1.首先,我们先来导我们需要的包:
G:\hadoop\hadoop-2.7.6\share\hadoop\mapreduce
G:\hadoop\hadoop-2.7.6\share\hadoop\common
G:\hadoop\hadoop-2.7.6\share\hadoop\mapreduce\lib
G:\hadoop\hadoop-2.7.6\share\hadoop\common\lib
G:\hadoop\hadoop-2.7.6\share\hadoop\yarn
G:\hadoop\hadoop-2.7.6\share\hadoop\yarn\lib
G:\hadoop\hadoop-2.7.6\share\hadoop\hdfs
G:\hadoop\hadoop-2.7.6\share\hadoop\hdfs\lib
简单的MapReduce程序的实习步骤:
1. 编程Mapper类
继承Mapper类,实现其中的setup()、map()、cleanup()方法。如果是简单的实现,可以只实现map()方法
2. 编写Reducer类
继承Reducer类,实现其中的setup()、map()、cleanup()方法。
3. 编写Driver类
在main方法里定义运行作业,定义一个job,在这里控制obj如何运行等。
4. 将编写好的程序打成jar包,然后放到Hadoop服务器中
使用hadoop jar <[项目名].jar> com.yc.*.<主类名> 即可
2.然后我们先把一个Word.txt上传到Hadoop里


接下来编写三个类
Map类:
package wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
*
* @author ASUS
*第一个 第二个参数表示输入的key和value的类型 从inputformat传过来的 key默认是字符偏移量 value默认是一行数据
*第三个第四个参数表示输出的Key value类型
*第一个参数 一般用Long类型 指定字符的偏移量 一般不会使用
*第二个参数 表示一行数据的类型 对于文本而言 用String类型
*第三个参数 表示输出的键的类型 格式为 <hello,1> 所以类型是String
*第四个参数 表示输出的值的类型 Integer
*
*但是如果我们直接写Mapper<Long,String,String,Integer>会报错
*/
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
//得到这一行数据后 应该根据空格分隔成一个一个单词
String [] strs=value.toString().split("");
//循环读取每个单词 发送到map中 通过上下文传递出去
for (String str :strs){
context.write(new Text(str), new IntWritable(1));
}
}
}
Reduce类:
package wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int total=0;
for(IntWritable iw :values){
total+=iw.get();
}
context.write(key, new IntWritable(total));
}
}
Job类:
package wordcount;
/**
* 将Map和reduce关联起来
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountJob {
public static void main(String[] args) {
try {
// 创建一个job
System.setProperty("HADOOP_USER_NAME", "cc");
Job job = Job.getInstance(new Configuration());
job.setJobName("WordCountTest"); // 给这个统计任务取一个名称
job.setJarByClass(WordCountJob.class); // 设置这个任务的入口 即main方法所在的类
// 让这个任务跟map关联
job.setMapperClass(WordCountMap.class);
// 让这个任务和reduce关联
job.setReducerClass(WordCountReduce.class);
// 设置map的输出的key 和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定要统计的源数据文件
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.244.129:9000/user/cc/word.txt"));
// 指定统计后的结果数据的文件路径
// 注意点1 输出路径不能存在
// 注意点2 需要导入yarn和yarn/lib中的包
// 注意点3 将Windows中hadoop的路径配置到系统环境变量中
// 注意点4 将hadoop.dll和winutils.exe放到hadoop\bin下
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.244.129:9000/user/cc/wordcount"));
System.out.println(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
调试的时候可能会报权限不足 ,那我们就给它加权限:
(Hadoop)Permission denied: user=XXXX, access=WRITE, inode=”/XXX”:root:supergroup:drwxr-xr-x
配置一个环境变量HADOOP_USER_NAME 值为Linux用户登录名,重启eclipse 即可。一次修改受用终生
给予hdfs系统里user的所有权限即可
接下来我们去页面看一下:
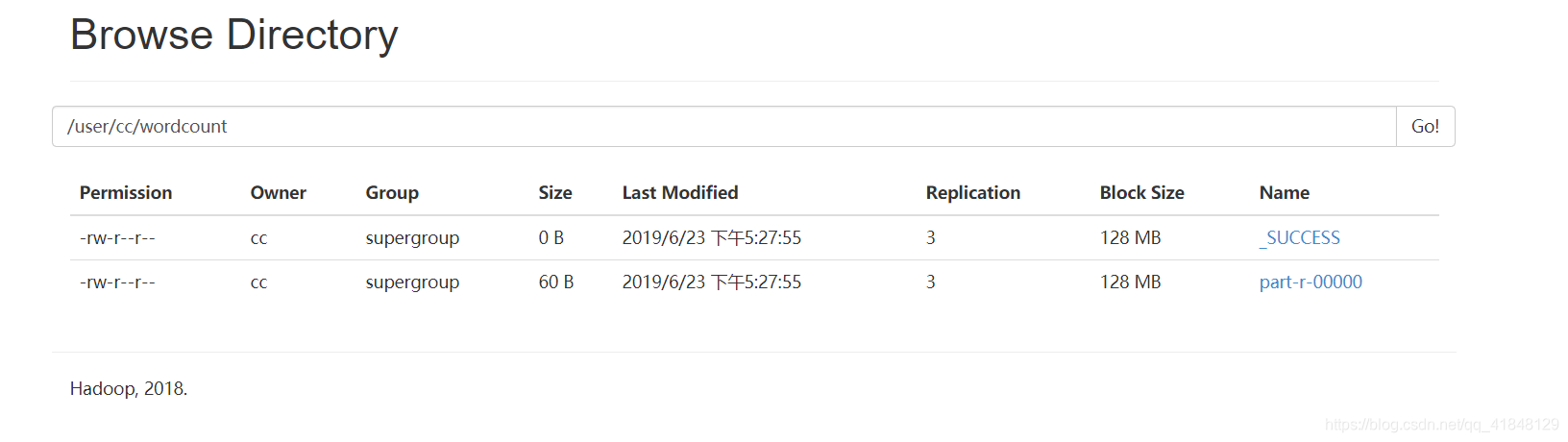
我们发现在这个目录下有俩个文件,第二个文件是我们所关注的–> part-r-00000
打开看看~

这样,我们的简单的测试就成功了