目录
2.1 查看CPU信息(cat /proc/cpuinfo)
2.3 超线程(Hyper-Threading,简称”HT”)技术
3.4.1 cpu利用率高是否可以推倒 load 高,答案是不能的。
一、进程状态分析
1.1 查看进程状态PS(process status)
ps aux | grep -i ssh # 查ssh服务的进程常见的参数说明:
-e 列出程序时,显示每个程序所使用的的环境变量
-f 用ASCII 字符显示树状结构,表达程序间的相互关系
-a 显示现行终端机下的所有程序,包括其他用户的程序
-u 以用户为主的格式来显示程序状态
-x 显示所有程序,不以终端机来区分
补充:
① ps 是用来报告程序执行状态的命令,也可搭配kill 指令随时中断、删除不必要的程序
② 使用常用命令,参数无需死记硬背,更多的需要学会查看帮忙(man 命令,如man ps)得以使用
1.2 PS命令中隐含的指标信息

- PID代表启动的顺序,序号越靠前,代表启动的越早
- %cpu使用最大是由CPU的核数*100%决定的
- %MEM 使用物理内存所占比的内存占比(0 < – >100%)
1.3 进程状态介绍
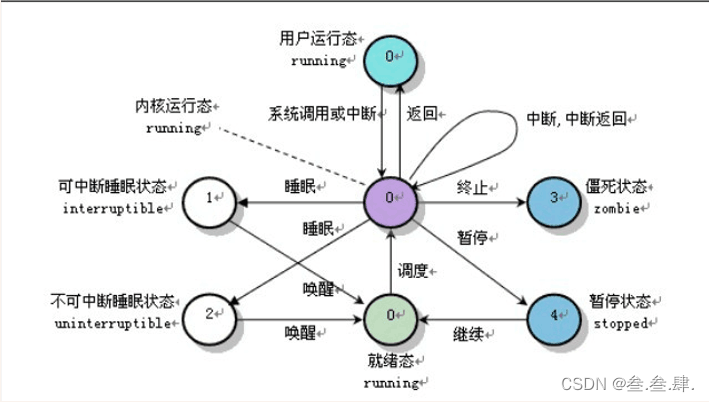
- D 不可中断的睡眠状态【通常作用与IO的进程(IO堵塞)】
-
S 可中断的睡眠状态【处于休眠状态,静止状态】
- 进程运行结束,进入休眠状态,等待唤醒
- 进程休眠,不占用cpu使用时间
-
R 正在运行,或在队列中的进程
- 可执行和等待执行的进程 【当这个值超过了cpu个数,就会出现cpu瓶颈】
- T 停止或被追踪,暂停执行
-
Z 僵死进程不存在但无法消除
- 该进程已经死掉或者已结束,因为父进程一直没有调用该接口或者子进程,使该进程一直没有关闭,僵死状态
- W 进入内存交换 【从内核2.6开始无效】
- X 死掉的进程 【不常见】
可中断睡眠与不可中断的睡眠本质的区别?
- 可中断睡眠可以被强制唤醒,或者绕到其他状态(S –> R —> 其他…)
- 不可中断睡眠已处在事故中,不能强制唤醒(事情处理完后再被唤醒)
1.4 进程状态的调用
1.4.1 时间片(操作系统默认为100ms)
时间片:简单来说就是CPU分配给各个程序的时间,使各个程序从表面上看是同时进行的,而不会造成CPU资源浪费。CPU不可能长时间给某个进程使用,所以系统会设置一个时间。
假如进程切换(process switch) – 有时称为上下文切换(context switch),需要10ms,再假设时间片设为100ms,则在做完100毫秒有用的工作之后,CPU将花费10毫秒来进行进程切换。CPU时间的10%被浪费在了管理开销上。
时间片在抢占式的调度中,优先级高的线程可以从优先级低的线程那里抢占CPU,在抢占的过程中也会消耗CPU时间。
时间片的两种情况:
1、时间片用完了
- 会出现进程上下文切换的原因
- 在cpu时间片到了,进程没执行完(为上文,数据保留),等待下一次调度(下文)
- 进程状态从 R —>> S
2、时间片抢占
- 优先级高的进程抢占时间片,导致优先级低的进程从 就绪态(running)—>睡眠状态
优先级的多少,就决定了占用CPU时间的多少(优先级高,占用的时间就多)
