MQ使用场景
-
流程异步化
-
业务解耦
-
流量削峰填谷
RabbitMQ核心概念
先来看一眼rabbitMQ的架构图:
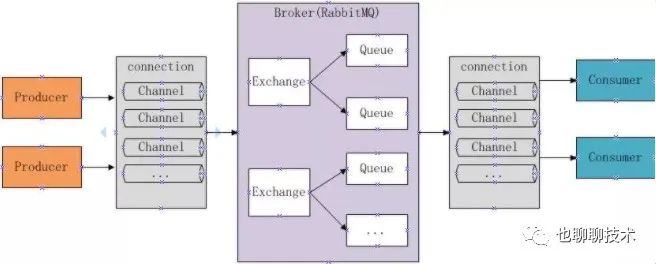
-
broker:接受客户端连接,实现AMQP协议。
-
connection:和具体broker建立网络连接。
-
channel:逻辑概念,几乎所有操作都在channel中进行,channel是消息读写的通道,一个connection可以建立多个channel。
-
message:应用程序和broker之间传递的数据,由properties和body组成。properties可以对消息进行修饰,比如消息的TTL,correlationId等高级特性;body是消息实体内容。
-
Virtual host:虚拟主机,用于逻辑隔离,最上层消息的路由。一个Virtual host可以若干个Exchange和Queue,同一个Virtual host不能有同名的Exchange或Queue。
-
Exchange:交换器,接受消息,根据路由键转发消息到绑定的队列上。
-
binding:Exchange和Queue之间的绑定关系,告诉exchange把消息路由到哪个队列
-
routing key:exchange结合routing key来确定如何路由一条消息。
-
Queue:消息队列,用来存放消息的队列。
消息确认机制
结合上图中消息发送的链路, 我们可以看出一条消息发出去后可能在哪些环节出问题:
-
Producer发出后由于网络故障Broker没有收到
-
Producer发出后Broker宕机导致消息丢失
-
Broker发送给Consumer后由于网络故障Consumer没有收到
-
Broker发送给Consumer后Consumer宕机导致没有处理
RabbitMQ提供了发布者确认和消费者确认机制来解决这些问题,发布者确认是指Broker收到Producer的消息后,会给Producer发送一条确认消息,如果消息的durable属性为
true, Broker会等消息成功持久化到磁盘后再发送publisher-confirm,发布者确认是异步的,不会影响发布的性能;消费者确认是指消费者收到消息后需要发送一条确认消息给
broker(可以开启自动确认模式,但可能丢消息),broker如果没有收到consumer的确认,会把消息重发.
生产者增加确认机制非常简单,channel开启confirm模式,然后增加监听, 如果使用的spring-rabbit框架, 把connection-factory的publisher-confirms配置为true,
并在RabbitTemplate配置一个confirm-callback的Listener:
|
|
有一些场景, 我们需要确保消息被正确的路由到队列:
-
如果消息发送到交换器后找不到可路由的队列,这时候消息会被丢弃, publisher-confirm返回的ack为true,相当于消息石沉大海了.
这种情况需要发送的时候把mandatory设置true,并且设置一个return-callback,当RabbitMQ找不到可路由的队列时返回publish-return告诉你无法路由的原因,可以记录日志或者重试.
如果用的spring-rabbit框架,把rabbit:template的mandatory属性设置为true,并且配置return-callback,只配置return-callback没有配置mandatory时callback不会生效
|
|
-
消息被拒绝时进入死信队列
设想有这种场景, Consumer侧接收消息的Listener抛出了未捕获的异常, spring-rabbit的默认处理策略是返回Basic.Reject给broker,并且设置requeue=true,
消息会被重新入队列再次被消费,如果这种异常是无法恢复的,消息会一直在Broker和消费者之间流转,这可能不是我们期望的逻辑,比较好的方式是把消息放入死信队列,
后面修复程序后再对死信队列中的消息进行消费.
消息变为死信的几种情况:
- 消息被拒绝(basic.reject/basic.nack)同时requeue=false(不重回队列)
- TTL过期
- 队列达到最大长度
死信队列如何使用,以spring-rabbit为例:
rabbit:listener-container 把requeue-rejected属性设置为false,表示消息拒绝时不再重新入队列, exchange配置x-dead-letter-exchange(在后台或者代码中给
死信交换器绑定好死信队列)
|
|
配置好之后如果消费者出现未捕获的异常,或者消费者手动抛出AmqpRejectAndDontRequeueException,消息会进入到死信队列
-
消息进死信队列前重试几次
考虑这样一种场景, 收到rabbitMQ消息后调用RPC接口请求数据超时了,可能只是网络抖动或者服务端突然响应慢了一下导致的, 这种情况下可以在消费端结合spring-retry
框架进行重试, 需要特别注意的是spring-retry重试是在当前接收线程处理的,重试的次数和总时长不应太长,否则如果重试一直失败会严重影响性能,spring-rabbit
和spring-retry结合起来也很方便,配置如下:
|
|
高可用
为了防止丢消息,交换器,队列和消息都应该设置成持久化,具体配置就是把durable设置为true.
