每天都在和你在一起
Spark Group By函数将相同的数据收集到DataFrame/DataSet上的组,并对分组后的数据执行聚合函数。
- count() 返回每个组的行数
- mean() 返回每个组的平均值
- max() 返回每个组的最大值
- min() 返回每个组的最小值
- sum() 返回每个组的值的总计
- avg() 返回每个组的平均值
使用agg函数,可以一次进行多次聚合运算
创建DataFrame
val data = Seq(("James", "Sales", "NY", 90000, 34, 10000),
("Michael", "Sales", "NY", 86000, 56, 20000),
("Robert", "Sales", "CA", 81000, 30, 23000),
("Maria", "Finance", "CA", 90000, 24, 23000),
("Raman", "Finance", "CA", 99000, 40, 24000),
("Scott", "Finance", "NY", 83000, 36, 19000),
("Jen", "Finance", "NY", 79000, 53, 15000),
("Jeff", "Marketing", "CA", 80000, 25, 18000),
("Kumar", "Marketing", "NY", 91000, 50, 21000) )
val dataFrame = data.toDF("employee_name", "department",
"state", "salary", "age", "bonus")
dataFrame.show()group By聚合在DataFrame列上
dataFrame.groupBy(dataFrame("department")).sum("salary").show(false)如果用SQL来理解的话,是这样的
select sum(salary) from table group by department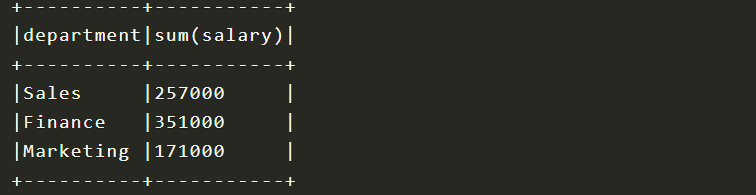
总的来说,group by之后,后面跟的sum,min,max,avg等等可以是其它的列。如果使用count的话,那么就是求分组字段出现的次数。
下面介绍一下agg
dataFrame.groupBy("department").agg(
sum("salary").as("sum_salary"),
avg("salary").as("avg_Salary"),
sum("bonus").as("sum_bonus") )
.filter(col("sum_bonus") >= 50000).show()可以在agg里面进行多个聚合,不过需要注意的是,我们在上面sum(“salary”)之后,起别名用的是sum_salary。如果下面filter过滤的时候使用
filter(datafrmae(“sum_salary”))是会报错的,很简单,因为在group by +agg之后就形成了一个新的DataFrame,如果还在使用原来的DataFrame,就会报错,因为原来的DataFrame里面就没有这个sum_Salary。
不过可以使用col进行过滤
使用Sort进行排序
创建DataFrame
val simpleData = Seq(("James","Sales","NY",90000,34,10000), ("Michael","Sales","NY",86000,56,20000),
("Robert","Sales","CA",81000,30,23000),
("Maria","Finance","CA",90000,24,23000),
("Raman","Finance","CA",99000,40,24000),
("Scott","Finance","NY",83000,36,19000),
("Jen","Finance","NY",79000,53,15000),
("Jeff","Marketing","CA",80000,25,18000),
("Kumar","Marketing","NY",91000,50,21000) )
val dataFrame = simpleData.toDF("employee_name","department","state","salary","age","bonus") dataFrame.show()使用sort可以进行排序,看一下示例
val value = dataFrame.sort(dataFrame("department").desc, dataFrame("salary").asc)
value.show()根据department降序排列,salary进行升序排列。

Spark SQL中的Union
union并不会去重,如果模式不同,会报错误
创建两个dataFrame
val simpleData = Seq(("James","Sales","NY",90000,34,10000), ("michael","Sales","NY",86000,56,20000),
("Robert","Sales","CA",81000,30,23000),
("Maria","Finance","CA",90000,24,23000))
val simpleData2 = Seq(("James","Sales","NY",90000,34,10000), ("Maria","Finance","CA",90000,24,23000),
("Jen","Finance","NY",79000,53,15000),
("Jeff","Marketing","CA",80000,25,18000),
("Kumar","Marketing","NY",91000,50,21000) )
val dataFrame2 = simpleData2.toDF("employee_name","department","state","salary","age","bonus")
val dataFrame = simpleData.toDF("employee_name", "department",
"state", "salary", "age", "bonus")上面是两个数据集,可以看到上面的数据集中有两条数据是重复的。
Maria这条记录是重复的,因此如果直接union的话,并不会去重。
val value = dataFrame.union(dataFrame2)
对于重复数据进行去重
val l = dataFrame.union(dataFrame2).distinct()

Map和MapPartitions的例子
Spark 中的map和mappartitions将函数应用于DataFrame/DataSet的每个元素。
Spark中的map()转换将一个函数应用于DataFrame/DataSet中的每一行并返回新的转换后的DataSet。
mapPartitions()这与map完全相同,不同之处在于mapPartitions提供了一种工具为每个分区进行一次繁重的初始化,而不是像map在每一行的DataFrame上进行。
关键点
这两种转换都返回的是DataSet[U]但不返回DataFrame。
为了看清楚map和mapPartitions之间的区别,下面通过一个例子来读懂map和mapPartitions的区别。
创建dataFtame
val structData = Seq( Row("James","","Smith","36636","NewYork",3100), Row("Michael","Rose","","40288","California",4300), Row("Robert","","Williams","42114","Florida",1400), Row("Maria","Anne","Jones","39192","Florida",5500), Row("Jen","Mary","Brown","34561","NewYork",3000) )
val schema = new StructType()
.add("firstname", StringType)
.add("middlename", StringType)
.add("lastname", StringType)
.add("id", StringType)
.add("location", StringType)
.add("salary", IntegerType)
val dataFrame = sparkSession.createDataFrame(sparkSession.sparkContext.parallelize(structData), schema)
dataFrame.printSchema()
dataFrame.show()首先创建一个Util类,里面有一个方法combine,combine方法可以接受三个参数,然后将这三个参数通过逗号分隔符组合起来。下面来看一下Util类
class Util extends Serializable{
def combine(fname:String,mname:String,lname:String) = {
fname + "," + mname + "," + lname } }先来讲一下思路,将dataFrame的前三个字段,firstname,middlename,lastname三个字段合在一起。然后将结合起来的字段和id,salary进行合并。
val value = dataFrame.map(row => {
val util = new Util()
val fullName = util.combine(row.getString(0),
row.getString(1),
row.getString(2))
(fullName, row.getString(3), row.getInt(5)) })
val dataFrame1 = value.toDF("fullName", "id", "salary")
dataFrame1.printSchema()创建Util对象,使用combine方法将三个字段合并起来。
然后返回一个元组(结合字段,id,salary)
上面的元组转换成DataFrame
如果使用mapPartitions应该怎么做呢
val value1 = dataFrame.mapPartitions(iter => {
val util = new Util()
val iterator = iter.map(row => {
val str = util.combine(row.getString(0), row.getString(1), row.getString(2))
(str, row.getString(3), row.getInt(5)) })
iterator })mapPartitions是每一个分区里面的数据,装载在迭代器里面,在迭代器里面使用map,对每个迭代器里面的数据进行操作。
总结
有时候 不想自己陷进去,但有时候还是会陷进去,想要独善其身也是需要很大的勇气的。
希望我的她能够每天快乐的生活着,也希望我能给他带来更多的欢乐