1.4.2 进程状态数据采集
编写执行脚本 a.sh,如下:
vim a.sh
#! /bin/bash
echo 1;
wq执行命令:
while true ; do ./a.sh ; done另开一个终端,执行:
ps aux | grep a.sh
结论1:
取得这一瞬间的快照,没有grep到值(sleep时间太短),执行完就立马消亡了
案例1(采集进程状态的转变2):
执行文件改为:
#! /bin/bash
while true; do
echo 1;
done; # 该文件会一直被执行
结论2:
通过循环,来加大采样频率,这样才有机会采样的到进程的状态数据
1.4.3 查看进程的执行时间
vim 2.sh#! /bin/bash
for((i=1;i<=3;i++)); do
sleep 1
echo $i
donetime ./2.sh # 获取 2.sh 应用程序执行的时间信息

real 0m0.001s 进程消耗时间
cpu时间(cpu时间:user+sys消耗时间)
user 0m0.000s 进程用户态cpu时间
sys 0m0.000s 进程内核态cpu时间
-
进程消耗时间与cpu时间的关系(不同情况下,不同分析)
- 单核:进程执行时间 >=cpu时间
- 多核:如果进程只占用了1个cpu(进程执行时间 >= cpu时间),如何进程占用了多核cpu(进程执行时间 >=< cpu时间都可能出现)
结论:假设进程a占用了27个core,每个core使用cpu时间0.1s,这个进程执行了1s,那么进程执行时间 1s, cpu时间为27*0.1=2.7s
1.4.4
查看进程的开始、持续与结束时间
案例演示: 1. 一端执行top 命令 2.另一端执行ps命令数据的采集,如下命令:
while true; do ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,etime,time,user,uid' | grep top ; sleep 1; echo ; done
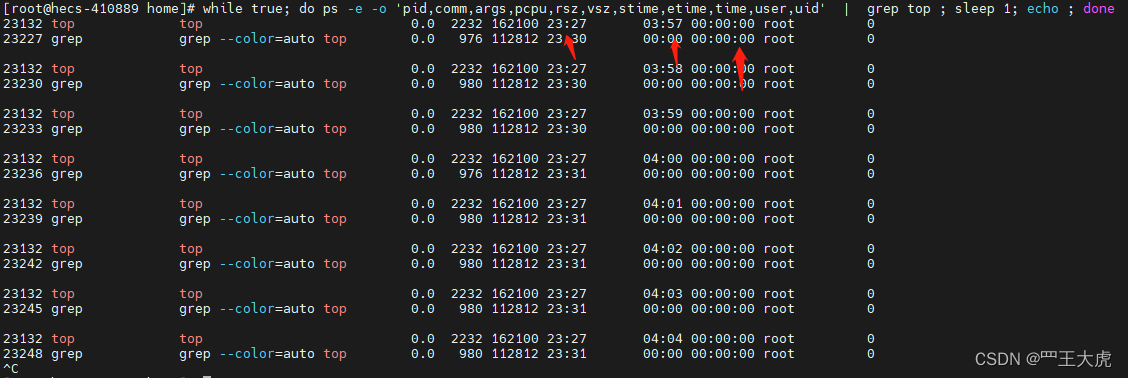
stime : 什么时间点启动的(表示进程开始的时间)
etime : 当前时间-开始时间(表示进程存活的时间)
time:表示进程从启动开始到现在消耗的cpu时间(user+sys)
-
sys(内核态)表示应用程序在系统调用,调用接口消耗的cpu
- 看system call interface层(接口调用)和system libraries 层(系统调用)
-
软件与硬件的调用关系
-
硬件 <<—-内核 <<—–软件程序 【软件程序通过内核来调用硬件】
- 软件程序所消耗的CPU为用户层,内核调用硬件所消耗的CPU为内核层
-
硬件 <<—-内核 <<—–软件程序 【软件程序通过内核来调用硬件】
操作系统如何调用硬件分层?
【上层为软件或者程序,底层为硬件】
- 程序要调用硬件,要通过内核来调用硬件(损耗算在了用户层)
- 内核会提供一些接口(损耗算在了内核层)
time +有值,表示一定有使用过cpu(有值说明程序一定调用过内核或者接口)
ps命令中的 time 与 top命令中的time+ 的区别?
