垃圾清除算法(看笔记):
1.标记清除算法。
2.复制算法(年轻代算法):每次只能使用半个空间。
3.标记整理算法(老年代算法),就是整理到一边,整理过程中拦路的清除。

4.分代收集算法。

—
标记清除,复制,标记整理,分代回收。
—|—|—|—|—|—|—|—|—|—|—|—|—
垃圾搜集器就是这些算法的具体实现。
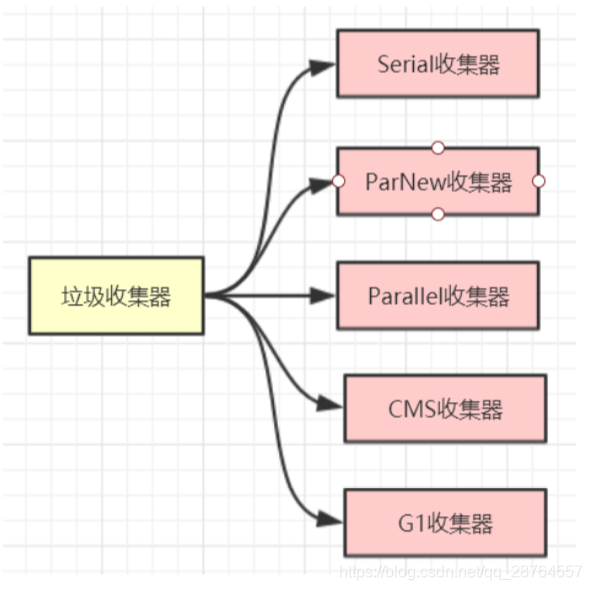
—
CMS垃圾收集器和G1垃圾收集器

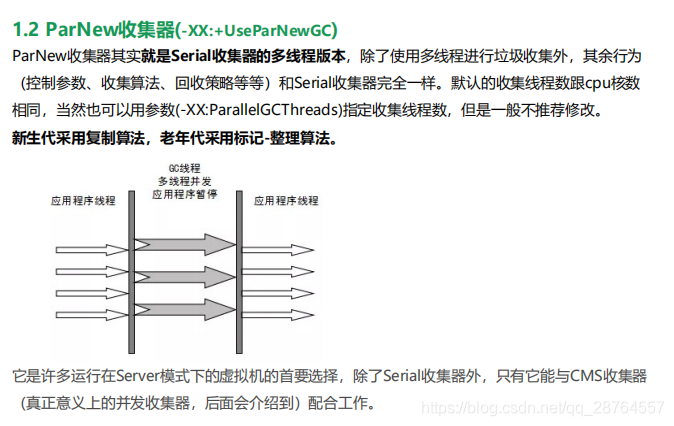

CMS垃圾收集器(只能用在老年代上面):


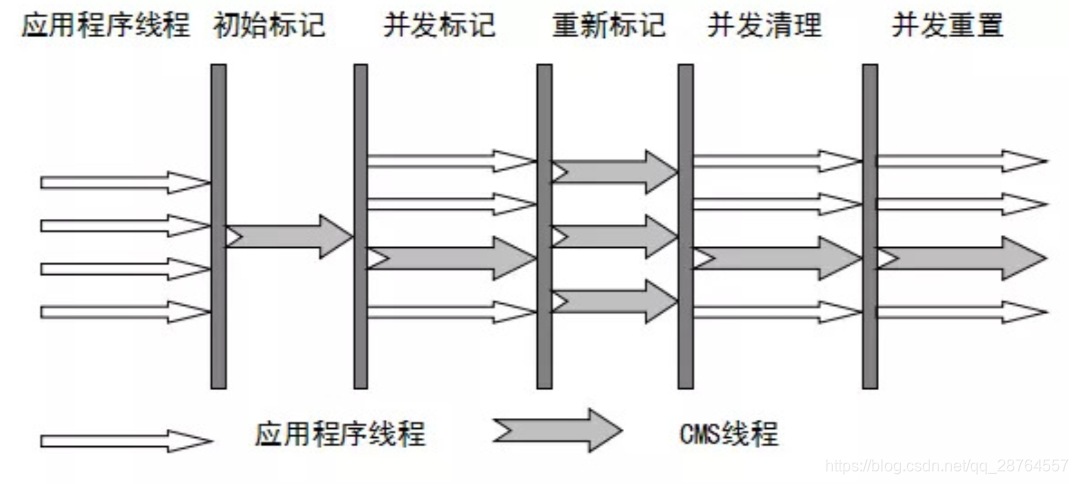
初始标记:只找到gcRoot根的直接引用对象。
并发标记:继续找,直到全部找完,找完之后,全部的标记完毕,最耗时间的,占了百分之八十时间。
重新标记:修正并发标记新产生的标记。
并发清理:并发清理过程中又产生了垃圾,不会清除,为浮动垃圾,下一次gc再去清理。
并发重置:整理内存碎片。

