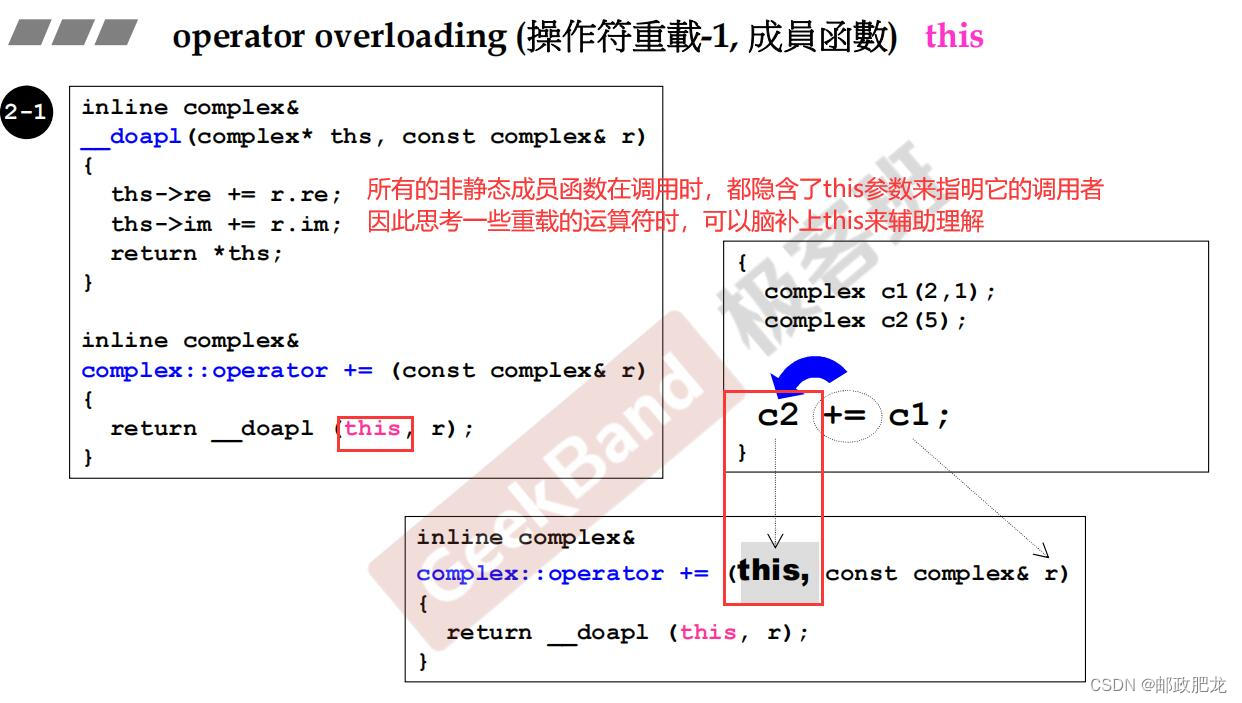
⑤进行__doapl函数(do assignment plus,也就是进行加法赋值操作)的时候,返回的是对应类类型的引用,主要的目的还是为了链式计算。而且,“右边的加到左边的这个东西上”,得到的必然还是左边这种东西。

⑥一个思想:对于类类型&数组类型等的类型的参数,在传参和返回时能用引用就用引用,可以大大提高程序运行的速度!普通的double之类的不传也就不传了,对于性能的影响并不大。
※极其典型的一种不可以返回引用的情况:局部变量的引用,也就是函数体内创建的对象的引用
譬如对于addition operator的重载的书写:

相当于内部通过构造函数创建了一个临时对象,如果这时候返回这个临时对象的引用,在函数体外操作它的时候,它已经离开作用域了,因此是需要返回时进行“朴实的返回”,也就是复制一份再return回去。
※再如:

同样地,传入局部对象的引用时也要仔细考虑,可能会引发一些目前不好预测的问题
⑦成员函数不加上const的话是无法匹配const对象的——
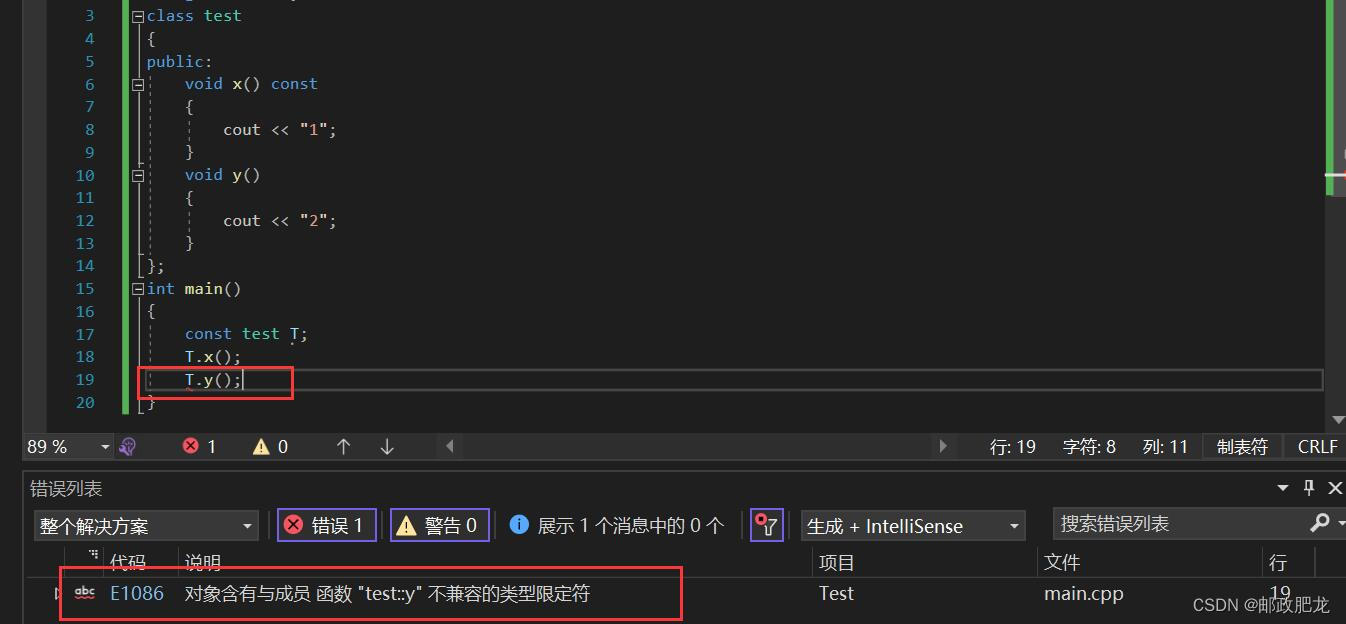
因为成员函数的后缀const(区别于返回值处的const!返回值处的const只是保证返回值是常量),保证了这个成员函数不会更改类内的数据成员,而这也是const对象所保证的,因此它们才可以匹配
※从代码风格上来讲,其实不写const,实际上就说明了传进来的这个参数是需要被修改的

⑧运算符重载的一些值得注意的地方:

不用cout之类的——<<运算符重载本身就必须传入两个参数
※addition operator的一个比较标准的写法:

※尽量少的使用友元函数,因为它的存在是对于类的封装性的一种极大的破坏,很多时候通过getter来拿成员即可,没必要写成友元(不过这种直接修改成员的,声明为友元是比较有必要的)
※友元函数声明放在public或protected等都可:(下面这篇文章的核心在于,友元函数不属于类的成员,而public等声明访问权限的标识符只会限制类的成员的访问权限,因此友元函数置于private或是什么区域都无所谓)

※在运算符重载中频繁出现的this参数:
※书写运算符重载时的其他考虑:因为会有多种的加法,不光是complex之间相加,还可能是各种形式的数字的相加,因此写成全局形式更加适合。

※全局形式的两种写法——不要认为全局形式只能是void型且摒弃链式运算:

※亦可: (更高级的写法–)

⑨其他的一些注意的点:
(1)注意区分开对象创建的不同写法——

下面这两个创建出的其实是右值形式的临时对象!也就是说它们的生命周期只有所在的代码行,走完那一行就死了
(2)getters不要忘记写成const形式!

