文章目录
伪集群的一键安装
推荐一篇不错的文章,真的一行命令自动配置、自动运行,省时费力
使用Windows连接hadoop需要下载安装好winutils.exe、hadoop.dll等插件才能正常连接
SpringBoot使用HDFS做文件内容的读取和追加
这里假设云服务器的ip为:192.168.110.120
记得修改Windows的hosts文件使主机的datanode名称能映射成192.168.110.120
HadoopConfig
@Configuration
public class HadoopConfig {
@Bean("hdfsConfig")
public org.apache.hadoop.conf.Configuration hdfsChannel(){
org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration();
conf.set("dfs.replication", "1");
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("mapred.job.tracker", "hdfs://192.168.110.120:8020/");
conf.set("fs.defaultFS", "hdfs://192.168.110.120:8020/");
System.setProperty("HADOOP_USER_NAME","root");
return conf;
}
@Bean("fileSystem")
public FileSystem createFs(@Qualifier("hdfsConfig") org.apache.hadoop.conf.Configuration conf){
FileSystem fs = null;
try {
URI uri = new URI("hdfs://192.168.110.120:8020/");
fs = FileSystem.get(uri,conf);
} catch (Exception e) {
e.printStackTrace();
}
return fs;
}
}
HadoopController
@RestController
@RequestMapping(value = "/hadoop")
public class HadoopController {
@Autowired
private HadoopTemplate template;
@GetMapping(value = "/read")
public String read(@RequestParam("name") String name){
template.readTo(template.getNameSpace(),"/"+name,4096);
return "read success";
}
@GetMapping(value = "/write")
public String weite(@RequestParam("name") String name,@RequestParam("content") String content){
template.writeToHDFS(template.getNameSpace(),"/"+name,content);
return "write success";
}
}
HadoopTemplate
@Service
@ConditionalOnBean(FileSystem.class)
public class HadoopTemplate {
@Autowired
private FileSystem fileSystem;
private String nameSpace="/test";
@PostConstruct
public void init(){
existDir(nameSpace,true);
}
public String getNameSpace() {
return nameSpace;
}
/**
* 获取根目录的储存使用量
* @return
*/
@SneakyThrows
public ContentSummary getRootQuota(){
return fileSystem.getContentSummary(new Path( "/"));
}
/**
* 获取当前目录列表的所有文件信息
* @param path
* @return
*/
public List<FileStatus> getDirList(String path){
List<FileStatus> list = new ArrayList<>();
try {
FileStatus[] statuses = fileSystem.listStatus(new Path(path));
list.addAll(Arrays.stream(statuses).collect(Collectors.toList()));
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
/**
* 文件内容的读取
* @param path 目录
* @param fileName 文件名
*/
public String readContent(String path,String fileName) {
HashSet<String> rowSet = new HashSet<>();
StringBuilder content = new StringBuilder();
FSDataInputStream fin = null;
BufferedReader in = null;
String line;
try {