CMS的相关参数:
X越多代表命令的版本越不稳定。
—
下半节课53:46
—

CMS的参数:启用 并发的线程数 fullGC后做压缩整理 多少次压缩之后做碎片整理 老年代使用多少会引发fullGC(在回收时间的回收次数之间的平衡) 只使用设定的阈值 CMS GC前启动一次minor gc(https://www.zhihu.com/question/61090975),最后一个是减少闭环遍历的对象。
—
为什么设置老年代gc的比例 因为full gc时间会很长的。只是第一次,第二次是自己的内部去优化的。
—
年轻代是perNew 老年代是CMS

案例:亿级别流量的电商网站,每个用户点击二三十次,日活用户500万。转化率百分之十,就是50万。三到四个小时产生。每秒也就几十单。大促每秒1000多单。
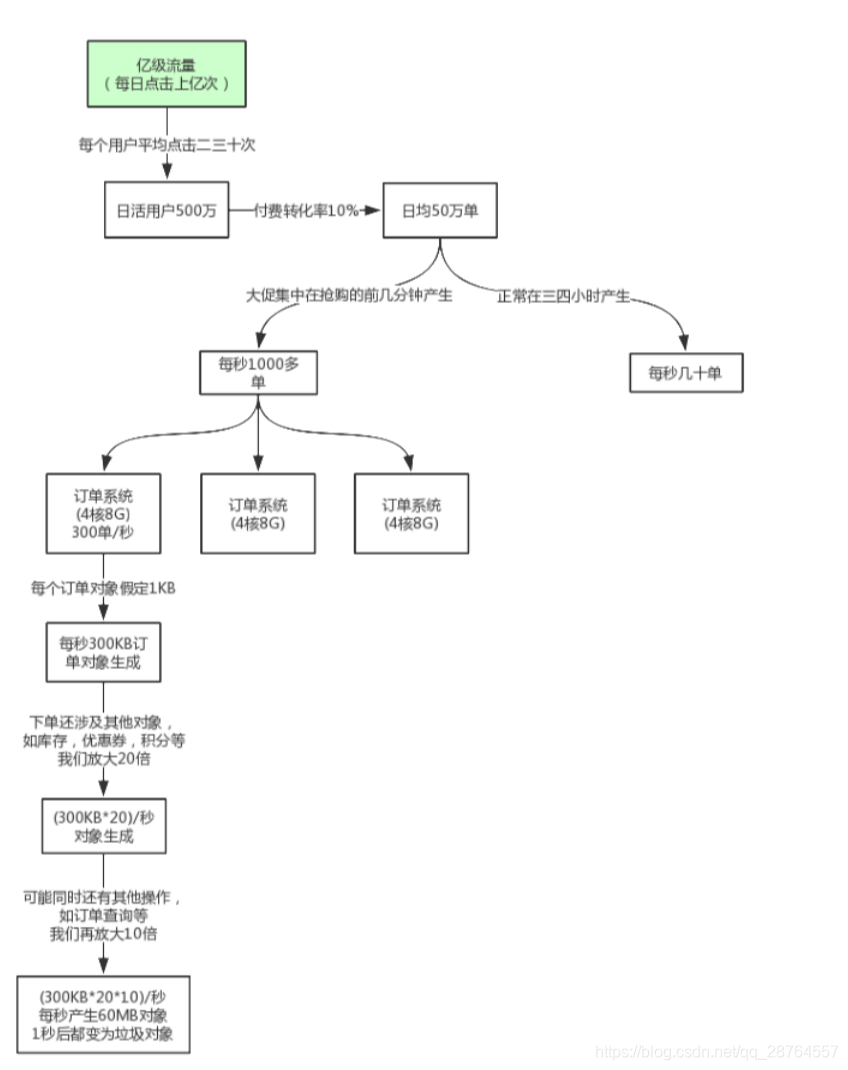
堆内存小,回收的频繁,但是订单的周期长,一次订单会有多次的回收,就都进入到老年代了,不及时释放就会内存溢出的。
如何设置参数:
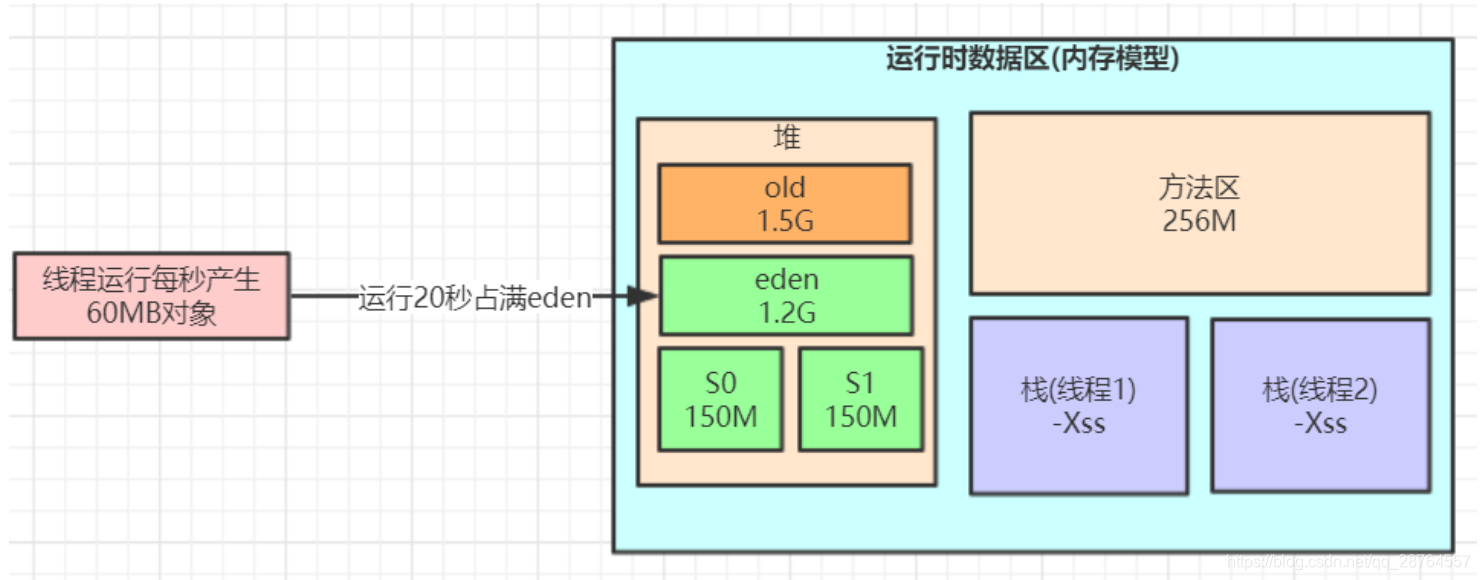
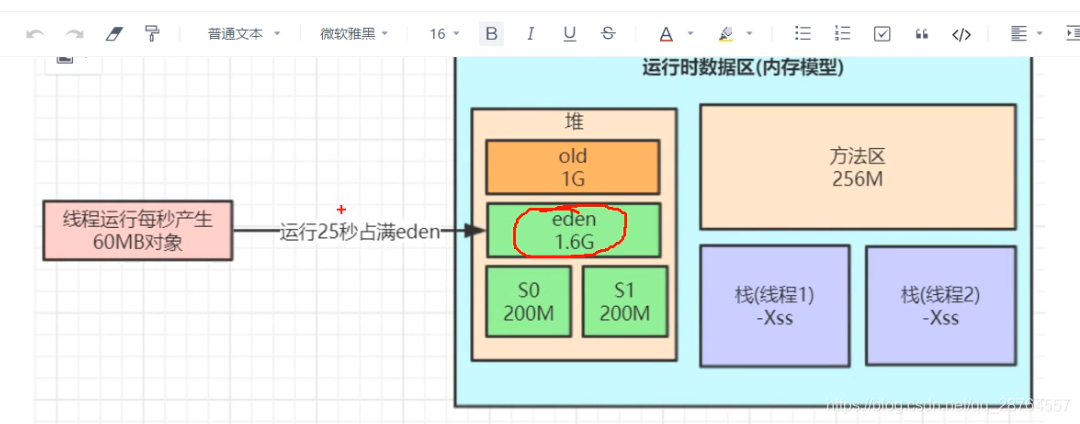
对于8G的内存是如何分配的?