PART Ⅳ:Singleton–单例模式初谈

几个比较核心的点:
① 单例模式适用于需要一个应用于全局的某种数据集的情况(其实这种需求有时也可以通过namespace来实现),比如我们有一个渲染器的实例,我们一直向这一个渲染器的实例去提交一些信息并使它完成一些工作
② 基于①,实际上书写单例模式的类的行为与工作方式很像是一个命名空间,(因为命名空间也是无法去做所谓的实例化的)用以提供给外界一些统一的调用函数的方式。因此可以认为单例模式只是一种组织一堆全局变量和静态函数的方式
③ctors(constructors,构造函数)必须是私有的,因为如果构造函数公有,它就允许被实例化;同时,拷贝构造应当被删除或者也置于private区,以免外界通过拷贝的方式来创建对象–A(const A&)=delete;
④GetInstance函数显然应当是静态的,因为如果它是非静态的,我们就会需要通过实例化后的对象来调用GetInstance函数,这显然不现实。
⑤题外话:当通过GetInstance获取实例的时候,如果嫌麻烦,可以使用auto,但是如果想要获取引用的话,还应当书写成auto&来获取:auto & MyA=A::GetInstance();
⑥GetInstance之类的这种一共都不超过两三行函数,应当写成内联函数来保证性能不受损失
⑦更加好的一种书写方式是将静态对象的创建置于静态函数内部,而不是类的保护/私有区,可以防止不用到这个单例时去做无谓的创建:
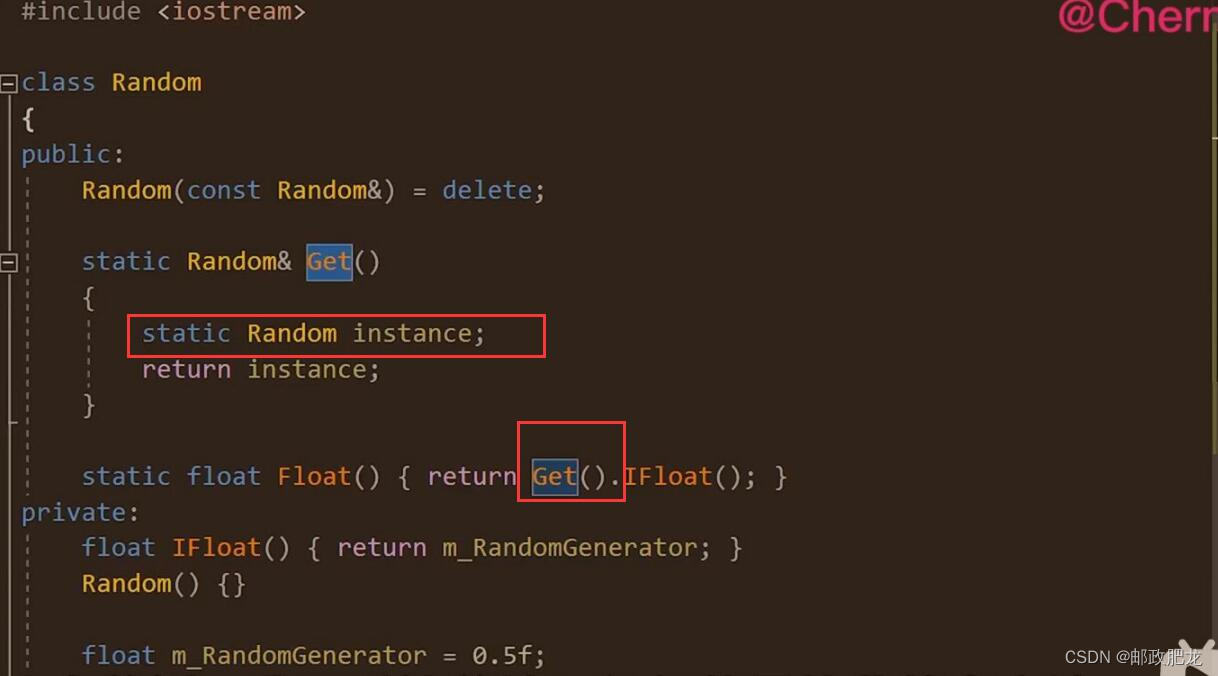
包括类内的各种函数,如果想要用到这个单例对象的话,也是通过Get函数来获取
※补充:Cherno对于单例模式的叙述:
单例就是一个类的单一实例,也就是你在使用的时候只想要拥有那个类/结构体的一个实例。你想要使用静态方法的话,不需要额外的实例化,但是类内必须要有对应的静态的成员。
单例,对应的往往是“仅需一直查询一个东西或者一直向一个东西发出请求并得到对应结果”的需求,而不需要实例化或遍历这所有的东西。这种需求通过namespace其实可以满足,也就是我们提供一个空间,使得易于查询属于它的函数——单例的工作模式和它命名空间本来就很相像,只是多了private和public的功能,使得接口等的书写更加便捷——————————
※这里我们又引出了命名空间,简要叙述一下它的作用的话,它存在的主要目的相当于是避免命名的冲突,不同的块(通过namespace来代表)下的同名函数可能代表的是不同的功能。C中这种情况必定是有重名错误的,而C++的namespace使得这些可行。
一定要注意类内声明的静态成员一定要在类外有定义!
一个很容易犯的致命错误——不处理拷贝构造函数,这样会导致以下这种行为被允许:
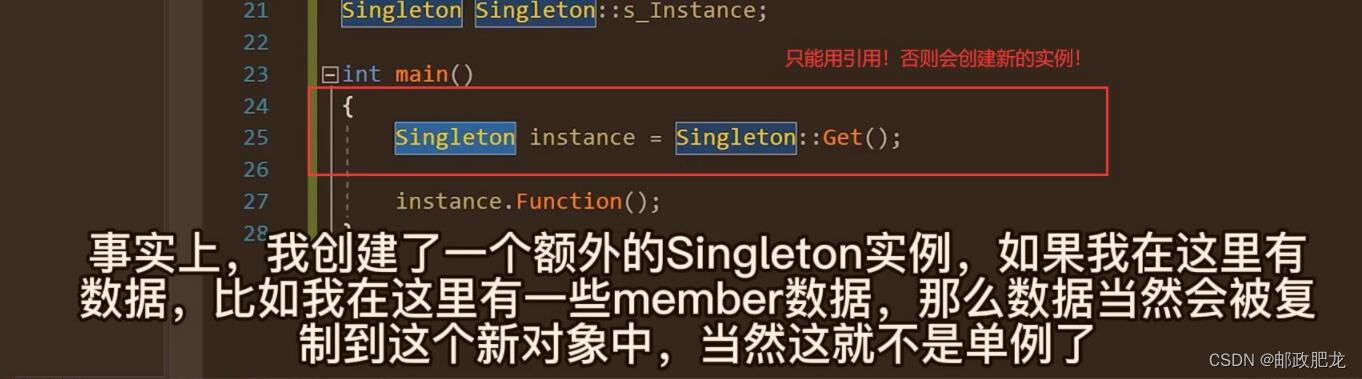
而如果我们delete掉了拷贝构造函数,此时这样通过拷贝构造函数来实例化新对象的时候就会得到编译器的报错,因为我们只可以用引用的方式来只获得那个实例并对它进行操作。