前言:在比赛中遇到关于样本不均衡问题,特地过来补补知识点!
1、smote原理
过采样的技术有非常多,最常见的就是随机过采样和SMOTE过采样。
随机过采样就是从少的类中进行随机进行采样然后拼接上去,这种效果很多时候和加权差不大。还有一种较常见的也是现在比赛中出现最多的采样方法,SMOTE采样。
SMOTE的示意图如下,

SMOTE算法的生成过程为:
- 对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
- 根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
- 对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本
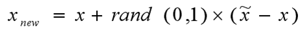
2、smote缺点
从算法中,我们可以发现,SMOTE采样其实就是生成样本之间的一些样本。
但是因为思路简单,我们也很容易就可以发现SMOTE算法的一些缺点。
- 在近邻选择时,K值的决定一般较难,可以枚举然后根据实验效果来定;
- 算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。如果正样本都分布在边缘,我们通过采样正样本来生成样本,那么这样新生成的样本将也会全部在边缘,且会越来越边缘化,从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善,但有时也会加大了分类算法进行分类的难度.
3、Python实现smote
import random
from sklearn.neighbors import NearestNeighbors
import numpy as np
class Smote:
"""
SMOTE过采样算法.
Parameters:
-----------
k: int
选取的近邻数目.
sampling_rate: int
采样倍数, attention sampling_rate < k.
newindex: int
生成的新样本(合成样本)的索引号.
"""
def __init__(self, sampling_rate=5, k=5):
self.sampling_rate = sampling_rate
self.k = k
self.newindex = 0
def fit(self, X, y=None):
if y is not None:
negative_X = X[y==0]
X = X[y==1]
n_samples, n_features = X.shape
# 初始化一个矩阵, 用来存储合成样本
self.synthetic = np.zeros((n_samples * self.sampling_rate, n_features))
# 找出正样本集(数据集X)中的每一个样本在数据集X中的k个近邻
knn = NearestNeighbors(n_neighbors=self.k).fit(X)
for i in range(len(X)):
k_neighbors = knn.kneighbors(X[i].reshape(1,-1),
return_distance=False)[0]
# 对正样本集(minority class samples)中每个样本, 分别根据其k个近邻生成
# sampling_rate个新的样本
self.synthetic_samples(X, i, k_neighbors)
if y is not None:
return ( np.concatenate((self.synthetic, X, negative_X), axis=0),
np.concatenate(([1]*(len(self.synthetic)+len(X)), y[y==0]), axis=0) )
return np.concatenate((self.synthetic, X), axis=0)
# 对正样本集(minority class samples)中每个样本, 分别根据其k个近邻生成sampling_rate个新的样本
def synthetic_samples(self, X, i, k_neighbors):
for j in range(self.sampling_rate):
# 从k个近邻里面随机选择一个近邻
neighbor = np.random.choice(k_neighbors)
# 计算样本X[i]与刚刚选择的近邻的差
diff = X[neighbor] - X[i]
# 生成新的数据
self.synthetic[self.newindex] = X[i] + random.random() * diff
self.newindex += 1
X=np.array([[1,2,3],[3,4,6],[2,2,1],[3,5,2],[5,3,4],[3,2,4]])
y = np.array([1, 1, 1, 0, 0, 0])
smote=Smote(sampling_rate=1, k=5)
print(smote.fit(X))
4 调包使用及调参
主要可参考——》官网链接
这里罗列下几个重要的参数:
k_neighbors:int或object,默认= 5
对于smote的调参主要是调k_neighbors参数,在一定程度上会影响模型的精度
版权声明:本文为The_dream1原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。