8G的内存,我们把4-5G分配给jvm。那么我们的整个堆可能就3G多一点。
堆:https://blog.csdn.net/yrwan95/article/details/82826519
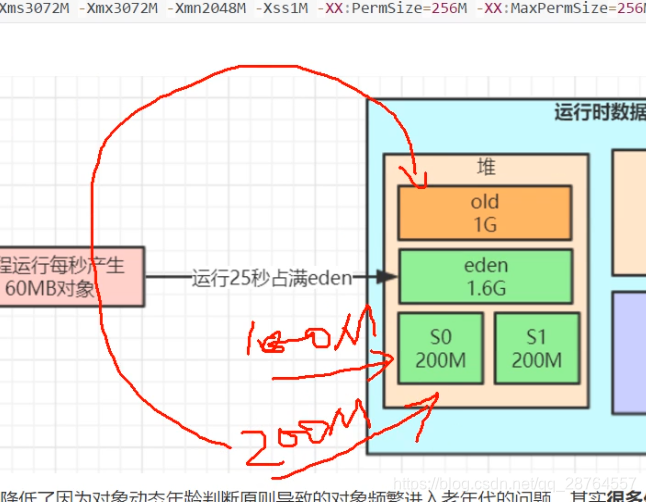
每秒60M则20s执行一次min gc。一般百分之95都被清除了。就是在回收之前的剩下的几秒没被清理。也就是100多M。会放在surviver区里面。
放在了from里面,我们判断是不是能放进去呢?100M放在150M里面。
要看下from和to区域的动态年龄判断。

答案是不能要直接进入了老年代。
进入老年代又变为了垃圾对象,这样是不合适的。
优化点:
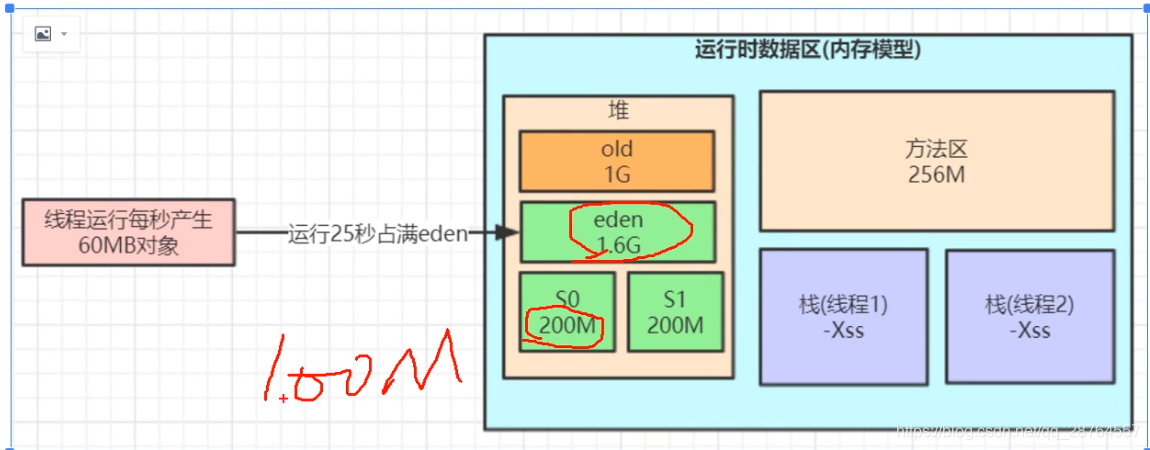
1.调整比例,放大from和to区域:

2.年轻代调大一点

—————————————————————-
还有其他的调优的方法吗?
优化方法1:

不是15次了,而是5次。25s(25*60=1500=1.5g)一次min gc,五次就是2-3分钟。就是老不死的对象,越早放在老年代越好,比如spring的bean。
这样可以减少复制。老不死的放在老年代是应该的,而不是放在老年代就变为垃圾对象,这样的是不应该放在老年代的。
—
优化方法2:


优化方法3:大对象,大多数对象不会超过1M或者2M。
大对象要不是缓存的数据,要不就是其他的有用的数据,这些迟早要进入到老年代里面。
我们设置大对象为1M就直接放在老年代:

—
优化方法4:.老年代的担保机制:
在每次minor gc之前判断下。
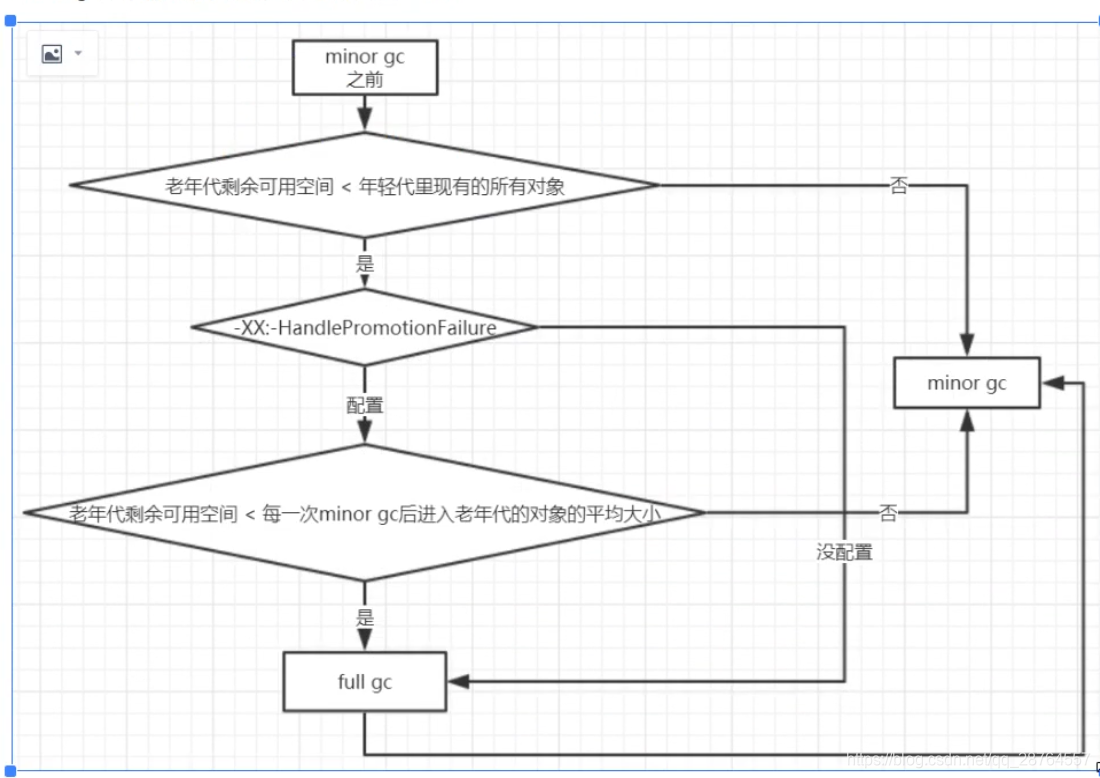
会不会由于老年代分配担保失败导致的full gc。
集合这个图:
忽然业务暴增,每秒处理上千单,每次订单的时间变长,eden的回收只有百分之70。回收不掉一下子suirvivor代可能会有200M过来了,放不下,进老年代的多了。