我们线上的RabbitMQ采用的是集群模式,集群模式下所有节点会存储交换器和绑定关系以及队列的名字, 但是队列只存储在某一个节点,如果某个节点出现故障, 该节点上的
队列将会不可用,公司6月4号出现过一次交换机故障导致RabbitMQ集群脑裂的场景, 就算网络恢复了脑裂的状态还是一直保持,需要重启集群的一个节点才能解决,由于我们用的
是虚拟IP去连的集群的一个节点,如果你请求的队列是在另一个节点上RabbitMQ会给你返回404 queue not exist,spring-rabbit遇到这个错误会重启Consumer线程
,然后重新尝试创建队列,由于队列的元数据已有了, 在脑裂期间是无法再创建该队列的,spring默认只重试3次,每次间隔5s,如果15s内集群未恢复,你的rabbit消费者就死掉了,
需要重启业务进程解决,针对这个问题可以把rabbit:listener-container的declaration-retries设置的大一些, 这样集群恢复的时候consumer会自动恢复无需重启.
为了应对操作系统重启,掉电导致未及时fsync刷盘的场景,可以采用镜像队列, 镜像队列可以在rabbitmq管理后台配置策略, 从而解决队列单点故障问题.
配置了镜像队列后, 集群会自动选举一个rabbit节点为Master节点,再往镜像队列发送数据时,Rabbit会把数据发给所有节点中的队列,从而保证高可用.
镜像队列的架构如下: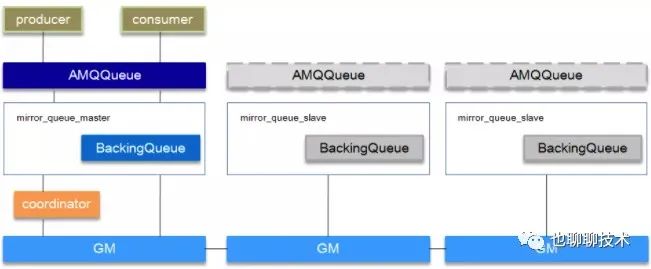
监控
Rabbit管理后台上的监控是基于connection,exchange,queue, 很多时候发现某个队列积压了,但并不知道队列是谁创建的,只能在群里@所有人, 其实RabbitMQ是
提供了关联应用的能力,创建队列时可以加上队列参数,如下所示:
|
|
RabbitMQ会为每个consumer分配一个ConsumerTag,客户端可以自己指定,如果没指定,RabbitMQ会自动创建一个随机的,有时候想知道某个队列是谁在消费,
spring-rabbit提供了consumer-tag-strategy这个属性来配置一个生成ConsumerTag的Bean:
|
|
最后可以在rabbit后台看到队列的创建者和消费者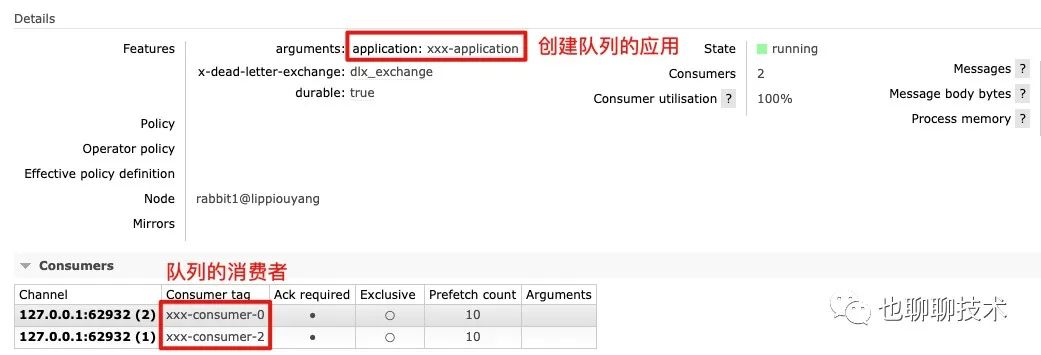
发布线程阻塞
rabbitmq在资源不足时会给所有Publish Connection发送Connection.Blocked指令, 这时候所有的Producer都无法发送信息, 在极端情况下会导致大部分线程都
阻塞在Rabbit的发送, AMQP的connection提供了BlockListener和UnBlockListener,业务方可以实现对应的Listener, 在连接被Block住后把消息写入到磁盘或者数据库,等
恢复后再从磁盘或数据库中恢复重新发送,避免进程卡死的情况.
|
|