文章目录
一、概念相关
1.爬虫
网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
2.需要的包
requests、beautifulsoup4,其他需要的包可以根据自己的需要下载。
二、爬取南阳理工学院ACM题目
1.网站分析
南阳理工学院ACM题目
通过查看网页源代码,可以发现,我们所需要的题号、标题、通过率等都存在于图TD标签内。

进入开发者模式,在搜索框内搜索td,可以发现存在700条相关数据,接下来只要将这700条数据爬取下来就可以了。
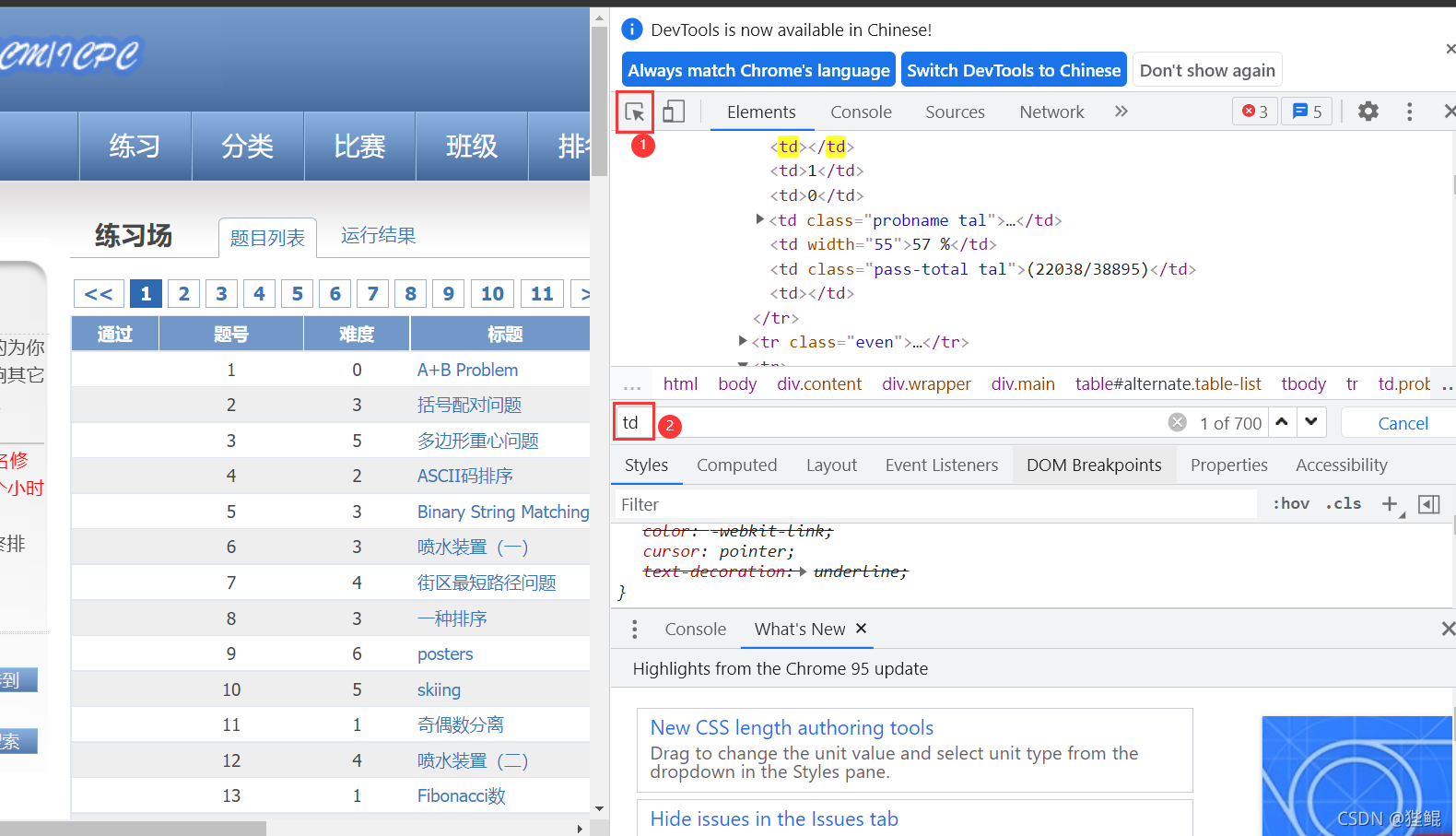
2.代码编译
导入头文件,定义模拟的浏览器以及表格形式
#导入包
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 题目数据
subjects = []
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
定义爬取函数,以及筛选条件
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
with open('D:\\try45\\pachong\\nylgoj.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
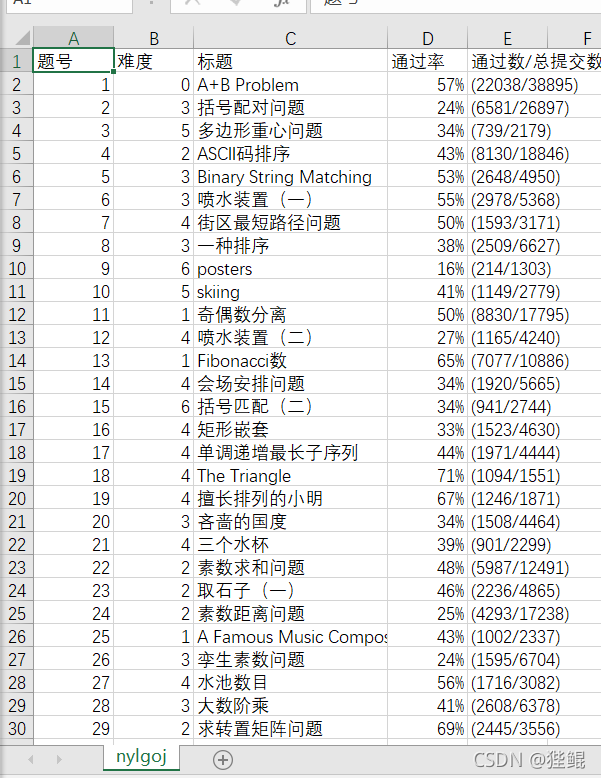
3.运行结果
三、爬取某知名大学官网通知
1.网站分析
一所知名大学
同样的查看网页源代码,可以找到对应的通知时间与标题

在网站内可以发现网站url与网站对应页数是恰好相反的,在爬取时要注意。
2.代码编译
导入头文件及定义文件格式
#导入包
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
# 模拟浏览器访问
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
定位标签获取页面
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#只靠标签这些定位好像不是唯一,只能手动定位了
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#删掉除页数以外的其他内容
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#转为数字
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
写入文件
def write_csv(cqjtu_info):
with open('D:\\try45\\pachong\\cqjtu.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('爬取信息成功')
page_num=get_page_number()#获得页数
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
3.运行结果

四、总结
学会了爬取网页数据,初步的了解了如何使用python爬虫,以及对于一个网页的详细分析。
参考链接
版权声明:本文为weixin_54089068原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。