大促就是前10十几分钟。
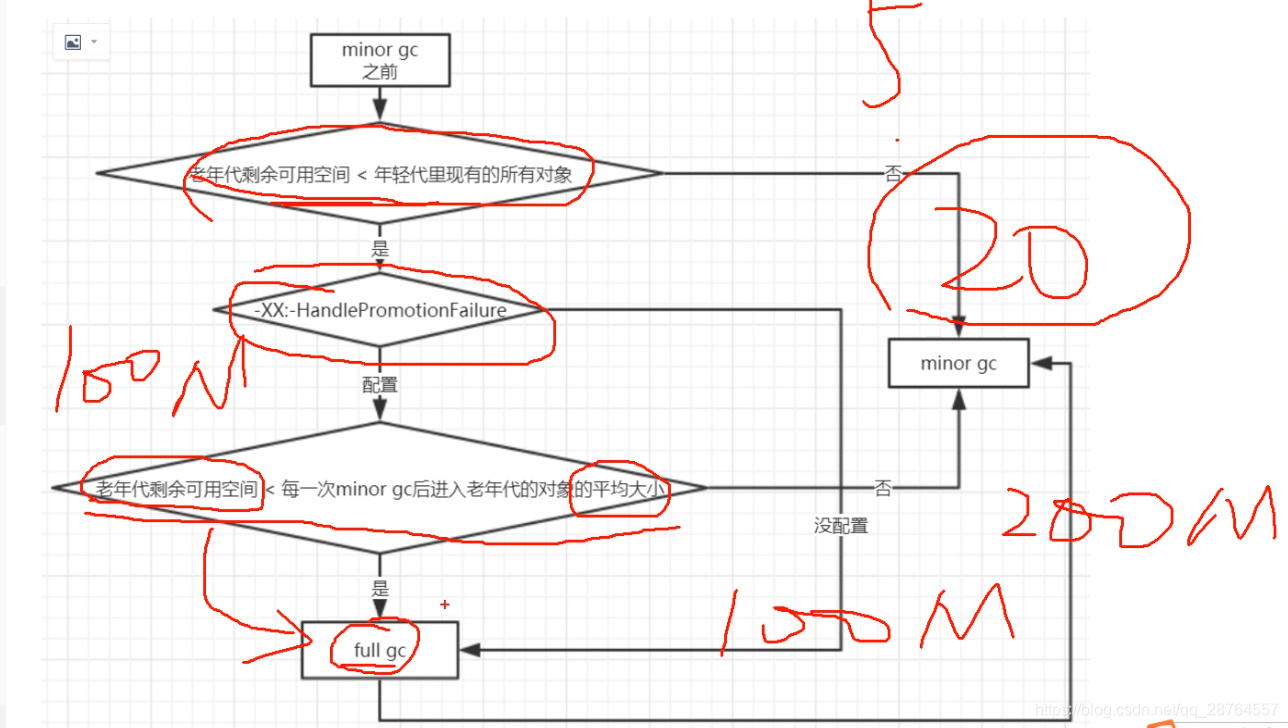
不在一开始full gc就可以。一二十分钟才会进行full gc此时已经大促完毕了。
流量暴增,这个几分钟才发生一次。

可能流量激增导致很大,但是历次的平均值还是差不多的。
只要不是每次min gc都触发full gc就可以了。
不是每次min gc都有大量对象进入老年代,都会触发full gc就可以了。
—
做好调整的比例,最好大多数短期存活的对象都在年轻代被清理掉。例如每次不到100M到surviver,下次就清理掉了。
—
一般新生代的preNew老年代是cms
参数:百分之92才会触发full gc。

每做完一次full gc做一次碎片整理,或者几次full gc做一次。
![]()
开启碎片整理,整理的每5次fullgc都会做一个碎片整理。
![]()
新生代是preNew 老年代是CMS
—
跨代引用:
老年代对年轻代的引用是什么?
假设user对象进入了老年代:
![]()
其中有一个成员变量引用,new一个对象就是老年代的一个成员变量对年轻代的引用。