fin = fileSystem.open(new Path(path + "/" +fileName));
in = new BufferedReader(new InputStreamReader(fin, "UTF-8"));
while ((line = in.readLine()) != null) {
rowSet.add(line + "\n");
}
// System.out.println(rowSet.size());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fin!=null){
fin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
for(String row : rowSet){
content.append(row);
}
return content.toString();
}
/**
* 文件读取到控制台输出
* @param path 目录
* @param fileName 文件名
* @param size 读取大小
*/
public void readTo(String path,String fileName,int size) {
FSDataInputStream fsDataInputStream = null;
try {
fsDataInputStream = fileSystem.open(new Path(path + "/" +fileName));
IOUtils.copyBytes(fsDataInputStream, System.out, size, false);
System.out.println();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fsDataInputStream!=null){
fsDataInputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 文件内容的写入与追加
* @param path 目录
* @param fileName 文件名
* @param content 追加的内容
*/
public void writeToHDFS(String path,String fileName,String content) {
FSDataOutputStream fsDataOutputStream = null;
try {
Path hdfsPath = new Path(path + "/" +fileName);
if (!fileSystem.exists(hdfsPath)) {
fsDataOutputStream = fileSystem.create(hdfsPath,false);
fsDataOutputStream.writeBytes(content);
}else{
fsDataOutputStream = fileSystem.append(hdfsPath);
fsDataOutputStream.writeBytes("\n"+content);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fsDataOutputStream!=null){
fsDataOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
SpringBoot封装MapReduce的WordCount做字符统计
注意:如果输出路径事先存在则会执行失败
HadoopController
@RestController
@RequestMapping(value = "/hadoop")
public class HadoopController {
@Qualifier("hdfsConfig")
@Autowired
private org.apache.hadoop.conf.Configuration conf;
@GetMapping(value = "/reduce")
public Boolean reduce() throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(conf);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(template.getNameSpace())); //输入路径
FileOutputFormat.setOutputPath(job, new Path("/statics")); //输出路径
return job.waitForCompletion(true);
}
}
WordCountMapper
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); // 获取一行
String[] words = line.split(" ");// 切割
for (String word : words) {
outK.set(word);
context.write(outK, outV); // 写出
}
}
}
WordCountReducer
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get(); // 累加
}
outV.set(sum);
context.write(key,outV);// 写出
}
}
最后测试
- 追加成功
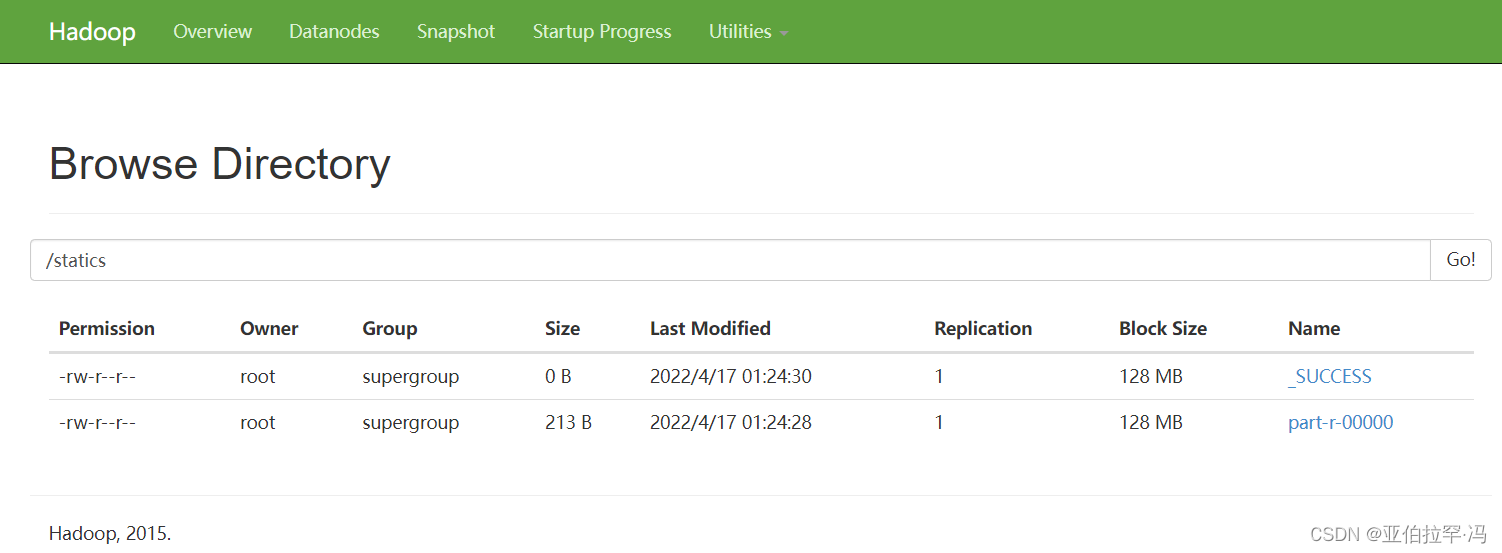
- 计算成功

版权声明:本文为FHlang原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。