理解自 周志华《机器学习》
在强化学习的过程中,首先是对强化学习的理解,可用马尔可夫决策过程(Markov Decision Process, MDP)来理解:
机器处于环境E中,状态空间为
X
X
X,其中每个状态
x
∈
X
x∈X
x∈X是机器感知到的环境的描述,机器能采取的动作构成了动作空间
A
A
A,若某个动作
a
∈
A
a∈A
a∈A作用在当前状态
x
x
x上,则潜在的转移函数
P
P
P将使得环境从当前状态按某种概率转移到另一个状态,同时,环境会根据潜在的“奖赏函数
R
R
R”反馈给机器一个奖赏。
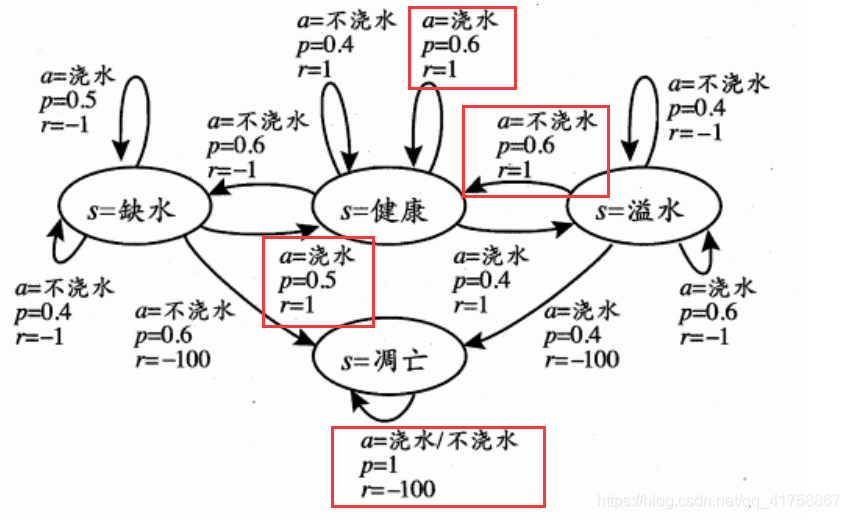
在上述图片中,最优策略为:在“健康”状态时选择“浇水”、在“溢水”状态时选择“不浇水”、在“缺水”状态时选择“浇水”、在“凋亡”状态时选择”浇水“货”不浇水“都可以。上述最优策略使根据动作所对应
p
p
p(概率)来得出最优奖赏的过程。
机器的任务就是通过在环境中不断城市而学得一个”策略“(policy)
π
\pi
π,根据这个策略,在状态
x
x
x下就能得知要执行的动作
a
=
π
(
x
)
a=\pi(x)
a=π(x)。策略有两种:
确定性策略:表示为
π
:
X
\pi:X
π:X➡
A
A
A,即一个状态
x
x
x下对应一个确定的动作
a
a
a下。
随机性策略:表示为π
:
X
\pi:X
π:X×
A
A
A➡
R
R
R,其中
π
(
x
,
a
)
\pi(x,a)
π(x,a)表示状态
x
x
x下选择动作
a
a
a的概率,并且不同状态对应的概率之和为1。
强化学习与监督学习的区别
若状态对应示例,动作对应标记,则策略相当于分类器(离散)或者回归器(连续)。但强化学习中没有有标记样本,在某种意义上可看作”具有延迟标记信息“的监督学习问题。