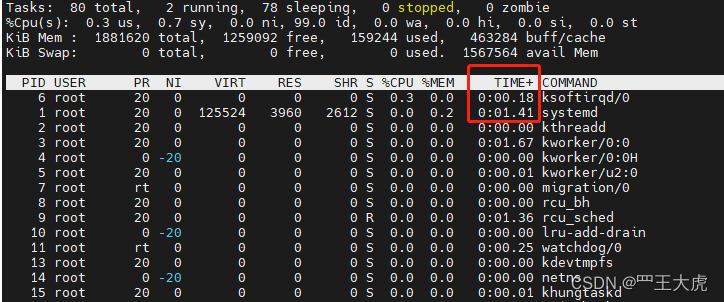
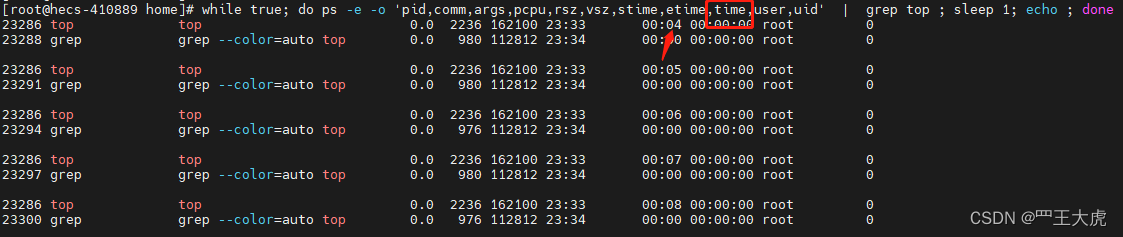
- ps time 是秒级的单位 而 top time+ 是0.01秒级的单位
- 表示进程从启动开始到现在消耗的cpu时间
1.4.5 进程优先级
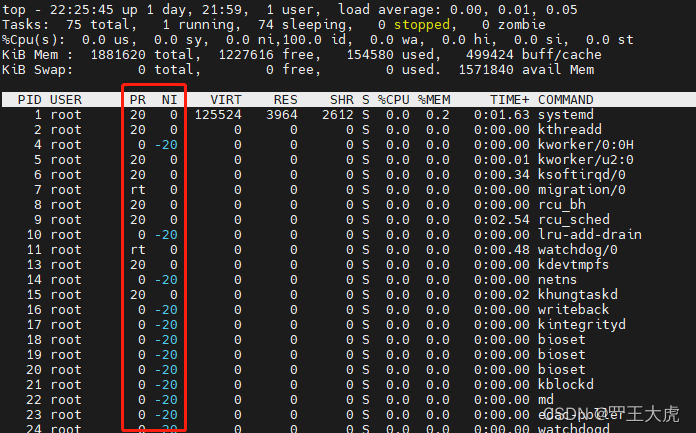
主要通过top命令中的ni 值来查看进程的优先级。优先级(priority)为操作系统用来决定CPU分配的参数,linux 使用[回合制(round-robin)]的演算法来做CPU排程,优先序越高,所可能获得的CPU时间就越多。
我们可以通过nice命令以更改过的优先序来执行程序,如果未指定程序,则会印出目前的排程优先序,内定的adjustment 为10,范围为-20(最高优先序) 到 19(最低优先序),进程默认优先级为0
NI 越小(-20)优先级越高,时间片更多(最终都是为%cpu服务的)
PR 为实时优先级。0 ~ 99,默认20,PR 与NICE结合来看进程的优先级
nice -n 1 ls # 将ls的优先级加1,并执行
进程上下文切换的原因 ?
- cpu时间是100ms,这个进程就只能用100ms来执行代码,没执行完,要把程序数据的上下文保留着,等待下次唤醒执行,再次上下文切换(R状态变更为S状态,等待再次被唤醒)
- 所以当进程被抢占,调度内存或cpu 不够,就会发生频繁的上下文切换
-
为什么没执行完的原因?【取决于调度状态怎么发生变更】
- 正常时间片用完或被抢占,没执行完,变成睡眠状态
- 强制破坏的那种,状态就变成暂停
二、CPU使用分析
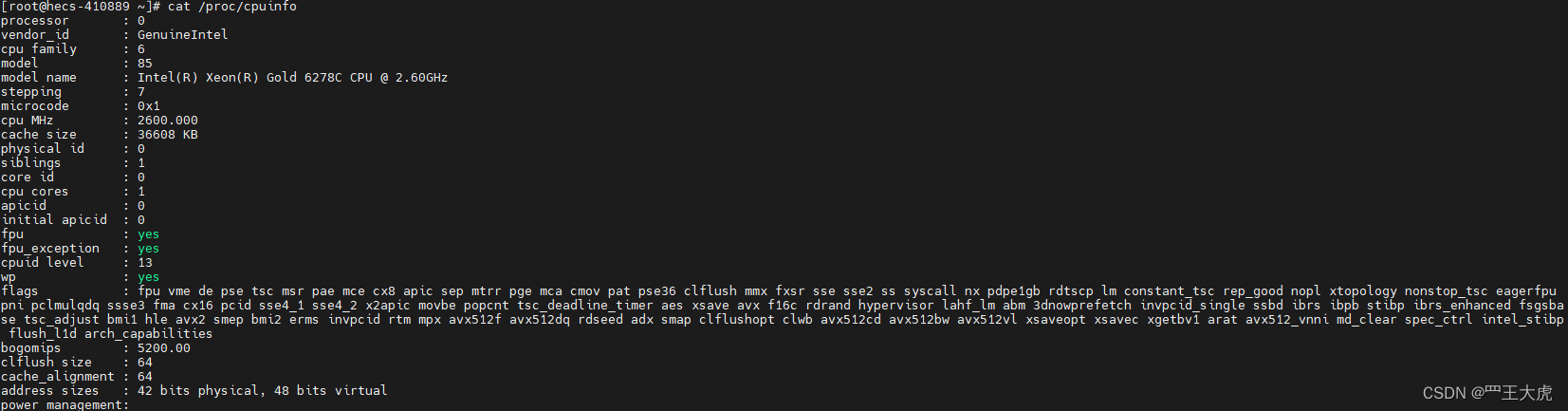
2.1 查看CPU信息(cat /proc/cpuinfo)
-
rpm i386 i586 i686之间的区别?
- 取决于cpu型号【cpu family】
-
查有几个核心cpu?
- cat /proc/cpuinfo | grep processor | wc -l
2.2 cpu封装
-
processor:逻辑处理器的唯一标识符(cpu) 【processor有几个,代表cpu有几个】
- cpu的核数由processor决定
- physical id:物理处理器的唯一标识符(物理封装cpu)
- core id:条目保存每个内核的唯一标识符(核心) 【表示整个系统里有几个core】
- cpu cores:表示一个物理cpu有几个core
- siblings:表示一个物理cpu 有几个processor
- 超线程技术【硬件换效率,1个core有两个processor 并不等于 1+1 =2,目的是大于1】
2.3 超线程(Hyper-Threading,简称”HT”)技术
超线程(Hyper-Threading,简称”HT”)技术就是利用特殊的硬件指令,把两个逻辑内核模拟成两个呃呃物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的空闲时间,提高了CPU的运行效率。
2.3.1 为什么说超线程的性能并不等于两颗CPU的性能?
超线程技术是在一颗CPU同时执行多个线程而共同分享一颗CPU内的资源,理论上要像两颗CPU一样在同一时间执行两个线程。因每个CPU都具有独立的资源,当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,知道这些资源闲置后才能继续,因此超线程的性能并不等于两颗CPU的性能。
如果”siblings” 是 “cpu cores “的两倍,则说明支持超线程,并且超线程一打开。
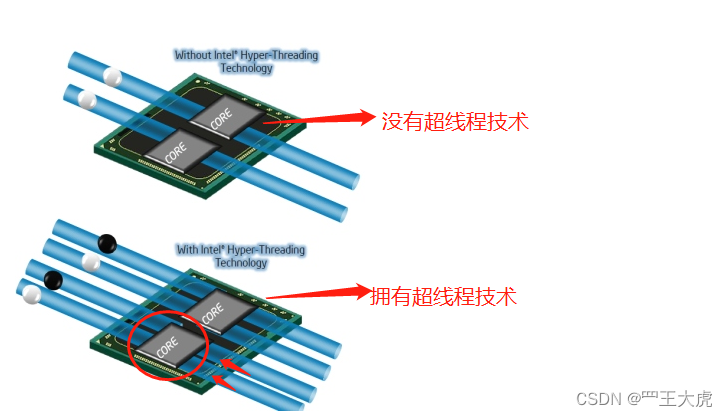
2.3.2 如何判断CPU是否拥有超线程技术?
-
超线程技术取决于,一个core id 上面有几个processor
- 同一个物理封装,同一个core id 下,有两个processor,说明支持超线程技术
-
core id 查看是否有超线程技术(0,1)
- 一个核心上封装2个通道
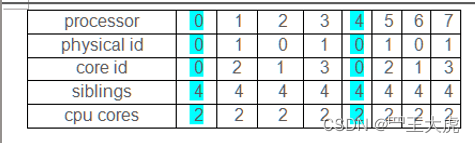
如上图,physical id =(0,1)说明有2颗物理CPU,每颗物理CPU有4个逻辑处理器。每颗物理CPU对应的逻辑处理器为(0,2,4,6) (1,3,5,7),所以上图的CPU构成是拥有超线程技术8核CPU。
举例不拥有超线程技术的案例,如下图:

如上图,physical id =(0),说明有1颗物理CPU(没有超线程技术),1颗物理CPU有4个逻辑处理器(0,1,2,3),只是单纯的4核CPU。
三、CPU负载分析
3.1 进程系统负载模型
有一个形象的例子可以说明系统负载模型,即”交通拥堵模型”
- 车道数(8车道,还是2车道) —-> cpu 核数
- 车流量(车流量大不大) —-> 进程数
- 交通状况(行驶中,是否存在事故车辆) —-> 系统负载长度(R+D)
- 红绿灯&限速(限速20KM,还是120KM。有无红绿灯) —-> 进程运行时间
3.2 系统负载(cat /proc/loadavg):
过去1分钟,5分钟,15分钟内的平均负载。说明:过去,不能表示实时负载,不能拿过去忙,推现在忙。不能那过去平均,推当下平均
举例分析(load average 2,10,50):
2,10,15强调的趋势,过去平均一分钟,不是这一刻的,强调的是趋势的概念,不能拿平均推实时,趋势推实时,这是有问题的。
- 过去5分钟平均负载为10: 假设每1分钟为1,则可以分为5段
- 过去1分钟按比例为1,(1-5] 为X,总共5段的负载为10*5 =50。所以(1-5]的负载,应该是 50-2 =48(2为第一分钟时的负载),换算到每分钟应该是 48/4 =12(每分钟平均负载为12)
- 同理,15分钟,换算到每分钟的话,应该是50 *15 =750(瞬时,50为第5分钟时的负载),而前面5分钟的负载长度为10*5 =50。(5-15] 的负载,应该是 750 -50 =700,换算到每分钟应该是 (750-50)/(15-5)=70 ,推导出,平均每分钟负载为70

都是平均值,所以只能从平均上来说,过去多少时间到多少时间,他是繁忙、忙、不忙,只能从趋势来说。负载是下降的。
实时的含义(当前负载): 0-60s —》10s前才压测结束,压力是在逐级递减
- loadavg 是过去1,5,15的平均负载,当衡量实时只做辅助,还需看 vmstat, cat /proc/loadavg
- 平均和实时的差异性,需要多采样来分析趋势
- 趋势 + 实时结合起来分析( top + vmstat命令)
cpu负载推导公式 适用于 load average 1,5,15分钟不同阶段的忙与不忙的情况,最多只是反映一种趋势。
3.
3 判断CPU负载忙与不忙
根据经验值,得出如下公式:
- 0.7 * processor > load ok 不忙
- 1 * processor < load < 3 * processor 还要参考这些数据(cpu 内存 网络 IO)才能决定是否忙
- load > 5 * processor 负载长度有点高
公式推导的几个思路:
- 知道 loadavg 值得来历。假设过去1分钟内,每秒的R+D的进程个数是2 —》 那么他过去1分钟的平均负载一定是2
- 进程需要cpu去处理的,cpu能处理过来,就说明系统不忙
案例分析:
top - 07:40:57 up 25 min, 2 users, load average: 50, 50, 50-
4 processor ? 是否忙?
- 0.7 * processor = 2.8 < 50 【结论 : 系统很忙】
-
32 processor? 是否忙?
- 1 * processor = 32 3 * processor =96 【值介于两者之间】
- 还需要参考cpu、内存、网络、IO来决定是否忙,如有这些指标,也能分析系统是否忙
现假设你有16 processor 的cpu,如何定义负载繁忙的阈值?【每个公司的阈值不一样高,所以系数会调整】
- 0.7 * 16 = 11.2 —->> 那么load 小于 11.2的时候,肯定不忙
- 值介于16 – 48之间,还要参考其他指标【cpu、内存、网络、IO】
- 【80】 以上的肯定忙
通过拿到过去(过去5分钟,15分钟)的负载,我们能得到什么结论?
- 主要是一个趋势分析
- 可以画出过去15分钟的平均负载的趋势图【过去的负载,主要是用来作为分析用的】
- 过去的负载可以作为借鉴,因为压测是一个持续的过程
load average这个值是用过去一分钟的值,还是五分钟、十五分钟的值呢?
- 过去1分钟更具有实时性
- 优先看过去1分钟的负载情况
cat /proc/loadavg 查看负载信息中的进程总数,具体指哪些状态的进程?
R + D 状态的进程(不包括sleeping状态)
3.
4 load 高和 cpu 利用率高之间的关系
3.
4.1 cpu利用率高是否可以推倒 load 高,答案是不能的。
栗子:
如下情况,2个进程用了32core,CPU使用率、系统负载是高还是低?
从CPU利用率的角度,很高。但从系统负载来说,不高【1 * processor = 32 > 2】
又如下情况来说明两者没有必然的关系:
- 从这个角度,top —->load average 1.72,1.93,1.36 推导出系统负载不高
- 从另一个角度,top — >84.6 %us 4.7%sy 8.5 %id 推导出cpu利用率很高【CPU利用率 = 1 – %id = 91.5%】
为什么会出现上述的情况呢?
从CPU负载长度来分析,负载长度包括 R + D状态的进程,目前如果一个进程占用了大量CPU【如Java进程占用 1276% mysql 进程占用了943.1%】,2个进程加起来共占用约22个cpu。
一般说,20几个进程说明负载很忙,但现在2个进程就干了人家20几个进程的活,所以推导不出CPU利用率高,就说明load高
负载统计的是进程R+D的个数,但是有可能是某个进程占用了大部分的CPU,所以负载小,资源利用率确很高
3.
4.2 load 高也无法推导出cpu利用率就高
如:单个进程占cpu 1% – 2% , loadavg 128 , 那么CPU总共才占12.8 % cpu【需要考虑CPU的核心数】,每个进程几乎不怎么消耗cpu
3.
4.3 load 高 ,cpu 高 ,进程多之间的关系
load 高只能推导进程多,是否就因此导致CPU高,需要具体问题具体分析。两者不能相互推导。
结论:负载只是表示当前系统的繁忙程度,CPU利用率和负载没有太大的关联,负载多了会影响系统处理,变慢。因为它在不断的进行上下文切换。
3.
4.4 load负载低,cpu 很高,怎么进行分析?
- 先top 一下,看cpu 在被什么占用(比如us 用户态大量占用)
- 查看占用最高的进程是什么,对这个进程进行分析
- 可以用 strace -f -tt -p 3237(进程号) 进入进程里面,打印出对应进程处理事件的信息,从对应的时间与信息可以看到,那一块耗的时间比较长,进程在进行什么什么调用,导致了这个问题
- 看代码跟什么调用有关系,影响了进程
什么情况下会出发中断,上下文切换?
- 进程会向cpu 申请调度的时间片,时间片运行完,会进行上下切换
- 进程会有抢占,会触发中断 和 进程的上下文切换
3.
4.4 CPU使用公式
- CPU使用率 = 1 – id%
- 闲置cpu = id%
3.
4.5 CPU阈值
设置阈值的目的,是要保证有一定的余地。没有绝对的50,70,90的概念,需要结合服务器的核心数(processor)来合理给出预设的阈值。
以4core 的cpu机器为例:CPU>=50%注意 、CPU>=70% 警告、CPU>=90%严重警告
但是否以上的阈值可以完全套用呢,答案又完全不是,如下对比即可说明:
4 core 200% 200% 预留2core保底
32 core 1600% 1600% 预留16core保底
64 core 3200% 3200% 预留32core保底
这样设置存在严重的cpu浪费,只要预留相对应的核数即可。
多少个核数,多少的cpu利用率来做阈值定义会好一些,如警告阈值为70%,假设 4core,那么应保留 400 *30% =120。1.2core的cpu 作为预警阈值比较合理。
假设 32core ,就不应该是 70%了,可能是80%、90%、95%甚至更多【以4核数据为基础,根据不同的情况来分析定义,不然就是对cpu的浪费】
CPU阈值推导思路(以2core为推导基础):
- 假设测试环境:2core 50%(至少空100%) 、70%(至少空60%)、90%(至少空20%)
-
推倒到正式环境:4core (400-100)/400=75%(可多预留5-10%)、340/400=85%、380/400=95
- 为什么多预留5%-10%,因为是理论推导出来的,多预留一点是可以接受的
- 推倒到正式环境:32core (3200-200)/3200 = 93% (93预警,系统还是安全的)、 (3200-160)/3200 = 95%(警告)、 (3200-120)/3200 =96 %(严重警告)
3.
5 详解top命令,对进程进行cpu使用率的分析

第一行:
top – 17:28:44:当前时间 up 2 days, 17:02:系统运行时间 1 user:当前登录用户数
load average: 0.00, 0.01, 0.05:系统负载平均长度
第二、三行,为进程和CPU的信息
Tasks: 75 total, 1 running, 74 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
- %us:用户态所消耗的cpu利用率
- %sy:内核态所消耗的cpu利用率
- %ni :应用程序通过调整进程的优先级,所消耗的cpu
- %wa:IO等待所使用的cpu利用率
- %hi :硬件中断所使用的cpu利用率(硬中短)
- %si:软件中断所使用的cpu使用率(软中断)
-
%st:使用的是虚拟机,需要注意的指标
- 如宿主机(a,b,c三台虚拟机),a比较忙,bc比较空闲
- %st忙的时候,虚拟机资源被同一个物理机下其他虚拟机抢占了(a抢占了bc机的资源),是别的虚拟机抢占了cpu资源,此时在top命令下 st 才会有数值
各项指标异常,都是先找进程,把进程从高到低进行排序,都会反映到%CPU上。只是拿到进程后根据具体哪个指标高,再具体分析哪个指标,比如hi高,先分析中断的原因。
第四行为内存信息(free)
Mem : 1881620 total:物理内存总量
1210072 free:空闲内存
154660 used:使用的物理内存总量
516888 buff/cache:缓存/缓冲的交换区内存量
KiB Swap: 0 total:交换区内存总量

第六七行为进程信息(ps aux)
3.5.1 关于软件中断(%si)
CPU使用率过高的时候,表示当前软中断占用很大的百分比,关于软中断的统计没有明确的统计文件定义,一般需要程序员设计中断的时候进行统计,参考文件/proc/net/softnet_stat,以及查看当前哪些进程和服务所占用的CPU较高,可以通过设置 top f 显示当前进程的CPU信息,检查进程所做的操作,如处理网络的报文,长时间的写日志等等,都会产生软中断。
网卡中断使用的cpu:从网卡过来的数据包多(收发包多) ,需要我们去找网络收发包的进程
软件中断:软件收、发包,这样的动作,系统要处理这些动作,就会触发软件中断
%si高的情况下,先找进程,把进程从高到低排序,看下这些进程为什么占用si比较高
恶意攻击是不是会使si% 比较高?
看它是否有到内核层,到达内核层才会触发软件中断。有些攻击是直接被网卡给过滤掉了。
3.5.2 关于硬件中断(%hi)
%hi 的使用率过高时,表示当前硬件中断占用很大的百分比,一般硬件中断我们可以分析文件/proc/interrupts,/proc/irq/1/smp_affinity,服务irqbalance是否配置,以及cpu的频率设置。
如果hi% 使用率比较高(硬件中断比较高),怎么分析?
- 通用的方法,先找hi 高所占用的进程(如 mysql 进程占的cpu 比较高)
- dump 进程信息,找到消耗哪些中断,对这些中断进行分析(Java进程用 top -H -p,jmap, jstack等命令)
先找进程,找到cpu占用高,然后去分析这些进程信息,不管什么原因引起的cpu高,都这么去分析
3.5.3 查看进程硬件中断使用的cpu
看中断技术,查硬件中断的信息会写到interrupts文件里,执行以下指令
cat /proc/interrupts > hi1.txt ; sleep 2; cat /proc/interrupts > hi2.txt
vimdiff hi1.txt hi2.txt #将硬件中断的信息写到文件里,在对文件进行对比分析- 比较2秒前后之前的差异,来判断中断的次数
- 判断哪个进程中断多一些,将所有cpu的中断次数相加,在进行比较


cat /proc/stat #该文件包含了某一进程所有的活动的信息
interrupts #硬件中断文件
跟硬件有关的东西,产生的硬件中断。键盘输入指令,就会产生一次硬件中断
如:键盘随时等着输入东西,输完以后,触发一个硬件中断,底层协议栈才知道把这个东西input ,给打进我们的程序里面,鼠标输入也是如此。
vim hi1.txt -- i -- vsplit hi2.txtTOP命令发现%hi消耗cpu比较多,怎么找具体的中断源?
找到中断号922,在eth1消耗比较多,在分析中断号922与网卡怎么打交道的,什么操作导致中断多。
3.5.4 nginx亲和能力的打散(负债均衡)
- cpu的亲和文件 smp_affinity
-
打散
- 比如将中断号17打散到各颗cpu,人为指定cpu —>cat /proc/irq/17/smp_affinity
- 如 要将中断号17(八进制)打散到cpu 0 cpu 1 cpu 2 cpu 3 转化为对应的二进制为”0000 1111″,转化为十六进制为”F”,输入:
"echo "F" > /proc/irq/17/smp_affinity #将中断号17打散到cpu 0 1 2 3上面去
3.
5.5 TOP数据采集
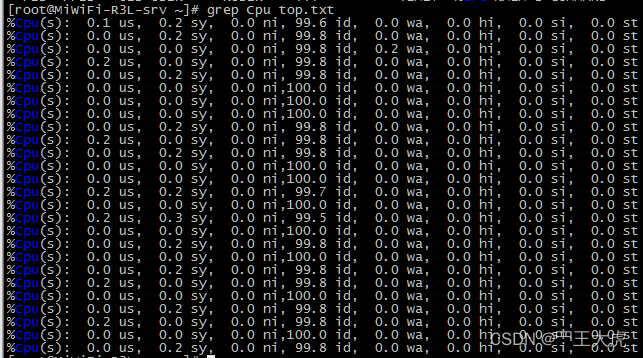
top -b -d 3 > top.txt # 每3秒采集一次top 的数据,保存到top.txt文件里
cat top.log | grep ‘Cpu’ 或 grep Cpu top.txt | sed “s|\%\([a-z]\)\([a-z]\)\,||g” # 获取cpu的数据信息
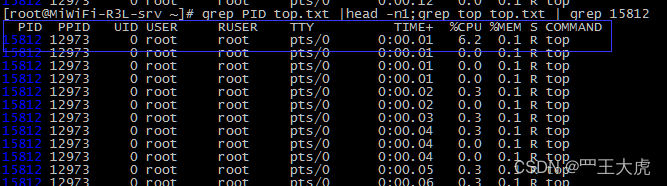
grep top top.txt | grep 15812 # 获取进程的数据信息

grep出来的数据没有标题,不好分析,可以通过以下的命令进行标题的补全:
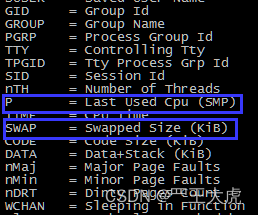
echo “PID USER PR NI VIRI RES SHR S %CPU %MEM TIME+ PPID GROUP SWAP TIME COMMAND”;grep top top.txt | grep 15812

grep PID top.txt |head -n1;grep top top.txt | grep 15812 # 取关键字第一行数据+ grep 15812进程数据,效果比上一条更明了简洁
top使用技巧:
按数字1,显示平均或者每个cpu信息。当机器的核数太多,按1显示不全,可以使用 mpstat 1(sar -u 1)查看cpu信息
top常用操作配置:
- 进入top 按 h 进入帮助界面
-
常用的参数配置
- f,o (小写) — f,增加显示字段
- F,O (大写) — F,按某个字段排序
- d,s — 刷新数据采集的时间间隔
- W — 写配置文件
top 页面 —>d —>1 (把默认刷新的时间3s 改成了1s) —> W 保存设置
top页面 —> f —-> 选中 *swap(top页面新增swap 列字段) —> W 保存设置