ANTLR4 VsCode Win10 Java
安装及环境配置
jdk11 win10安装及环境配置
ANTLR4 win10安装及环境配置
vscode上实现官方示例
接下来我们会演示如何实现一个官方示例。
预期效果
将
static short[] data={1,2,3}
翻译成
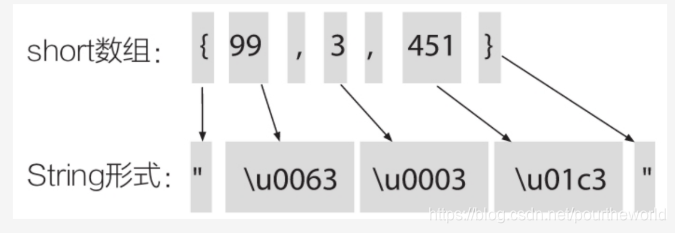
static string data="\u001\u002\u003"
即 将一个short数组翻译成16进制字符串。
编写批处理文件
-
创建一个ANTLR文件夹,将antlr-4.7.2-complete.jar包拖入。
-
进入ANTLR,创建test文件夹,进入test文件夹,创建src文件夹。
-
回到ANTLR,编写antlr.bat(之前的jdk、antlr已经安装并配置好了环境)
cd C:\Users\Administrator\Desktop\ANTLR\test\src java org.antlr.v4.Tool %* cd C:\Users\Administrator\Desktop\ANTLR注意ANTLR文件夹的位置根据自己电脑填写。
-
编写grun.bat
cd C:\Users\Administrator\Desktop\ANTLR\test\src java org.antlr.v4.gui.TestRig %* cd C:\Users\Administrator\Desktop\ANTLR -
编写clean.bat
rd /s /Q C:\Users\Administrator\Desktop\ANTLR\test\src md C:\Users\Administrator\Desktop\ANTLR\test\src
编写.g4格式的语法文件
编写完批处理文件以后,继续编写ArrayInit.g4语法文件。
- ArrayInit必须和文件名ArrayInit.g4匹配。
- 语法分析器的规则必须以小写字幕开头,词法分析器的规则必须大写开头。
//语法文件以grammar开头 //ArrayInit必须和文件名ArrayInit.g4匹配 grammar ArrayInit; //init规则:匹配一对花括号中的、逗号分隔的value init : '{' value (',' value)* '}'; //value可以是嵌套的花括号结构,也可以是一个简单整数,即INT词法符号 value : init | INT ; //语法分析器的规则必须以小写字幕开头,词法分析器的规则必须大写开头 //词法符号INT,由一个或者多个数字组成 INT : [0-9]+; //定义词法规则空白符号,丢弃 WS : [\t\r\n]+ -> skip;
运行ANTLR4工具
win+R,输入cmd,一路cd到你的ANTLR文件夹下,输入
antl4 ArrayInit.g4
此时来到test/src下,会生成以下文件:
 简单介绍一下生成的文件:
简单介绍一下生成的文件:
- ArrayInitParser.java:包含一个
语法分析器类的定义,用来识别语法ArrayInit。 - ArrayInitLexer.java:包含一个
词法分析器类的定义,识别语法中的词法规则和文法规则。 - ArrayInit.tokens:ANTLR会对每个词法符号指定
数字类型,这个关系保存在该文件中。有时候ANTLR会对一个大的语法切割,生成许多小语法,这个文件可以同步所有小语法的词法符号。 - ArrayInitListener.java ArrayInitBaseListener.java:我们输入的文本会被ANTLR语法分析器转换成一棵语法分析树。遍历这些语法分析树时,遍历器可以触发一系列回调事件。前者是回调事件的
定义,后者是实现。后者的好处在于我们可以只重写我们感兴趣的回调。
测试生成的语法分析器
我们来到test/src对.java文件先进行编译:
javac *.java
-
编译结束后,回到ANTLR文件夹输入
grun的词法符号测试:grun ArrayInit init -tokens {99,3,451} EOF(windows下是ctrl+z)我们会看到以下结果:

2. 回到ANTLR文件夹输入grun的语法分析树测试(init语法):grun ArrayInit init -tree {99,3,451} EOF(windows下是ctrl+z)我们会看到以下结果:

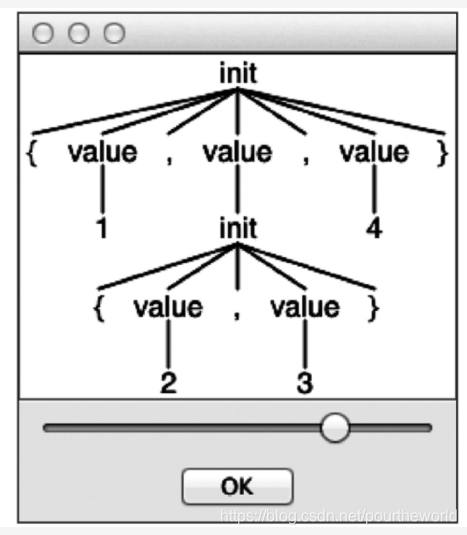
3. 回到ANTLR文件夹输入grun的可视化语法分析树测试(init语法):grun ArrayInit init -gui {1,{2,3},4} EOF(windows下是ctrl+z)我们会看到以下结果:
将语法分析器与Java程序集成(VsCode)
由于我们的项目比较简单,不用spring框架,安装完Java组件后,shift+ctrl+p,
create Java Project,直接回车,输入项目名,进入新的window:
在项目下创建一个lib文件夹,并将antlr-4.7.2-complete.jar包拖入,VsCode会自动关联。
再将语法分析器的.java文件以及.token文件拖入src文件夹中。
接下来我们开始编写翻译文件,进行集成。

我们的转换是直截了当的:将{和}翻译成”,将value翻译成\u+16进制即可。
因此我们需要重写之前说过的ArrayInitBaseListener类,也就是回调函数实现类:
//ShortToUnicodeString.java
public class ShortToUnicodeString extends ArrayInitBaseListener{
//将{翻译成"
@Override
public void enterInit(ArrayInitParser.InitContext ctx){
System.out.print('"');
}
//将}翻译成"
@Override
public void exitInit(ArrayInitParser.InitContext ctx){
System.out.print('"');
}
//将value翻译成\u+4位16进制形式
@Override
public void enterValue(ArrayInitParser.ValueContext ctx){
//假定不存在嵌套结构
int value=Integer.valueOf(ctx.INT().getText());
System.out.printf("\\u%04x",value);
}
}
重写完以后,我们编写主翻译程序:
//Translate.java
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
public class Translate {
public static void main(String[] args) throws Exception{
//新建CharStream,从标准输入读取数据
ANTLRInputStream input = new ANTLRInputStream(System.in);
//新建词法分析器,处理输入的CharStream
ArrayInitLexer lexer = new ArrayInitLexer(input);
//新建词法符号缓冲区,存储词法分析器生成的词法符号
CommonTokenStream tokens = new CommonTokenStream(lexer);
//新建语法分析器,处理词法符号缓冲区内容
ArrayInitParser parse = new ArrayInitParser(tokens);
//针对init规则,开始语法分析
ParseTree tree = parse.init();
//新建一个能够触发回调函数的语法分析树遍历器
ParseTreeWalker walker=new ParseTreeWalker();
//遍历语法分析过程中生成的语法分析树,触发回调
walker.walk(new ShortToUnicodeString(),tree);
System.out.println();
}
}
翻译程序测试
大功告成,让我们在VsCode中测试一下!
在控制台中输入{1,2,3},ctrl+z:
